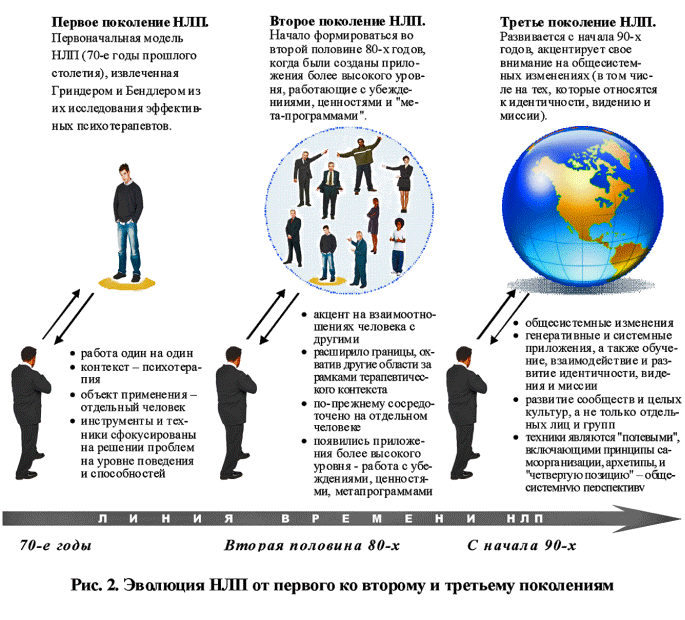
NLP (Natural Language Processing) — обработка естественного языка
NLP (Natural Language Processing, обработка естественного языка) — это направление в машинном обучении, посвященное распознаванию, генерации и обработке устной и письменной человеческой речи. Находится на стыке дисциплин искусственного интеллекта и лингвистики.
Инженеры-программисты разрабатывают механизмы, позволяющие взаимодействовать компьютерам и людям посредством естественного языка. Благодаря NLP компьютеры могут читать, интерпретировать, понимать человеческий язык, а также выдавать ответные результаты. Как правило, обработка основана на уровне интеллекта машины, расшифровывающего сообщения человека в значимую для нее информацию.
Процесс машинного понимания с применением алгоритмов обработки естественного языка может выглядеть так:
- Речь человека записывается аудио-устройством.

- Система NLP разбирает текст на составляющие, понимает контекст беседы и цели человека.
- С учетом результатов работы NLP машина определяет команду, которая должна быть выполнена.

Подробнее
Приложения NLP окружают нас повсюду. Это поиск в Google или Яндексе, машинный перевод, чат-боты, виртуальные ассистенты вроде Siri, Алисы, Салюта от Сбера и пр.
Технологии NLP используют как в науке, так и для решения коммерческих бизнес-задач: например, для исследования искусственного интеллекта и способов его развития, а также создания «умных» систем, работающих с естественными человеческими языками, от поисковиков до музыкальных приложений.
Раньше алгоритмам прописывали набор реакций на определенные слова и фразы, а для поиска использовалось сравнение. Это не распознавание и понимание текста, а реагирование на введенный набор символов. Такой алгоритм не смог бы увидеть разницы между столовой ложкой и школьной столовой.
NLP — другой подход. Алгоритмы обучают не только словам и их значениям, но и структуре фраз, внутренней логике языка, пониманию контекста. Чтобы понять, к чему относится слово «он» в предложении «человек носил костюм, и он был синий», машина должна иметь представление о свойствах понятий «человек» и «костюм».
Распознавание речи. Этим занимаются голосовые помощники приложений и операционных систем, «умные» колонки и другие подобные устройства. Также распознавание речи используется в чат-ботах, сервисах автоматического заказа, при автоматической генерации субтитров для видеороликов, голосовом вводе, управлении «умным» домом. Компьютер распознает, что сказал ему человек, и выполняет в соответствии с этим нужные действия.
Обработка текста. Человек может также общаться с компьютером посредством письменного текста. Например, через тех же чат-ботов и помощников. Некоторые программы работают одновременно и как голосовые, и как текстовые ассистенты. Пример — помощники в банковских приложениях. В этом случае программа обрабатывает полученный текст, распознает его или классифицирует.
Извлечение информации. Из текста или речи можно извлечь конкретную информацию. Пример задачи — ответы на вопросы в поисковых системах. Алгоритм должен обработать массив входных данных и выделить из него ключевые элементы (слова), в соответствии с которыми будет найден актуальный ответ на поставленный вопрос. Для этого требуются алгоритмы, способные различать контекст и понятия в тексте.
