Понятие идентификации и взаимосвязь с ущербом…
Понятие идентификации и взаимосвязь с ущербом…
Одним из важных элементов законодательства РФ в области персональных данных является вопрос идентификации личности. В тексте 152-ФЗ попадаются следующие словосочетания: » определенному или определяемому физическому лицу», «установить его личность», «удостоверяющего его личность», «установления личности». Кроме того, есть еще понятия идентификации, аутоинтефикации и т.д. В связи с утечкой sms с Мегафона засветилось мнение , что № телефона не идентифицирует личность.
Для определенности зададимся вопросом: Идентифицирует ли субъекта номер телефона?
Как у практика, у меня сложилось простое определение идентификации личности: если с этим набором персональных данных удастся, при случае, открыть уголовное дело с конкретным подозреваемым, то таки набор идентифицирует субъекта.
Попробуем, все таки, разобраться с установлением личности. В IT понятие идентификации определено как « присвоение субъектам и объектам идентификатора и / или сравнение идентификатора с перечнем присвоенных идентификаторов «.
Есть еще процесс аутентификации — « проверка принадлежности субъекту доступа предъявленного им идентификатора; подтверждение подлинности «.
И здесь пока еще понятно. Однако мы, IT-шники, здесь вторгаемся в зону юристов, а по сравнению с законодательным полем федеральная мультисервисная ИС с тысячами хостов пример простого и предельно понятного объекта.
name=’more’>
Начнем с того что слово Идентификация в философии трактуется как « установление тождественности неизвестного объекта известному на основании совпадения признаков; опознание «. И включает в себя идентификацию и аутентификацию в смысле IT. Я так подозреваю, что из-за неудачно выбранного термина надцать лет назад путаница и возникает…
Поисковый запрос выдал сразу ссылку на статью 265 УК ПФ. Установление личности подсудимого и своевременности вручения ему копии обвинительного заключения или обвинительного акта:
Установление личности подсудимого и своевременности вручения ему копии обвинительного заключения или обвинительного акта:
«1. Председательствующий устанавливает личность подсудимого, выясняя его фамилию, имя, отчество, год, месяц, день и место рождения, выясняет, владеет ли он языком, на котором ведется уголовное судопроизводство, место жительства подсудимого, место работы, род занятий, образование, семейное положение и другие данные, касающиеся его личности«.
Т.е. в судебном разбирательстве достаточно ФИО, даты и места рождения и можно утверждать, что этот набор безусловно устанавливает личность. В повседневной практике эти данные при установлении личности считываются из паспорта оператором. Фотография в этом случае играет по сути роль аутентификатора. Таким образом, я возьму на себя смелость утверждать, что процесс установления личности совпадает с философской идентификацией и включает в себя идентификацию и аутентификацию в терминологии IT.
С терминологией все вроде понятно, осталось разобраться какие данные идентифицируют субъекта.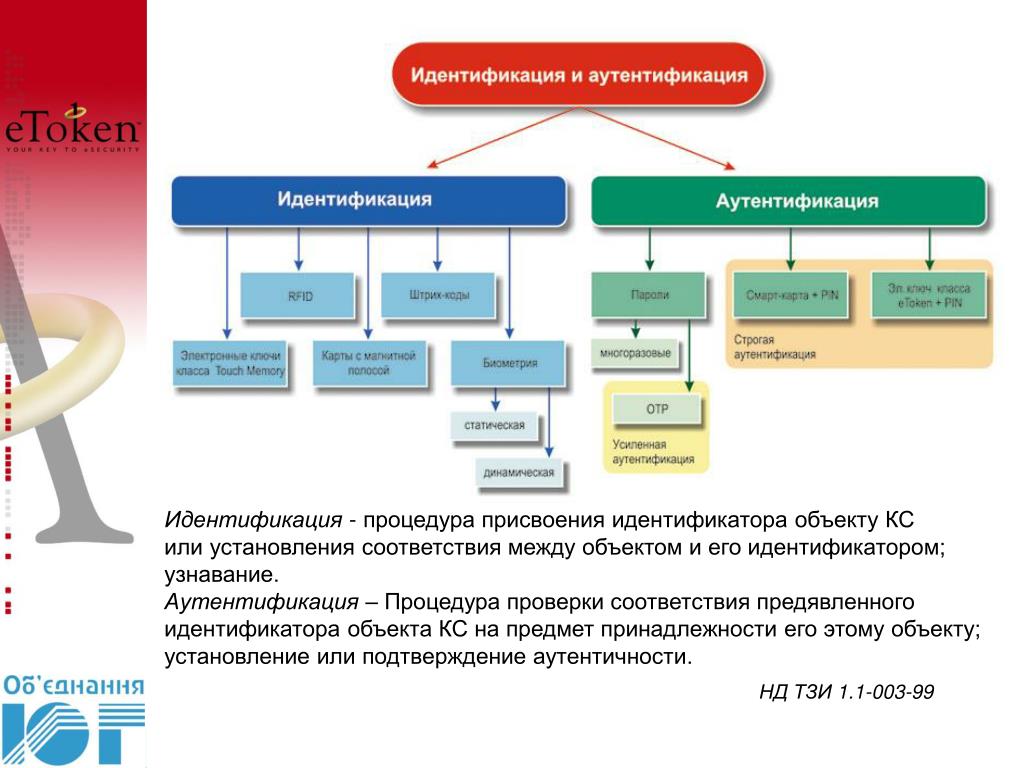 И тут юридический портал порадовал статьей » Криминалистическая идентификация «:
И тут юридический портал порадовал статьей » Криминалистическая идентификация «:
Идентификация — процесс установления тождества объекта или личности по совокупности общих и частных признаков, осуществляемый с целью решения вопроса о том, является ли данный объект искомым.
Возможность отожествления обуславливается самой природой материальных объектов. С одной стороны, относительной устойчивости и неизменности, а с другой — на способности объектов отражать свои признаки на других объектах, а также индивидуальность объекта.
Под индивидуальностью объекта понимается его безусловное отличие от любых других объектов. В природе не существует двух совершенно тождественных друг другу объектов. Даже стандартные вещи отличаются друг от друга рядом особенностей, их выявление и составляет задачу исследования.
Таким образом можно утверждать, что любой набор данных в совокупности уникальных для конкретного субъекта могут его идентифицировать при условии, что у нас есть такой же набор данных, но с ФИО и датой рождения. Т.е. в идентификации должны участвовать как минимум два набора данных: первый идентифицируемый, второй с которым определяется тождество.
Т.е. в идентификации должны участвовать как минимум два набора данных: первый идентифицируемый, второй с которым определяется тождество.
В качестве набора признаков может участвовать любой набор данных: телефон, счет в банке, лексические особенности написанного текста и т.д.