Анализ информации. Это схожая с предыдущей задача, но цель — не получить конкретный ответ, а проанализировать имеющиеся данные по определенным критериям. Машины обрабатывают текст и определяют его эмоциональную окраску, тему, стиль, жанр и др. То же самое можно сказать про запись голоса.
Анализ информации часто используется в разных видах аналитики и в маркетинге. Например, можно отследить среднюю тональность отзывов и высказываний по заданному вопросу. Соцсети используют такие алгоритмы для поиска и блокировки вредоносного контента. В перспективе компьютер сможет отличать фейковые новости от реальных, устанавливать авторство текста. Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.
Соцсети используют такие алгоритмы для поиска и блокировки вредоносного контента. В перспективе компьютер сможет отличать фейковые новости от реальных, устанавливать авторство текста. Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.
Генерация текста и речи. Противоположная распознаванию задача — генерация, или синтез. Алгоритм должен отреагировать на текст или речь пользователя. Это может быть ответ на вопрос, полезная информация или забавная фраза, но реплика должна быть по заданной теме. В системах распознавания речи предложения разбиваются на части. Далее, чтобы произнести определенную фразу, компьютер сохраняет их, преобразовывает и воспроизводит. Конечно, на границах «сшивки» могут возникать искажения, из-за чего голос часто звучит неестественно.
Генерация текста не ограничивается шаблонными ответами, заложенными в алгоритм. Для нее используют алгоритмы машинного обучения. «Говорящие» программы могут учиться на основе реальных данных. Можно добиться того, чтобы алгоритм писал стихи или рассказы с логичной структурой, но они обычно не очень осмысленные.
Для нее используют алгоритмы машинного обучения. «Говорящие» программы могут учиться на основе реальных данных. Можно добиться того, чтобы алгоритм писал стихи или рассказы с логичной структурой, но они обычно не очень осмысленные.
Автоматический пересказ. Это направление также подразумевает анализ информации, но здесь используется и распознавание, и синтез.Задача — обработать большой объем информации и сделать его краткий пересказ. Это бывает нужно в бизнесе или в науке, когда необходимо получить ключевые пункты большого набора данных.
Машинный перевод. Программы-переводчики тоже используют алгоритмы машинного обучения и NLP. С их использованием качество машинного перевода резко выросло, хотя до сих пор зависит от сложности языка и связано с его структурными особенностями. Разработчики стремятся к тому, чтобы машинный перевод стал более точным и мог дать адекватное представление о смысле оригинала во всех случаях.
Машинный перевод частично автоматизирует задачу профессиональных переводчиков: его используют для перевода шаблонных участков текста, например в технической документации.
Алгоритмы не работают с «сырыми» данными. Большая часть процесса — подготовка текста или речи, преобразование их в вид, доступный для восприятия компьютером.
Очистка. Из текста удаляются бесполезные для машины данные. Это большинство знаков пунктуации, особые символы, скобки, теги и пр. Некоторые символы могут быть значимыми в конкретных случаях. Например, в тексте про экономику знаки валют несут смысл.
Препроцессинг. Дальше наступает большой этап предварительной обработки — препроцессинга. Это приведение информации к виду, в котором она более понятна алгоритму. Популярные методы препроцессинга:
- приведение символов к одному регистру, чтобы все слова были написаны с маленькой буквы;
- токенизация — разбиение текста на токены.
- тегирование частей речи — определение частей речи в каждом предложении для применения грамматических правил;
- лемматизация и стемминг — приведение слов к единой форме. Стемминг более грубый, он обрезает суффиксы и оставляет корни. Лемматизация — приведение слов к изначальным словоформам, часто с учетом контекста;
- удаление стоп-слов — артиклей, междометий и пр.;
- спелл-чекинг — автокоррекция слов, которые написаны неправильно.

Методы выбирают согласно задаче.
Векторизация. После предобработки на выходе получается набор подготовленных слов. Но алгоритмы работают с числовыми данными, а не с чистым текстом. Поэтому из входящей информации создают векторы — представляют ее как набор числовых значений.
Популярные варианты векторизации — «мешок слов» и «мешок N-грамм». В «мешке слов» слова кодируются в цифры. Учитывается только количество слова в тексте, а не их расположение и контекст. N-граммы — это группы из N слов. Алгоритм наполняет «мешок» не отдельными словами с их частотой, а группами по несколько слов, и это помогает определить контекст.
Применение алгоритмов машинного обучения. С помощью векторизации можно оценить, насколько часто в тексте встречаются слова. Но большинство актуальных задач сложнее, чем просто определение частоты — тут нужны продвинутые алгоритмы машинного обучения. В зависимости от типа конкретной задачи создается и настраивается своя отдельная модель.