Т.е. мы можем говорить об идентифицирующем признаке определяемом как «свойство объекта, удовлетворяющее определенным требованиям:
1. Специфичность, Признак должен наиболее полно отражать свойства объекта, используемые для идентификации;
2. Выраженность признака — его способность к постоянному стабильному отображению. Признак должен быть воспроизведен в каждом случае образования следа;
3. Относительная устойчивость признака. Если то или иное свойство объекта не является устойчивым, то оно не может быть использовано в качестве идентификационного признака и участвовать в идентификационном процессе. Критерием относительной устойчивости свойства может быть его незначительная изменяемость во времени и пределах идентификационного периода, закономерная повторяемость его отображений на идентифицирующем объекте, устойчивые проявления свойства в различных условиях;
4. То или иное свойство объекта может быть использовано в качестве идентификационного признака при условии, если оно доступно для современных методов познания«.
То или иное свойство объекта может быть использовано в качестве идентификационного признака при условии, если оно доступно для современных методов познания«.
Очевидно что в процессе установления личности или идентификации (для меня это пока синонимы) участвуют как минимум три сущности: данные на основе которых проводится идентификация, данные которые хранятся вы эталонной БД и сущность (субъект, программа, устройство) которая производит сравнение первых со вторыми. Идентификация считается успешной, когда сущность может сделать обоснованный вывод о тождественности или не тождественности данных из первого и второго наборов.
Теперь вернемся к вопросу в заголовке. Утверждение, что номер сотового телефона не является идентифицирующим признаком не верно, однако в существенном количестве случаев не верно и обратное утверждение. Для получения ответа на поставленный вопрос необходимо понять вторую половину процесса идентификации. Есть ли общедоступный набор данных позволяющий определить по номеру телефона человека, который им пользуется? В принципе источников у нас несколько:
1. Базы номеров сотовых телефонов продающиеся на дисках или в Internet. Теоретически любой человек может ими воспользоваться, но мусора в таких базах существенно больше чем реальных данных.
Базы номеров сотовых телефонов продающиеся на дисках или в Internet. Теоретически любой человек может ими воспользоваться, но мусора в таких базах существенно больше чем реальных данных.
2. Поисковые запросы в Internet. Как ни странно не плохой источник персональной информации и не из-за утечек. Пользователи сами публикуют необходимую информацию в объявлениях, резюме и т.д.
3.Личное знакомство, трудовые отношения и т.п. – наиболее вероятный вариант идентификации.
В целом мы можем говорить о том, что в принципе существует существенное количество законных источников, с использованием которых можно произвести идентификацию (в философском смысле) человека по номеру сотового телефона, как в прочем и по номеру автомобиля или ip адресу.
Совершенно естественно мы, как оператор или интегратор, задаемся вопросом, а в каких случаях нам как оператору, становится интересно, а возможно ли на нашем объеме данных идентифицировать человека? Я могу предположить, что в этом случае уместно говорить о вреде субъекту причинённому в следствии его идентификации третьими лицами. Фактически можно утверждать, что ущерб субъекту возможен только после успешной и положительной идентификации. Можно так же предположить, что величина ущерба пропорциональна степени осведомленности субъекта производящего несанкционированную идентификацию. Только в этом случае данные предоставляющие дополнительную информацию о субъекте персональных данных имеют хоть какую-то смысловую нагрузку. Т.е. пока мы не услышал крик «Блин да это же Васька, мой сосед!» об ущербе можно говорить только как о теоретической возможности возникшей в следствии утечки данных.
Фактически можно утверждать, что ущерб субъекту возможен только после успешной и положительной идентификации. Можно так же предположить, что величина ущерба пропорциональна степени осведомленности субъекта производящего несанкционированную идентификацию. Только в этом случае данные предоставляющие дополнительную информацию о субъекте персональных данных имеют хоть какую-то смысловую нагрузку. Т.е. пока мы не услышал крик «Блин да это же Васька, мой сосед!» об ущербе можно говорить только как о теоретической возможности возникшей в следствии утечки данных.
философиявредбезопасность152-ФЗЗаконодательство
Мир сходит с ума, но еще не поздно все исправить. Подпишись на канал SecLabnews и внеси свой вклад в предотвращение киберапокалипсиса!
Карта сайта
Главная Обучение Библиотека Карта сайта
|
 Персиановский)
Персиановский) 2.014.01
2.014.01Исследование идентификации биомедицинских концепций: MetaMap в сравнении с людьми
Сравнительное исследование
. 2003; 2003: 529-33.
2003; 2003: 529-33.
Ванда Пратт 1 , Мелиха Йетисген-Йылдыз
принадлежность
- 1 Биомедицинская и медицинская информатика, Медицинский факультет Вашингтонского университета, Сиэтл, США.
- PMID: 14728229
- PMCID: PMC1479976
Бесплатная статья ЧВК
Сравнительное исследование
Wanda Pratt et al. AMIA Annu Symp Proc. 2003.
Бесплатная статья ЧВК
. 2003; 2003: 529-33.
2003; 2003: 529-33.
Авторы
Ванда Пратт 1 , Мелиха Йетисген-Йылдыз
принадлежность
- 1 Биомедицинская и медицинская информатика, Медицинский факультет Вашингтонского университета, Сиэтл, США.
- PMID: 14728229
- PMCID: PMC1479976
Абстрактный
Хотя огромные объемы неструктурированного текста доступны как богатый источник биомедицинских знаний, для обработки этих неструктурированных знаний требуются инструменты, которые выделяют понятия из текста в свободной форме. MetaMap является одним из инструментов, который разработчики систем в области биомедицины обычно используют для такой задачи, но мало кто изучал, насколько хорошо он выполняет эту задачу в целом. В этой статье мы сообщаем об исследовании, в котором производительность MetaMap сравнивается с результатами шести человек. Такие исследования сложны, потому что задача по своей сути субъективна и достижение консенсуса затруднено. Тем не менее, для тех понятий, с которыми участники в целом согласились, MetaMap смогла идентифицировать большинство понятий, если они были представлены в UMLS. Тем не менее, MetaMap выявил множество других понятий, которые люди не знали. Мы также сообщаем о нашем анализе типов сбоев, которые продемонстрировал MetaMap, а также о тенденциях в том, как люди выбирают для определения концепций.
В этой статье мы сообщаем об исследовании, в котором производительность MetaMap сравнивается с результатами шести человек. Такие исследования сложны, потому что задача по своей сути субъективна и достижение консенсуса затруднено. Тем не менее, для тех понятий, с которыми участники в целом согласились, MetaMap смогла идентифицировать большинство понятий, если они были представлены в UMLS. Тем не менее, MetaMap выявил множество других понятий, которые люди не знали. Мы также сообщаем о нашем анализе типов сбоев, которые продемонстрировал MetaMap, а также о тенденциях в том, как люди выбирают для определения концепций.
Цифры
Рисунок 1. Отзыв и точность MetaMap.
…
Рисунок 1. Отзыв и точность MetaMap.