Алгоритмы обрабатывают, анализируют и распознают входные данные, делают на их основе выводы. Это интересный и сложный процесс, в котором много математики и теории вероятностей.
Что такое NLP: история, терминология, библиотеки
Обработка естественного языка Natural language processing (NLP) – это сфера искусственного интеллекта, которая занимается применением алгоритмов машинного обучения и лингвистики для анализа текстовых данных. Цель NLP – понимание и воспроизведение естественного человеческого языка.
Цель NLP – понимание и воспроизведение естественного человеческого языка.
История
В 1954 году IBM проводит исследование в области машинного перевода с русского на английский (Джорджтаунский эксперимент) [1]. Система, которая состояла из 6 правил, перевела 60 предложений с транслитерированного (записанным латинским алфавитом) русского на английский. Авторы эксперимента заявили, что проблема машинного перевода будет решена через 3-4 года. Несмотря на последующие инвестиции правительства США прогресс был низкий. В 1966 году после отчета ALPAC о кризисе в машинного перевода и вычислительной лингвистики поток инвестиций уменьшается.
В 60-xх появилась интерактивная система с пользователем — SHRDLU [2]. Это был парсер с небольшим словарем, который определяет главные сущности в предложении (подлежащее, сказуемое, дополнение).
В 70-х годах В. Вудс предлагает расширенную систему переходов (Augmented transition network) — графовая структура, использующая идею конечных автоматов для парсинга предложений [3].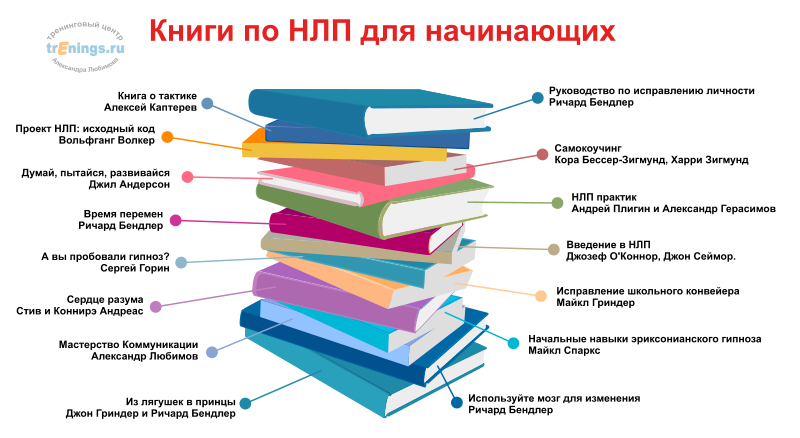
После 80-хх для решения NLP-задач начинают активно применяться алгоритмы машинного обучения (Machine Learning). Например, одна из ранних работ опиралась на деревья решений (Decison Tree) для получения создания системы с правилами if-else. Кроме того, начали применяться статистические модели.
В 90-х годах стали популярны n-граммы [3]. В 1997 году была предложена модель LSTM (Long-short memory), которая была реализована на практике только в 2007 [4]. В 2011 году появляется персональный помощник от Apple — Siri. Вслед за Apple остальные крупные IT-компании стали выпускать своих голосовых ассистентов (Alexa от Amazon, Cortana от Microsoft, Google Assistant). В этом же году вопросно-ответная система Watson от IBM победила в игре Jeopardy!, аналог «Своей игры», в реальном времени [5].
На данный момент благодаря развитию Deep Learning, появлению большого количества данных и технологий Big Data методы NLP применяются во многих задачах, начиная от распознавания речи и машинного перевода, заканчивая написанием романов [6].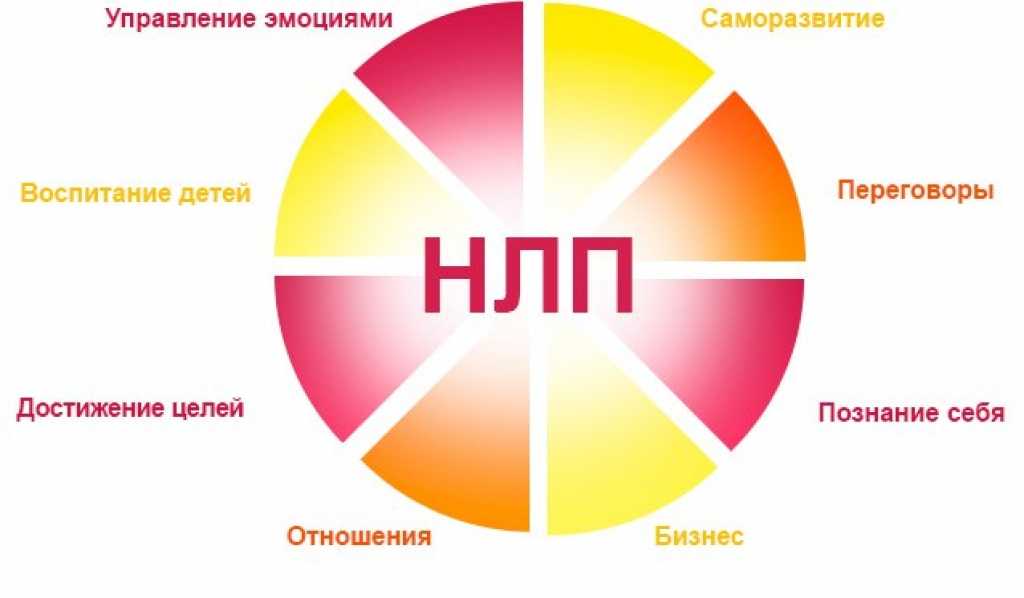
Терминология NLP
- Токен— текстовая единица, например, слово, словосочетание, предложение и т.д. Разбиение текста на токены называется токенизацией.
- Документ– это совокупность токенов, которые принадлежат одной смысловой единице, например, предложение, абзац, пост или комментарий.
- Корпус– это генеральная совокупность всех документов.
- Нормализация— приведение слов одинакового смысла к одной морфологической форме. Например, слово хотеть в тексте может встречаться в виде хотел, хотела, хочешь. К нормализации относится стемминг и лемматизация.
- Стемминг— процесс приведения слова к основе. Например, хочу может стать хоч. Для русского языка предпочтительней лемматизация.
- Лемматизация— процесс приведения слова к начальной форме. Слово глотаю может стать глотать, бутылкой — бутылка и т.д. Лемматизация затратный процесс, так как требуется работать со словарем.
- Стоп-слова— те слова, которые не несут информативный смысл. К ним чаще всего относятся служебные слова (предлоги, частицы и союзы).
 Слово глотаю может стать глотать, бутылкой — бутылка и т.д. Лемматизация затратный процесс, так как требуется работать со словарем.
Слово глотаю может стать глотать, бутылкой — бутылка и т.д. Лемматизация затратный процесс, так как требуется работать со словарем.ML-библиотеки для обработки естественного языка
- pymorphy2— морфологической анализатор для российского и украинского текстов. В нем присутствует лемматизатор.
- PyMystem3— аналог pymorhy2 от Яндекса.
- nltk— большой инструмент для работы с текстами. Предоставляет токенизатор, лемматизатор, стемминг, стоп-слова (в том числе и для русского языка).
- spacy— аналог nltk, но многие функции работают быстрее. Также как и nltk, плохо работает с русским языком. Однако, могут использоваться специальные модели ru2 или spacy russian—tokenizer.
- scikit—learn— самая популярна библиотека машинного обучения, которая также пересоставляет способы обработки текстов, например, TF—IDF.
- gensim— библиотека предоставляет методы векторизации слов.
- deeppavlov— фреймфворк для разработки чатботов и персональных помошников.
- yargy— парсер для извлечения сущностей в текстах на русском языке.
Подробнее про обработку текста читайте в нашей отдельной статье «4 метода векторизации текстов».
Источники
- https://ru.wikipedia.org/wiki/Джорджтаунский_эксперимент
- https://ru.wikipedia.org/wiki/Расширенная_сеть_переходов
- https://ru.wikipedia.org/wiki/N-грамма
- https://ru.wikipedia.org/wiki/LSTM
- https://ru.wikipedia.org/wiki/IBM_Watson
- https://openai.com/blog/better-language-models/#sample1
Обработка естественного языка (NLP): что это такое и почему это важно
Что это такое и почему это важно
Обработка естественного языка (NLP) — это ветвь искусственного интеллекта, которая помогает компьютерам понимать, интерпретировать и манипулировать человеческим языком .
 НЛП опирается на многие дисциплины, включая информатику и компьютерную лингвистику, в своем стремлении заполнить пробел между человеческим общением и компьютерным пониманием.
НЛП опирается на многие дисциплины, включая информатику и компьютерную лингвистику, в своем стремлении заполнить пробел между человеческим общением и компьютерным пониманием.
Эволюция обработки естественного языка
Хотя обработка естественного языка не является новой наукой, технология быстро развивается благодаря повышенному интересу к общению человека с машиной, а также доступности больших данных, мощных вычислений и усовершенствованных алгоритмов.