Темные столбцы показывают, насколько хорошо MetaMap работал, когда…
Рисунок 1.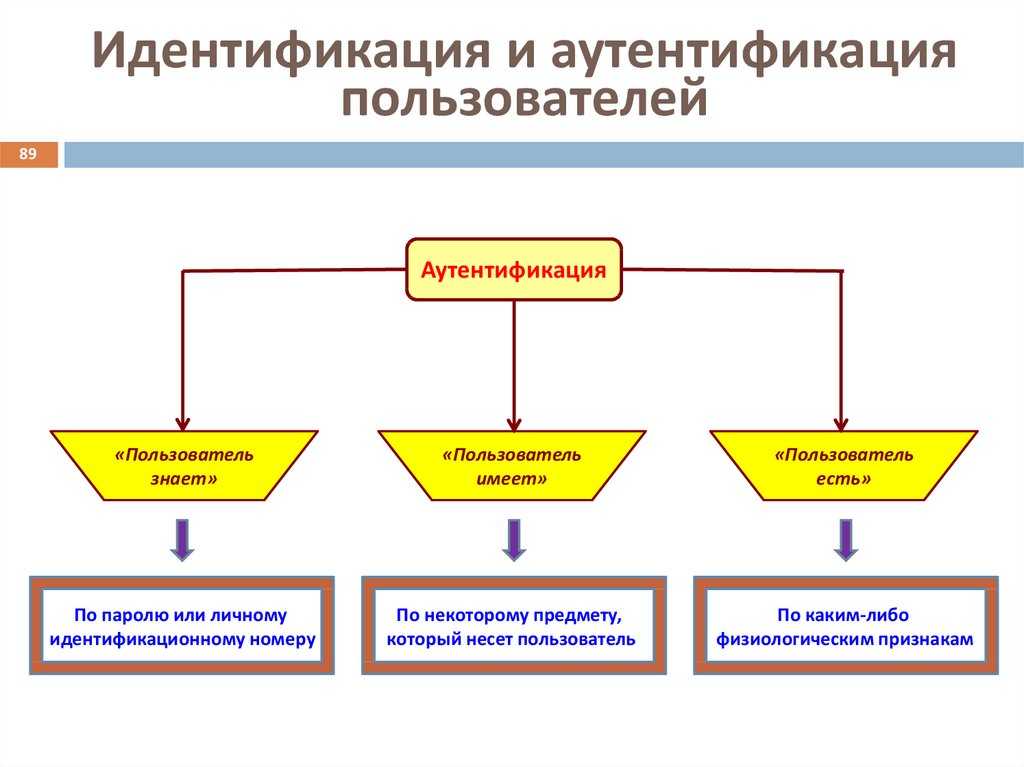 Отзыв и точность MetaMap.
Отзыв и точность MetaMap. Темные столбцы показывают, насколько хорошо MetaMap работал, когда учитывались только точные совпадения. Светлые столбцы (поверх темных) показывают, насколько увеличивается производительность MetaMap, если мы также учитываем частичные совпадения.
Рисунок 2. Средняя точность и полнота MetaMap…
Рисунок 2. Средняя точность и полнота MetaMap —
Результаты работы MetaMap, усредненные по…
Рисунок 2. Средняя точность и полнота MetaMap —Результаты производительности MetaMap, усредненные по всем играм. 95% доверительные интервалы представлены в виде планок погрешностей в каждом столбце.
См. это изображение и информацию об авторских правах в PMC
Похожие статьи
Использование «готовых» алгоритмов извлечения информации в клинической информатике: технико-экономическое обоснование аннотации MetaMap итальянских медицинских заметок.

Кьярамелло Э., Пинчироли Ф., Боналуми А., Кароли А., Тоньола Г. Кьярамелло Э. и др. Дж. Биомед Информ. 2016 Октябрь;63:22-32. doi: 10.1016/j.jbi.2016.07.017. Epub 2016 18 июля. Дж. Биомед Информ. 2016. PMID: 27444186
Эффективное сопоставление биомедицинского текста с метатезаурусом UMLS: программа MetaMap.
Аронсон АР. Аронсон АР. Proc AMIA Symp. 2001:17-21. Proc AMIA Symp. 2001. PMID: 11825149 Бесплатная статья ЧВК.
Идентификация респираторных заболеваний в отчетах отделения неотложной помощи для бионадзора с использованием MetaMap.
Чепмен В.В., Фисман М., Даулинг Дж.Н., Чепмен Б.Е., Риндфлеш Т.С. Чепмен В.В. и др. Stud Health Technol Inform. 2004; 107 (часть 1): 487–91.
Stud Health Technol Inform. 2004.
PMID: 15360860Анализ отказов MetaMap Transfer (MMTx).
Дивита Г., Це Т., Рот Л. Дивита Г. и др. Stud Health Technol Inform. 2004; 107 (часть 2): 763-7. Stud Health Technol Inform. 2004. PMID: 15360915
«Понимание» содержания учебной программы медицинской школы с помощью KnowledgeMap.
Денни Дж. К., Смитерс Дж. Д., Миллер Р. А., Спикард А. 3-й. Денни Дж. К. и др. J Am Med Inform Assoc. 2003 г., июль-август; 10(4):351-62. дои: 10.1197/jamia.M1176. Epub 2003 28 марта. J Am Med Inform Assoc. 2003. PMID: 12668688 Бесплатная статья ЧВК.

 Stud Health Technol Inform. 2004.
PMID: 15360860
Stud Health Technol Inform. 2004.
PMID: 15360860Посмотреть все похожие статьи
Цитируется
Машинное обучение и сетевая структура для обнаружения новых показаний для малых молекул.
Гилвари С., Эльхадер Дж., Мадхукар Н., Хенчклифф С., Гонсалвес М.Д., Элементо О. Гилвари С. и др. PLoS Comput Biol. 2020 7 августа; 16 (8): e1008098. doi: 10.1371/journal.pcbi.1008098. Электронная коллекция 2020 авг. PLoS Comput Biol. 2020. PMID: 32764756 Бесплатная статья ЧВК.
Семантическое глубокое обучение: предварительное знание и тип аналогии с четырехчленным встраиванием для приобретения методов лечения хорошо известных заболеваний.
Аргуэльо Кастельейро М., Дес Диз Х., Марото Н., Фернандес Прието М.Дж., Петерс С., Вро К., Севильяно Торрадо К., Маседа Фернандес Д., Стивенс Р. Аргуэлло Кастельейро М. и др. JMIR Med Inform. 2020 6 августа; 8 (8): e16948. дои: 10.2196/16948. JMIR Med Inform. 2020. PMID: 32759099 Бесплатная статья ЧВК.
Изучение семантического глубокого обучения для создания надежных и многократно используемых знаний о здоровье на основе систематических обзоров PubMed и ветеринарных клинических заметок.
Аргуэльо-Кастельейро М., Стивенс Р., Дес-Диз Дж., Роу С., Фернандес-Прието М.Дж., Марото Н., Маседа-Фернандес Д., Деметриу Г., Питерс С., Ноубл П.М., Джонс П.Х., Дюкс-Макьюэн Дж., Рэдфорд А.Д. , Кин Дж., Ненадич Г. Аргуэльо-Кастельиро М. и др. Дж. Биомедицинская семантика. 201912 ноября; 10 (Приложение 1): 22. doi: 10.1186/s13326-019-0212-6. Дж. Биомедицинская семантика. 2019. PMID: 31711540 Бесплатная статья ЧВК.
Автоматическое извлечение и оценка воздействия образа жизни на болезнь Альцгеймера с использованием обработки естественного языка.
Чжоу С., Ван Ю., Сон С., Терно Т.М., Лю Х., Кнопман Д.С. Чжоу С и др. Int J Med Inform. 2019 окт;130:103943. doi: 10.1016/j.ijmedinf.2019.08.003. Epub 2019 6 августа. Int J Med Inform. 2019. PMID: 31476655 Бесплатная статья ЧВК.
Связывание показателей клинического качества с данными исследований — тематическое исследование лечения астмы у детей.
Чунг М.К., Цафнат Г., Хибберт П., Рансимен В.Б., Койера Э. Чунг М.К. и др. BMC Health Serv Res. 2017 21 июля; 17 (1): 502. doi: 10.1186/s12913-017-2324-y. BMC Health Serv Res. 2017. PMID: 28732500 Бесплатная статья ЧВК.



Просмотреть все статьи «Цитируется по»
Типы публикаций
термины MeSH
Исследование идентификации биомедицинских концепций: MetaMap vs. People
- Список журналов
- AMIA Annu Symp Proc
- v.2003; 2003 г.
- PMC1479976
AMIA Annu Symp Proc. 2003 г.; 2003: 529–533.
2003 г.; 2003: 529–533.
, к.т.н. 1, 2 и , М.С. 2
Информация об авторе Информация об авторских правах и лицензиях Отказ от ответственности
Несмотря на то, что огромные объемы неструктурированного текста доступны как богатый источник биомедицинских знаний, для обработки этих неструктурированных знаний требуются инструменты, которые идентифицируют понятия из текста произвольной формы. MetaMap является одним из инструментов, который разработчики систем в области биомедицины обычно используют для такой задачи, но мало кто изучал, насколько хорошо он выполняет эту задачу в целом. В этой статье мы сообщаем об исследовании, в котором производительность MetaMap сравнивается с эффективностью шести человек. Такие исследования сложны, потому что задача по своей сути субъективна и достижение консенсуса затруднено. Тем не менее, для тех понятий, с которыми участники в целом согласились, MetaMap смогла идентифицировать большинство понятий, если они были представлены в UMLS. Тем не менее, MetaMap выявил множество других понятий, которые люди не знали. Мы также сообщаем о нашем анализе типов сбоев, которые продемонстрировал MetaMap, а также о тенденциях в том, как люди выбирают для определения концепций.
Тем не менее, MetaMap выявил множество других понятий, которые люди не знали. Мы также сообщаем о нашем анализе типов сбоев, которые продемонстрировал MetaMap, а также о тенденциях в том, как люди выбирают для определения концепций.
Большая часть биомедицинских знаний представлена в текстовой форме; тем не менее, такие неструктурированные представления информации трудно обрабатывать компьютерами последовательным и осмысленным образом. Чтобы решить эту проблему, многие системы, которые полагаются на текст как на источник информации, используют инструмент для идентификации понятий как фраз из одного или нескольких слов внутри текста. Поскольку этап идентификации концепций имеет решающее значение для преобразования текста в произвольной форме в вычислимое представление, нам необходимо понять, как люди идентифицируют концепции из текста и насколько хорошо инструменты могут соответствовать этому процессу идентификации концепций. В этом исследовании мы предлагаем начало для достижения такого понимания. Мы сообщаем как о том, как люди идентифицируют биомедицинские понятия из текста, так и о том, насколько хорошо MetaMap, широко используемый инструмент для определения биомедицинских понятий, работает по сравнению с людьми.
Мы сообщаем как о том, как люди идентифицируют биомедицинские понятия из текста, так и о том, насколько хорошо MetaMap, широко используемый инструмент для определения биомедицинских понятий, работает по сравнению с людьми.
Исследователи из Национальной медицинской библиотеки создали инструмент под названием MetaMap , который идентифицирует биомедицинские понятия из произвольного текстового ввода и отображает их в понятия из метатезауруса Единой медицинской языковой системы (UMLS). 1 , 2
MetaMap сначала разбивает текст на фразы, а затем для каждой фразы возвращает варианты сопоставления, ранжированные по силе сопоставления. Исследователи использовали MetaMap для различных задач, включая поиск информации, 3 – 5 интеллектуальный анализ текста, 6 , 7 и извлечение определенных видов понятий, таких как анатомические термины, 8 и сайты связывания молекул. 9 Хотя MetaMap является важным компонентом этих систем, никто не опубликовал оценку способности MetaMap идентифицировать биомедицинские концепции в целом.
9 Хотя MetaMap является важным компонентом этих систем, никто не опубликовал оценку способности MetaMap идентифицировать биомедицинские концепции в целом.
Для проведения такой оценки мы решили сравнить результаты MetaMap с результатами нескольких людей, идентифицирующих биомедицинские концепции из одного и того же текста.
Субъекты
По запросу по электронной почте мы набрали субъектов, которые имели некоторый клинический опыт. Субъекты были добровольцами и не получали никакой компенсации за участие в опросе. В наших пилотных исследованиях испытуемые тратили на задание от 30 до 60 минут, но, поскольку мы использовали веб-инструмент для опроса, мы не смогли записать время, которое окончательные испытуемые потратили на определение понятий.
Тестовый текст
Мы выбрали для оценки задачу идентификации концепций заголовков статей из MEDLINE. На мотивацию нашего выбора повлияло несколько факторов. Во-первых, из документов в коллекции MEDLINE можно получить широкий спектр информации, а их заголовки часто являются информативным отражением содержания этих документов. Во-вторых, наша работа по интеллектуальному анализу текста опирается на концепции, определенные из заголовков, и нам нужно было оценить, насколько хорошо MetaMap будет работать для этой задачи 9.0007 7 . Наконец, никто другой не оценивал идентификацию понятий в этом общем и широко используемом типе текста. Чтобы получить широкий охват, не перегружая испытуемых, мы использовали 20 заголовков о болезни (т. е. мигрень ), 20 заголовков о лечении (т. , ЭКГ ) всего 60 наименований. Для каждого из наших поисковых запросов, указанных в скобках выше, наш тестовый набор состоял из первых 20 заголовков из поиска MEDLINE по этому запросу, но письма, рекомендации и редакционные статьи были исключены.