Как человек, вы можете говорить и писать на английском, испанском или китайском языках. Но родной язык компьютера, известный как машинный код или машинный язык, по большей части непонятен большинству людей. На самых нижних уровнях вашего устройства общение происходит не словами, а через миллионы нулей и единиц, которые производят логические действия.
Действительно, 70 лет назад программисты использовали перфокарты для связи с первыми компьютерами. Этот ручной и трудный процесс был понят относительно небольшим числом людей. Теперь вы можете сказать: «Алекса, мне нравится эта песня», и устройство, воспроизводящее музыку в вашем доме, уменьшит громкость и ответит: «ОК. Рейтинг сохранен, — человеческим голосом. Затем он адаптирует свой алгоритм для воспроизведения этой песни и других подобных песен при следующем прослушивании этой музыкальной станции.
Теперь вы можете сказать: «Алекса, мне нравится эта песня», и устройство, воспроизводящее музыку в вашем доме, уменьшит громкость и ответит: «ОК. Рейтинг сохранен, — человеческим голосом. Затем он адаптирует свой алгоритм для воспроизведения этой песни и других подобных песен при следующем прослушивании этой музыкальной станции.
Давайте подробнее рассмотрим это взаимодействие. Ваше устройство активировалось, когда услышало, что вы говорите, поняло невысказанное намерение в комментарии, выполнило действие и предоставило ответ в правильно построенном предложении на английском языке, и все это в течение примерно пяти секунд. Полное взаимодействие стало возможным благодаря НЛП, наряду с другими элементами ИИ, такими как машинное обучение и глубокое обучение.
Сделайте каждый голос услышанным с помощью обработки естественного языка
Узнайте, как машины могут научиться понимать и интерпретировать нюансы человеческого языка; как ИИ, обработка естественного языка и человеческий опыт работают вместе, чтобы помочь людям и машинам общаться и находить смысл в данных; и как НЛП используется во многих отраслях.
Читать электронную книгу
Работа с населением и поддержка пациентов с ХОБЛ усилены за счет обработки естественного языка и машинного обучения
Фонд COPD использует текстовую аналитику и анализ настроений, методы НЛП, чтобы превратить неструктурированные данные в ценную информацию. Эти результаты помогают предоставить медицинские ресурсы и эмоциональную поддержку пациентам и лицам, осуществляющим уход. Узнайте больше о том, как analytics улучшает качество жизни людей с легочными заболеваниями.
Учить больше
Почему важно НЛП?
Большие объемы текстовых данных
Обработка естественного языка помогает компьютерам общаться с людьми на их родном языке и масштабировать другие связанные с языком задачи. Например, НЛП позволяет компьютерам читать текст, слышать речь, интерпретировать ее, измерять настроение и определять, какие части важны.
Современные машины могут анализировать больше языковых данных, чем люди, без усталости и последовательным, непредвзятым образом. Учитывая ошеломляющее количество неструктурированных данных, которые генерируются каждый день, от медицинских карт до социальных сетей, автоматизация будет иметь решающее значение для эффективного полного анализа текстовых и речевых данных.
Структурирование крайне неструктурированного источника данных
Человеческий язык поразительно сложен и разнообразен. Мы выражаем себя бесконечными способами, как устно, так и письменно. Мало того, что существуют сотни языков и диалектов, но в каждом языке есть уникальный набор грамматических и синтаксических правил, терминов и сленга. Когда мы пишем, мы часто допускаем ошибки или сокращаем слова или опускаем знаки препинания. Когда мы говорим, у нас есть региональные акценты, мы мямлим, заикаемся и заимствуем термины из других языков.
Хотя контролируемое и неконтролируемое обучение, и особенно глубокое обучение, в настоящее время широко используются для моделирования человеческого языка, существует также потребность в синтаксическом и семантическом понимании и экспертных знаниях в предметной области, которые не обязательно присутствуют в этих подходах к машинному обучению. NLP важен, потому что он помогает устранить двусмысленность в языке и добавляет полезную числовую структуру к данным для многих последующих приложений, таких как распознавание речи или анализ текста.
NLP важен, потому что он помогает устранить двусмысленность в языке и добавляет полезную числовую структуру к данным для многих последующих приложений, таких как распознавание речи или анализ текста.
НЛП в современном мире
Узнайте больше об обработке естественного языка во многих отраслях
Планирование НЛП
Как организации по всему миру используют искусственный интеллект и НЛП? Каковы темпы внедрения и планы на будущее для этих технологий? Каковы бюджеты и планы развертывания? А какие бизнес-задачи решаются с помощью алгоритмов НЛП? Узнайте в этом отчете от TDWI.