Во-вторых, наша работа по интеллектуальному анализу текста опирается на концепции, определенные из заголовков, и нам нужно было оценить, насколько хорошо MetaMap будет работать для этой задачи 9.0007 7 . Наконец, никто другой не оценивал идентификацию понятий в этом общем и широко используемом типе текста. Чтобы получить широкий охват, не перегружая испытуемых, мы использовали 20 заголовков о болезни (т. е. мигрень ), 20 заголовков о лечении (т. , ЭКГ ) всего 60 наименований. Для каждого из наших поисковых запросов, указанных в скобках выше, наш тестовый набор состоял из первых 20 заголовков из поиска MEDLINE по этому запросу, но письма, рекомендации и редакционные статьи были исключены.
Процедуры
Мы запустили MetaMap для каждого заголовка и сохранили результаты в базе данных MySQL для последующего сравнения с ответами испытуемых.
Для сбора идентифицированных субъектом биомедицинских понятий мы проинструктировали каждого субъекта использовать анонимный веб-вопросник, чтобы указать его/ее выбор понятий из заголовков. В онлайн-опросе испытуемых сначала просили указать как свое медицинское образование, так и область специализации (необязательно для сохранения анонимности). Затем опрос представлял каждый заголовок как отдельный вопрос, за которым следовало пустое текстовое поле под каждым заголовком. Субъекты могли отправить онлайн-опрос только после того, как они ввели хотя бы одно понятие для каждого заголовка. Испытуемым давались следующие инструкции по идентификации понятий:
В онлайн-опросе испытуемых сначала просили указать как свое медицинское образование, так и область специализации (необязательно для сохранения анонимности). Затем опрос представлял каждый заголовок как отдельный вопрос, за которым следовало пустое текстовое поле под каждым заголовком. Субъекты могли отправить онлайн-опрос только после того, как они ввели хотя бы одно понятие для каждого заголовка. Испытуемым давались следующие инструкции по идентификации понятий:
Для каждого из следующих заголовков (обозначаемых в этой форме как вопросы 3–62), пожалуйста, перечислите все биомедицинские концепции (отдельные слова или фразы из нескольких слов) в поле под каждым заголовком. ЗАПИСЫВАЙТЕ КАЖДОЕ ПОНЯТИЕ С НОВОЙ СТРОКИ. Обратите внимание, что вы можете ввести название понятия, которое не совсем соответствует фразе в заголовке. Например, если в названии есть «Рак молочной железы и яичников», вы можете указать два понятия «Рак молочной железы» и «Рак яичников». Не стесняйтесь вырезать и вставлять слова или фразы из заголовка в текстовое поле, если это проще всего.

Параметры MetaMap
Многие параметры конфигурации влияют на выполнение MetaMap, а также на отображение его выходных данных. В частности, MetaMap предоставляет три разных типа моделей данных, которые отличаются друг от друга уровнем фильтрации, которую они выполняют в источниках знаний UMLS. Мы использовали их строгую модель, которая включает все типы фильтрации и которую они считают наиболее подходящей моделью для приложений семантической обработки 1 . Мы использовали только его высокопоставленные термины из выходных данных.
После сбора данных от испытуемых мы заметили, что они часто идентифицировали одни и те же медицинские понятия, но представляли их немного по-разному. Эти синтаксические вариации затрудняли автоматическое определение консенсуса для любого из указанных понятий. Таким образом, для уменьшения вариативности ответов испытуемых мы проверили и очистили все ответы испытуемых посредством следующих действий:
Исправление орфографических ошибок
Устранение дополнительной пунктуации и пространств
Устранение детерминантов (например, удаление A из A Пилотное исследование или исходного текста (например, удаление в качестве целевого местоположения из Испания в качестве целевого местоположения или удаление в качестве целевого десятилетия из 1990–2000 гг.
в качестве целевого десятилетия )Разделение концепций, связанных с соединением и (например, удаление и из мигрени и ареста сердца и его определение в качестве двух различных концепций и .
Один человек выполнил очистку всех данных в соответствии с указанными инструкциями, а второй человек дважды проверил все результаты очистки на соответствие и точность.
После очистки данных для каждого названия мы обозначили эталонный стандарт или золотой стандарт как те понятия, которые указаны не менее чем в половине субъектов. Чтобы оценить производительность MetaMap по сравнению с нашими субъектами, нам нужно было указать, что составляет соответствие между терминами. Учитывая разнообразие выявленных понятий, мы решили отметить два типа совпадений: точное совпадение и частичное совпадение.
Точное совпадение
Мы считали понятие точным соответствием , если оно было идентифицировано MetaMap, и оно точно соответствовало эталонному стандарту или любому из его синонимов из метатезауруса UMLS.
Например, мигрень и головная боль, мигрень являются синонимами в UMLS. Таким образом, это будет точное совпадение, даже если эталонным стандартом будет мигрень , а MetaMap перечислит головная боль, мигрень в качестве извлеченного понятия. Для других понятий, которые не были определены в Метатезаурусе UMLS, мы использовали только формы множественного и единственного числа понятий в качестве их синонимов. Мы проигнорировали регистровые различия.Частичное совпадение
Мы считали концепт частичным совпадением , если MetaMap идентифицировал его и являлся подмножеством эталонного стандарта. Все слова концепции MetaMap, состоящей из нескольких слов, должны появиться в эталонном стандартном понятии, чтобы оно было частичным совпадением. Например, когда эталонным стандартом был лептоменингеальный ангиоматоз , а MetaMap идентифицировал ангиоматоз как концепцию, это считалось частичным совпадением.
Кроме того, чтобы квалифицироваться как частичное совпадение, слова из концепции MetaMap должны стоять в том же порядке, что и в эталонном стандарте, без каких-либо дополнительных слов между ними. Например, когда эталонный стандарт был нейронов тройничного нерва , если MetaMap идентифицировал нейронов тройничного нерва как концепт, это считалось частичным совпадением, но если вместо этого MetaMap выбирал концепт нейронов тройничного нерва , он вообще не считался совпадением.Мы изучили результаты шести испытуемых (трех медсестер и трех врачей) и сравнили их с результатами MetaMap. Мы исключили результаты двух из восьми наших первоначальных субъектов (одной медсестры и одного врача), потому что они не следовали указаниям. Один субъект перефразировал название, а не определил отдельные понятия. Другой испытуемый подходил к проблеме радикально иначе, чем все остальные испытуемые. Вместо выбора понятий, которые явно содержались в заголовке или упоминались в нем, исключенный субъект читал заголовок и генерировал все понятия, которые можно было обсудить в документе с таким заголовком.
Шесть субъектов определили 492 понятия во всех заголовках. Из этого общего количества 151 квалифицируется как эталонный стандарт. Некоторые понятия из эталонного стандарта фигурировали более чем в одном заголовке. Например, концепция мигрени была выбрана в качестве эталонного стандарта для 12 различных наименований. Если бы мы исключили такие дубликаты, в нашем эталонном стандартном наборе оказалось бы 133 уникальных концепта. Из этих 133 понятий 73 находились в Метатезаурусе UMLS; 60 понятий не было в UMLS.
Основная цель нашего исследования состояла в том, чтобы определить, насколько хорошо MetaMap функционирует как инструмент идентификации понятий. Таким образом, метриками, на которых мы сосредоточились, были точность и полнота MetaMap, а не использование метрики, такой как статистика Каппа, для оценки согласия между субъектами. Будущие исследования будут изучать такие аспекты межэкспертной надежности.
MetaMap Recall
Чтобы определить, насколько хорошо MetaMap смогла идентифицировать все подходящие биомедицинские концепции, мы рассчитали две версии отзыва.
Для каждого названия отзыв с точным соответствием был рассчитан как количество терминов, которые были идентифицированы MetaMap и точно соответствуют эталонному стандарту, деленное на общее количество эталонных терминов. Отзыв с частичным совпадением был рассчитан таким же образом, за исключением того, что числитель включал частичные совпадения, а также точные совпадения. (Обратите внимание, что отзыв эквивалентен чувствительности.) См. графическое представление результатов точного и частичного совпадения для каждого заголовка. Средние результаты MetaMap представлены в таблице. Мы заметили, что производительность MetaMap хуже для последней трети названий.Открыть в отдельном окне
Отзыв и точность MetaMap.
Темные столбцы показывают, насколько хорошо MetaMap работал, когда учитывались только точные совпадения. Светлые столбцы (поверх темных) показывают, насколько увеличивается производительность MetaMap, если мы также учитываем частичные совпадения.
MetaMap Precision
Чтобы определить, насколько хорошо MetaMap смогла идентифицировать только понятия, которые были в тексте заголовка, мы рассчитали несколько вариантов точности. Для каждого названия Точность точного соответствия была рассчитана как количество терминов, которые были идентифицированы MetaMap и точно соответствуют эталонному стандарту, деленное на общее количество терминов, идентифицированных MetaMap. Точность частичного совпадения была рассчитана таким же образом, за исключением того, что числитель включал в себя частичные совпадения, а также точные совпадения. (Обратите внимание, что точность эквивалентна положительной прогностической ценности.) См. графическое представление результатов для каждого заголовка. Средние результаты MetaMap представлены в файлах .
Открыть в отдельном окне
Средняя точность и полнота MetaMap —
Результаты производительности MetaMap, усредненные по всем заголовкам.
95% доверительные интервалы представлены в виде планок погрешностей в каждом столбце.Для точности мы решили, что для учета различий в ответах испытуемых необходима более слабая версия расчета. Было бы несправедливо наказывать MetaMap, если небольшое количество субъектов также идентифицировало ту же концепцию. Таким образом, мы также вычислили то, что мы называем слабая точность, , где понятие, определенное в MetaMap, считалось совпадающим, если по крайней мере один субъект также идентифицировал это понятие, а не требовалось совпадение с эталонным стандартом по крайней мере для половины субъектов. С этим более слабым определением средняя точность точного соответствия MetaMap увеличилась.
Способы, которыми MetaMap потерпел неудачу, также могут предоставить ценную информацию для разработчиков MetaMap при определении того, где необходимы улучшения, а также для пользователей MetaMap при принятии решения о том, следует ли и где использовать MetaMap.
Из 151 концепта в эталонном стандарте MetaMap точно сопоставил 81 концепт, 60 частично, а десять не сопоставил вообще.
Большинство сбоев было вызвано отсутствием концепций в UMLS. Однако семь из 60 частично совпадающих понятий и четыре из десяти несовпадающих понятий были в UMLS. Для этих одиннадцати ненайденных понятий UMLS мы заметили четыре типа ошибок: (1) четыре случая, когда MetaMap неправильно разделил именное словосочетание, (2) три случая, когда он извлек правильное понятие в качестве фразы-кандидата, но не смог ранжировать его достаточно высоко, (3) три случая, когда он правильно разделил именное словосочетание, но по-прежнему не смог идентифицировать его как понятие, и (4) один случай, когда MetaMap изменил исходное именное словосочетание таким образом, что идентифицированное понятие полностью отличалось от исходного словосочетания. .Наше исследование также дало представление о том, как люди определяют биомедицинские понятия. Длинные фразы, состоящие из нескольких слов, могут быть проблемой для определения концепции, потому что люди по-разному выбирают, следует ли разбивать фразу и как ее разбивать.
Например, рассмотрим заголовок « Использование статинов и функционирование ног у пациентов с заболеванием периферических артерий нижних конечностей и без него ». Испытуемые выбрали следующие способы разделения длинных фраз (количество испытуемых, сделавших такой выбор, указано в скобках):Перифериальные артериальные заболевания с более низким уровнем 1)
заболевание периферических сосудов (1)
Субъекты также по-разному выбирали, включать ли общий термин в качестве биомедицинской концепции. Например, предметы 1, 3, 4 и 6 включали общий термин 9.0249 лечение
как понятие или как часть других понятий, таких как лечение мигрени , для некоторых из четырех заголовков, содержащих слово лечение; два других субъекта не включали лечение ни по одному из четырех названий. MetaMap не делает различий между общими и конкретными терминами; он идентифицирует любой термин, который он распознает, и выбирает обработку в качестве термина во всех четырех заголовках.Один испытуемый иногда был непоследователен в своем выборе включения общих терминов. Например, субъект 6 идентифицировал лечение мигрени и медицинское лечение в качестве медицинских понятий для двух случаев лечения, но не идентифицировали какое-либо понятие, связанное с лечением, для двух других случаев.
Необходимы дальнейшие исследования, чтобы определить, существуют ли другие устойчивые закономерности в том, как люди идентифицируют концепции, и как мы можем использовать эти знания для разработки более эффективных инструментов идентификации концепций.
Многие другие системы извлекают биомедицинские понятия из текста, но большинство систем пытаются извлекать только определенные типы понятий, в зависимости от поставленной задачи или относящихся к определенной области медицины. Например, MedLEE использовался для определения диагностических кодов для радиологических отчетов, 10 GENIES (модифицированная версия MedLEE) использовался для идентификации молекулярных путей, 11 проект Linguistic String использовался для определения параметров обеспечения качества в выписных сводках для случаев лечения астмы, 12 и SPRUS использовался для выявления закодированных заключения рентгенологических отчетов.
13 В отличие от этого, MetaMap пытается идентифицировать все биомедицинских концепции из произвольного текстового ввода. Эту более общую цель гораздо труднее эффективно оценить, потому что существует такая изменчивость в том, что идентифицируется как биомедицинская концепция, когда задача идентификации концепции считается независимой от цели приложения или медицинской специализации. При разработке нашего исследования мы основывали свои идеи на методах и критериях, описанных Фридманом и Хрипчаком. 14 За исключением расчета межэкспертной надежности, наше исследование соответствовало их 20 критериям хорошо спланированного исследования инструментов естественного языка. Поскольку наша задача идентификации общих понятий была гораздо более открытой, чем задачи на естественном языке, о которых они сообщали, такие как определение диагнозов, мы не могли предоставить испытуемым исчерпывающий список всех возможных понятий. Таким образом, наша оценка привела к значительно большей вариабельности ответов испытуемых.