Читать отчет
Обработка естественного языка для эффективности правительства
Правительственные учреждения бомбардируются текстовыми данными, включая цифровые и бумажные документы. Используя такие технологии, как обработка естественного языка, текстовая аналитика и машинное обучение, агентства могут сократить громоздкие ручные процессы, удовлетворяя потребности граждан в прозрачности и оперативности, решая трудовые задачи и извлекая новые идеи из своих данных.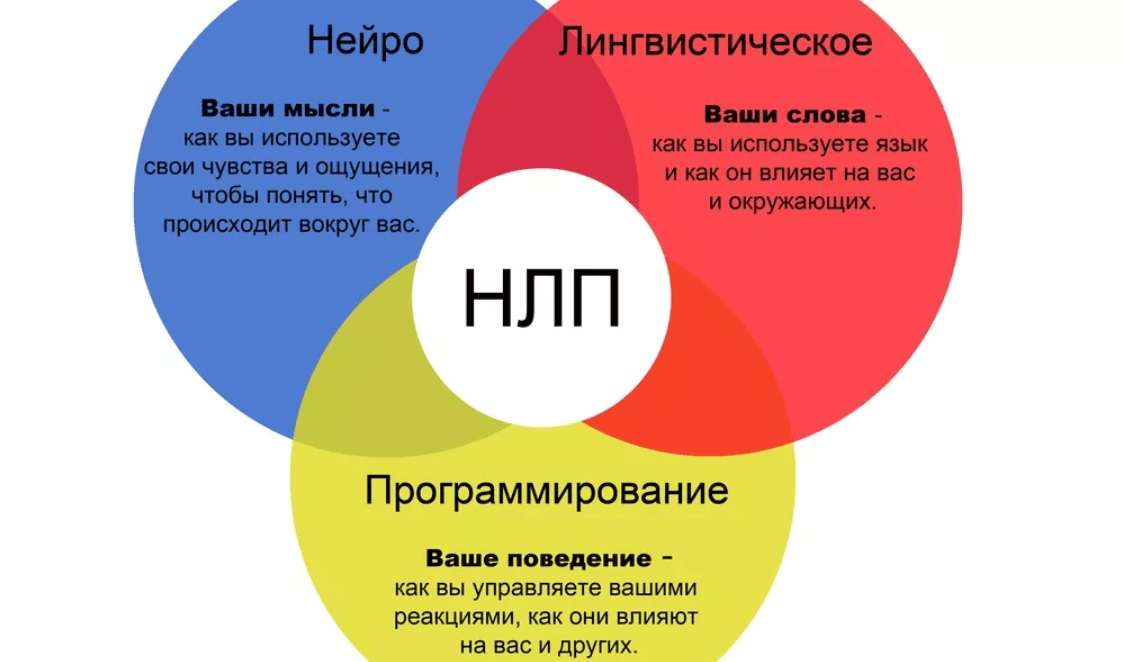
Прочитать краткое описание решения
Что может сделать текстовая аналитика для вашей организации?
Текстовая аналитика — это тип обработки естественного языка, который превращает текст в данные для анализа. Узнайте, как организации в банковской сфере, здравоохранении и биологических науках, производстве и правительстве используют текстовую аналитику для повышения качества обслуживания клиентов, сокращения случаев мошенничества и улучшения общества.
Читать газету
Как работает НЛП?
Разрушение элементарных частей языка
Обработка естественного языка включает в себя множество различных методов интерпретации человеческого языка, начиная от методов статистического и машинного обучения и заканчивая подходами, основанными на правилах и алгоритмами. Нам нужен широкий спектр подходов, потому что текстовые и голосовые данные сильно различаются, как и практические приложения.
Основные задачи НЛП включают в себя токенизацию и синтаксический анализ, лемматизацию/выделение основы, тегирование частей речи, определение языка и идентификацию семантических отношений. Если вы когда-нибудь рисовали предложения в начальной школе, вы уже выполняли эти задачи вручную.
В общих чертах задачи НЛП разбивают язык на более короткие элементарные части, пытаются понять отношения между частями и исследуют, как части работают вместе, чтобы создать смысл.
Эти основные задачи часто используются в возможностях НЛП более высокого уровня, таких как:
- Категоризация контента . Сводка документа на лингвистической основе, включая поиск и индексирование, оповещения о содержимом и обнаружение дублирования.
- Открытие темы и моделирование. Точно фиксируйте смысл и темы в текстовых коллекциях и применяйте к тексту расширенную аналитику, такую как оптимизация и прогнозирование.
- Анализ корпуса. Понимание структуры корпуса и документов с помощью выходной статистики для таких задач, как эффективная выборка, подготовка данных в качестве входных данных для дальнейших моделей и разработка подходов к моделированию.