Однако это исследование также дало нам возможность изучить стратегии людей в идентификации понятий более тщательно, чем в предыдущих исследованиях.Хотя достижение полного и точного консенсуса по задаче идентификации концепции оказалось невозможным, наша оценка ясно показывает, что MetaMap отлично справляется с извлечением общих биомедицинских концепций из текста произвольной формы. Большинство понятий из справочного стандарта, которые MetaMap не идентифицировал, были терминами, которых не было в UMLS. Таким образом, эффективность припоминания MetaMap в значительной степени определяется охватом биомедицинских терминов в UMLS и может быть существенно увеличена только за счет соответствующего увеличения словарного запаса UMLS.
Самое слабое место MetaMap — отсутствие точности. Тем не менее, люди показали большие различия в концепциях, которые они идентифицировали, и когда использовалась более слабая версия точности, производительность MetaMap увеличивалась.
Одним из ограничений этого исследования является то, что оно изучало производительность MetaMap только на заглавных фразах; у нас нет данных для проверки его эффективности на других типах текста.
Однако, поскольку заголовки MEDLINE содержат такое разнообразие понятий и формулировок, наше исследование предоставляет убедительные доказательства того, что MetaMap выполняет свои задачи по выявлению большинства биомедицинских понятий из текста в произвольной форме, не идентифицируя слишком много посторонних понятий.Это исследование также расширило наши знания о том, как люди выбирают биомедицинские понятия из текста. Мы узнали, что люди соглашаются по значительной части биомедицинских концепций, но эта задача очень субъективна. Полное и точное согласие всегда будет трудно найти, но дальнейшие исследования в этой области могут помочь нам разработать еще более точные инструменты для идентификации биомедицинских концепций.
Мы благодарим врачей и медсестер, принявших участие в этом исследовании. Спасибо также Лелии Арнхейм за ввод данных и проверку согласованности. Эта работа была поддержана грантом Национального научного фонда.
1. Аронсон, А. Эффективное сопоставление биомедицинского текста с метатезаурусом UMLS: программа MetaMap в Proc AMIA Symp 2001.
17–21. [Бесплатная статья PMC] [PubMed]2. Аронсон А.Р., MetaMap: Mapping Text to the UMLS Metathesaurus 1996. [Бесплатная статья PMC] [PubMed]
3. Аронсон А.Р., Rindflesch TC. Расширение запроса с помощью метатезауруса UMLS. Proc AMIA Symp. 1997;36(1):485–9. [Бесплатная статья PMC] [PubMed] [Google Scholar]
4. Пратт В. и Х. Вассерман. QueryCat: автоматическая категоризация запросов MEDLINE в Proc AMIA Symp 2000. Лос-Анджелес, Калифорния. п. 655–659. [Бесплатная статья PMC] [PubMed]
5. Wright LW, et al. Иерархическая концепция индексации полнотекстовых документов в Единой медицинской языковой системе Карта источников информации. Журнал Американского общества информационных наук. 1998;50(6):514–523. [Google Scholar]
6. Weeber, M., et al. Текстовые открытия в биомедицине: архитектура DAD-системы в Proc AMIA Symp 2000. 903–7. [Бесплатная статья PMC] [PubMed]
7. Pratt, W. and M. Yetisgen-Yildiz.
Основанный на знаниях, текстовый подход к поиску связей в биомедицинской литературе в SIGIR-03: Международная конференция ACM по исследованиям и разработкам в области информационного поиска 2003 г. (представлена). Торонто, Канада.8. Снейдерман К., Т. Риндфлеш и К. Бин. Идентификация анатомической терминологии в медицинском тексте в Proc AMIA Symp 1998. 428–32. [Бесплатная статья PMC] [PubMed]
9. Риндфлеш Т., Л. Хантер и А. Аронсон. Добыча терминологии молекулярного связывания из биомедицинского текста. в Proc AMIA Symp 1999. 127–31. [Бесплатная статья PMC] [PubMed]
10. Hripcsak G, et al. Исследование надежности для оценки извлечения информации из рентгенологических отчетов. J Am Med Inf Assoc. 1999; 6: 143–150. [Бесплатная статья PMC] [PubMed] [Google Scholar]
11. Friedman, C., et al. GENIES: система обработки на естественном языке для извлечения молекулярных путей из журнальных статей в приложении Bioinformatics 2001.
 в качестве целевого десятилетия )
в качестве целевого десятилетия ) Например, мигрень и головная боль, мигрень являются синонимами в UMLS. Таким образом, это будет точное совпадение, даже если эталонным стандартом будет мигрень , а MetaMap перечислит головная боль, мигрень в качестве извлеченного понятия. Для других понятий, которые не были определены в Метатезаурусе UMLS, мы использовали только формы множественного и единственного числа понятий в качестве их синонимов. Мы проигнорировали регистровые различия.
Например, мигрень и головная боль, мигрень являются синонимами в UMLS. Таким образом, это будет точное совпадение, даже если эталонным стандартом будет мигрень , а MetaMap перечислит головная боль, мигрень в качестве извлеченного понятия. Для других понятий, которые не были определены в Метатезаурусе UMLS, мы использовали только формы множественного и единственного числа понятий в качестве их синонимов. Мы проигнорировали регистровые различия. Кроме того, чтобы квалифицироваться как частичное совпадение, слова из концепции MetaMap должны стоять в том же порядке, что и в эталонном стандарте, без каких-либо дополнительных слов между ними. Например, когда эталонный стандарт был нейронов тройничного нерва , если MetaMap идентифицировал нейронов тройничного нерва как концепт, это считалось частичным совпадением, но если вместо этого MetaMap выбирал концепт нейронов тройничного нерва , он вообще не считался совпадением.