- Контекстное извлечение. Автоматически извлекать структурированную информацию из текстовых источников.
- Анализ настроений. Выявление настроения или субъективных мнений в больших объемах текста, включая среднее настроение и анализ мнений.
- Преобразование речи в текст и текста в речь. Преобразование голосовых команд в письменный текст и наоборот.
- Обобщение документов. Автоматическое создание синопсисов больших объемов текста и обнаружение представленных языков в многоязычных корпусах (документах).
- Машинный перевод. Автоматический перевод текста или речи с одного языка на другой.
 Понимание структуры корпуса и документов с помощью выходной статистики для таких задач, как эффективная выборка, подготовка данных в качестве входных данных для дальнейших моделей и разработка подходов к моделированию.
Понимание структуры корпуса и документов с помощью выходной статистики для таких задач, как эффективная выборка, подготовка данных в качестве входных данных для дальнейших моделей и разработка подходов к моделированию.
Во всех этих случаях главная цель состоит в том, чтобы взять необработанный языковой ввод и использовать лингвистику и алгоритмы для преобразования или обогащения текста таким образом, чтобы он приносил большую ценность.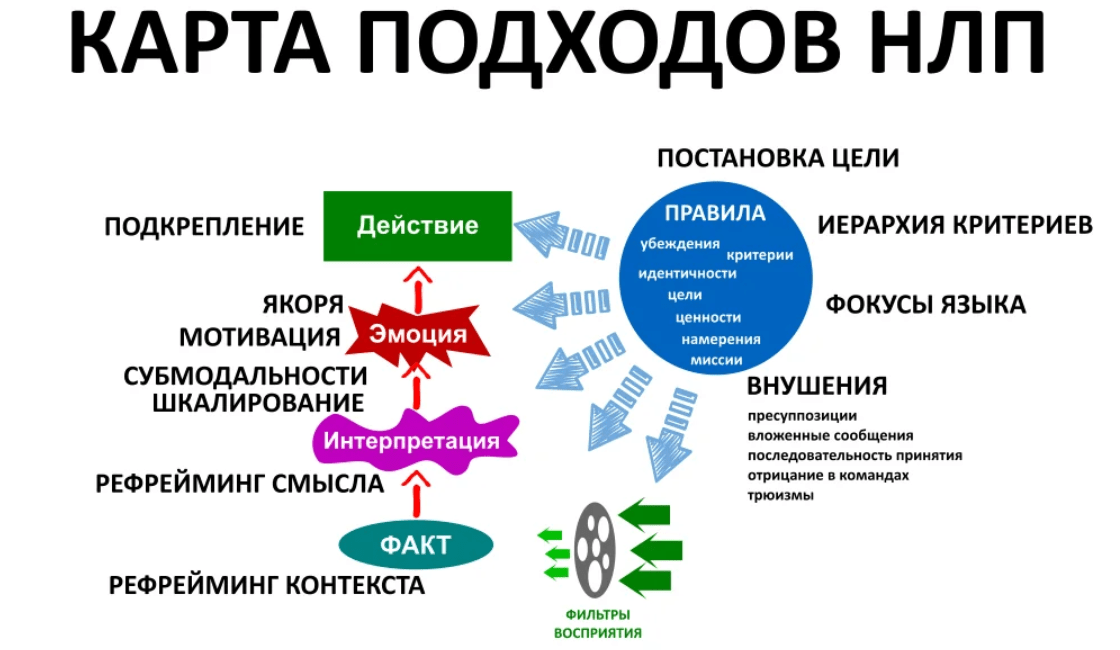
Методы и приложения НЛП
Как компьютеры интерпретируют текстовые данные
НЛП и текстовая аналитика
Обработка естественного языка идет рука об руку с анализом текста, который подсчитывает, группирует и классифицирует слова для извлечения структуры и смысла из больших объемов контента. Текстовая аналитика используется для изучения текстового содержимого и получения новых переменных из необработанного текста, которые можно визуализировать, фильтровать или использовать в качестве входных данных для моделей прогнозирования или других статистических методов.
НЛП и текстовая аналитика используются вместе во многих приложениях, в том числе:
- Исследовательские исследования. Выявляйте шаблоны и улики в электронных письмах или письменных отчетах, чтобы помочь обнаруживать и раскрывать преступления.
- Предметная экспертиза. Классифицируйте контент по значимым темам, чтобы вы могли действовать и обнаруживать тенденции.
- Аналитика социальных сетей. Отслеживайте осведомленность и настроения по конкретным темам и определяйте ключевых влиятельных лиц.

Повседневные примеры НЛП
НЛП широко применяется в повседневной жизни. Помимо общения с виртуальными помощниками, такими как Alexa или Siri, вот еще несколько примеров:
- Вы когда-нибудь просматривали электронные письма в папке со спамом и замечали сходство в строках темы? Вы видите байесовскую фильтрацию спама, статистический метод NLP, который сравнивает слова в спаме с действительными электронными письмами для выявления нежелательной почты.
- Вы когда-нибудь пропускали телефонный звонок и читали автоматическую расшифровку голосовой почты в почтовом ящике или приложении для смартфона? Это преобразование речи в текст, возможность НЛП.
- Вы когда-нибудь перемещались по веб-сайту, используя встроенную панель поиска или выбирая предложенные теги тем, объектов или категорий? Затем вы использовали методы НЛП для поиска, моделирования тем, извлечения сущностей и категоризации контента.

Подобласть НЛП, называемая пониманием естественного языка (НЛУ), начала набирать популярность из-за своего потенциала в когнитивных приложениях и приложениях ИИ. NLU выходит за рамки структурного понимания языка, чтобы интерпретировать намерения, разрешать контекст и двусмысленность слов и даже самостоятельно генерировать правильно сформированный человеческий язык. Алгоритмы NLU должны решать чрезвычайно сложную проблему семантической интерпретации, то есть понимания предполагаемого значения устной или письменной речи со всеми тонкостями, контекстом и выводами, которые мы, люди, можем понять.
Эволюция НЛП в сторону НЛУ имеет множество важных последствий как для бизнеса, так и для потребителей. Представьте себе силу алгоритма, который может понимать значение и нюансы человеческого языка во многих контекстах, от медицины до права и в классе. Поскольку объемы неструктурированной информации продолжают расти в геометрической прогрессии, мы выиграем от неустанной способности компьютеров помочь нам разобраться во всем этом.
404: Страница не найдена
Корпоративный ИИСтраница, которую вы пытались открыть по этому адресу, похоже, не существует. Обычно это результат плохой или устаревшей ссылки. Мы приносим свои извинения за доставленные неудобства.
Что я могу сделать сейчас?
Если вы впервые посещаете TechTarget, добро пожаловать! Извините за обстоятельства, при которых мы встречаемся. Вот куда вы можете пойти отсюда:
Поиск- Ознакомьтесь с последними новостями.
- Наша домашняя страница содержит самую свежую информацию о корпоративном искусственном интеллекте.
- Наша страница «О нас» содержит дополнительную информацию о сайте, на котором вы находитесь, Enterprise AI.
- Если вам нужно, свяжитесь с нами, мы будем рады услышать от вас.
Просмотр по категории
Бизнес-аналитика
- Увольнения Salesforce свидетельствуют о том, что Tableau потеряла независимость
На поставщика аналитических услуг сильно повлияло последнее сокращение персонала CRM-гиганта, которое последовало за массовым оттоком .
.. - 18 инструментов обработки данных, которые стоит использовать в 2023 году
Для приложений обработки данных доступно множество инструментов. Прочитайте о 18, включая их функции, возможности и использование, до …
- Эксперты прогнозируют, что НЛП станет главной тенденцией BI в этом году
Учитывая достижения в технологиях чат-ботов, такие как недавний запуск ChatGPT, наблюдатели отрасли ожидают, что поставщики аналитики будут …
 ..
..ИТ-директор
- Корпоративный потенциал метавселенной раскрывается на выставке CES 2023
Было много предупреждений о ажиотаже вокруг метавселенной, но на CES 2023 бизнес заинтересовался ее потенциалом для создания 3D …
- CES 2023 подчеркивает стремление предприятий к устойчивому развитию
CES 2023, ежегодная выставка потребительской электроники, уделяет внимание устойчивому развитию и технологиям, включая блокчейн, которые могут .
.. - 6 способов создать зеленую ИТ-культуру
ИТ-директора и ИТ-руководители, желающие внедрить программы устойчивого развития, не могут игнорировать человеческий фактор. Изучите стратегии построения …
 ..
..Управление данными
- 5 столпов наблюдаемости данных поддерживают конвейер данных
Наблюдаемость данных обеспечивает целостный контроль всего конвейера данных в организации. Используйте пять столбов, чтобы обеспечить…
- 18 лучших инструментов и технологий для работы с большими данными, о которых нужно знать в 2023 году
В приложениях для работы с большими данными доступно множество инструментов. Вот взгляд на 18 популярных технологий с открытым исходным кодом, а также …
- 18 лучших программных инструментов каталога данных, которые следует рассмотреть в 2023 году
Для создания каталогов данных и управления ими можно использовать множество инструментов.