Кроме того, чтобы квалифицироваться как частичное совпадение, слова из концепции MetaMap должны стоять в том же порядке, что и в эталонном стандарте, без каких-либо дополнительных слов между ними. Например, когда эталонный стандарт был нейронов тройничного нерва , если MetaMap идентифицировал нейронов тройничного нерва как концепт, это считалось частичным совпадением, но если вместо этого MetaMap выбирал концепт нейронов тройничного нерва , он вообще не считался совпадением.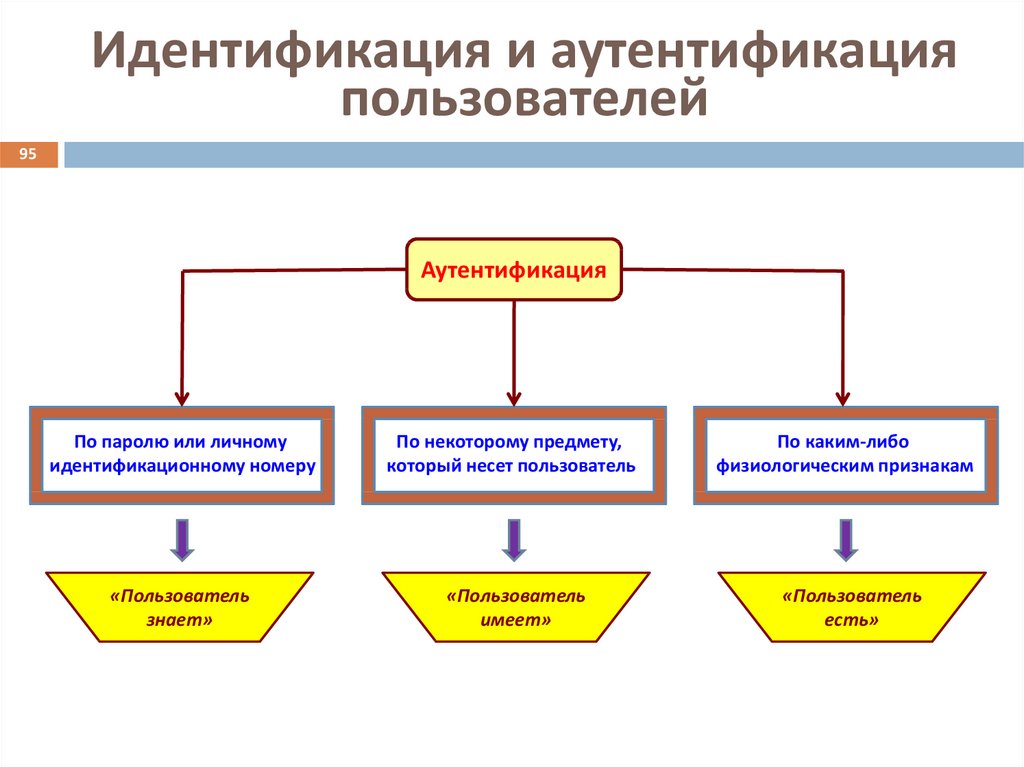
 Для каждого названия отзыв с точным соответствием был рассчитан как количество терминов, которые были идентифицированы MetaMap и точно соответствуют эталонному стандарту, деленное на общее количество эталонных терминов. Отзыв с частичным совпадением был рассчитан таким же образом, за исключением того, что числитель включал частичные совпадения, а также точные совпадения. (Обратите внимание, что отзыв эквивалентен чувствительности.) См. графическое представление результатов точного и частичного совпадения для каждого заголовка. Средние результаты MetaMap представлены в таблице. Мы заметили, что производительность MetaMap хуже для последней трети названий.
Для каждого названия отзыв с точным соответствием был рассчитан как количество терминов, которые были идентифицированы MetaMap и точно соответствуют эталонному стандарту, деленное на общее количество эталонных терминов. Отзыв с частичным совпадением был рассчитан таким же образом, за исключением того, что числитель включал частичные совпадения, а также точные совпадения. (Обратите внимание, что отзыв эквивалентен чувствительности.) См. графическое представление результатов точного и частичного совпадения для каждого заголовка. Средние результаты MetaMap представлены в таблице. Мы заметили, что производительность MetaMap хуже для последней трети названий.
 95% доверительные интервалы представлены в виде планок погрешностей в каждом столбце.
95% доверительные интервалы представлены в виде планок погрешностей в каждом столбце. Большинство сбоев было вызвано отсутствием концепций в UMLS. Однако семь из 60 частично совпадающих понятий и четыре из десяти несовпадающих понятий были в UMLS. Для этих одиннадцати ненайденных понятий UMLS мы заметили четыре типа ошибок: (1) четыре случая, когда MetaMap неправильно разделил именное словосочетание, (2) три случая, когда он извлек правильное понятие в качестве фразы-кандидата, но не смог ранжировать его достаточно высоко, (3) три случая, когда он правильно разделил именное словосочетание, но по-прежнему не смог идентифицировать его как понятие, и (4) один случай, когда MetaMap изменил исходное именное словосочетание таким образом, что идентифицированное понятие полностью отличалось от исходного словосочетания. .
Большинство сбоев было вызвано отсутствием концепций в UMLS. Однако семь из 60 частично совпадающих понятий и четыре из десяти несовпадающих понятий были в UMLS. Для этих одиннадцати ненайденных понятий UMLS мы заметили четыре типа ошибок: (1) четыре случая, когда MetaMap неправильно разделил именное словосочетание, (2) три случая, когда он извлек правильное понятие в качестве фразы-кандидата, но не смог ранжировать его достаточно высоко, (3) три случая, когда он правильно разделил именное словосочетание, но по-прежнему не смог идентифицировать его как понятие, и (4) один случай, когда MetaMap изменил исходное именное словосочетание таким образом, что идентифицированное понятие полностью отличалось от исходного словосочетания. . Например, рассмотрим заголовок « Использование статинов и функционирование ног у пациентов с заболеванием периферических артерий нижних конечностей и без него ». Испытуемые выбрали следующие способы разделения длинных фраз (количество испытуемых, сделавших такой выбор, указано в скобках):
Например, рассмотрим заголовок « Использование статинов и функционирование ног у пациентов с заболеванием периферических артерий нижних конечностей и без него ». Испытуемые выбрали следующие способы разделения длинных фраз (количество испытуемых, сделавших такой выбор, указано в скобках):
 13
13  Однако это исследование также дало нам возможность изучить стратегии людей в идентификации понятий более тщательно, чем в предыдущих исследованиях.
Однако это исследование также дало нам возможность изучить стратегии людей в идентификации понятий более тщательно, чем в предыдущих исследованиях. Однако, поскольку заголовки MEDLINE содержат такое разнообразие понятий и формулировок, наше исследование предоставляет убедительные доказательства того, что MetaMap выполняет свои задачи по выявлению большинства биомедицинских понятий из текста в произвольной форме, не идентифицируя слишком много посторонних понятий.
Однако, поскольку заголовки MEDLINE содержат такое разнообразие понятий и формулировок, наше исследование предоставляет убедительные доказательства того, что MetaMap выполняет свои задачи по выявлению большинства биомедицинских понятий из текста в произвольной форме, не идентифицируя слишком много посторонних понятий. 17–21. [Бесплатная статья PMC] [PubMed]
17–21. [Бесплатная статья PMC] [PubMed] Основанный на знаниях, текстовый подход к поиску связей в биомедицинской литературе в SIGIR-03: Международная конференция ACM по исследованиям и разработкам в области информационного поиска 2003 г. (представлена). Торонто, Канада.
Основанный на знаниях, текстовый подход к поиску связей в биомедицинской литературе в SIGIR-03: Международная конференция ACM по исследованиям и разработкам в области информационного поиска 2003 г. (представлена). Торонто, Канада.