Что такое обработка естественного языка? – Объяснение NLP – AWS
Что такое NLP?
Обработка естественного языка (NLP) – это технология машинного обучения, которая дает компьютерам возможность интерпретировать, манипулировать и понимать человеческий язык. Сегодня организации имеют большие объемы голосовых и текстовых данных из различных каналов связи, таких как электронные письма, текстовые сообщения, новостные ленты социальных сетей, видео, аудио и многое другое. Они используют программное обеспечение NLP для автоматической обработки этих данных, анализа намерений или настроений в сообщении и реагирования на человеческое общение в режиме реального времени.
Почему NLP играет такую важную роль?
Обработка естественного языка имеет решающее значение для эффективного анализа текстовых и речевых данных. Таким образом можно преодолевать различия в диалектах, сленге и грамматических нарушениях, типичных для повседневных разговоров. Компании используют этот метод для нескольких автоматизированных задач, таких как:
• Обработка, анализ и архивирование больших документов
• Анализ отзывов клиентов или записей колл-центра
• Запуск чат-ботов для автоматизированного обслуживания клиентов
• Ответы на вопросы «кто, что, когда и где»
• Классификация и извлечение текста
Вы также можете интегрировать NLP в приложения, ориентированные на клиента, чтобы более эффективно общаться с клиентами. Например, чат-бот анализирует и сортирует запросы клиентов, автоматически отвечая на распространенные вопросы и перенаправляя сложные запросы в службу поддержки. Эта автоматизация помогает снизить затраты, избавить агентов от необходимости тратить время на избыточные запросы и повышает удовлетворенность клиентов.
Например, чат-бот анализирует и сортирует запросы клиентов, автоматически отвечая на распространенные вопросы и перенаправляя сложные запросы в службу поддержки. Эта автоматизация помогает снизить затраты, избавить агентов от необходимости тратить время на избыточные запросы и повышает удовлетворенность клиентов.
Каковы сценарии использования NLP для бизнеса?
Компании используют программное обеспечение и инструменты NLP для эффективного и точного упрощения, автоматизации и оптимизации операций. Ниже мы приводим несколько примеров использования.
Скрытие конфиденциальных данныхКомпании в страховом, юридическом и медицинском секторах обрабатывают, сортируют и извлекают большие объемы конфиденциальных документов, таких как медицинские карты, финансовые данные и личные данные. Вместо проверки вручную компании используют технологию NLP для редактирования личной информации и защиты конфиденциальных данных. Например, Chisel AI помогает страховым компаниям извлекать номера полисов, даты истечения срока действия и другие личные атрибуты клиентов из неструктурированных документов с помощью Amazon Comprehend.
Технологии NLP позволяют чат-ботам и голосовым ботам быть более похожими на людей при общении с клиентами. Компании используют чат-ботов для масштабирования возможностей и качества обслуживания клиентов при минимальных эксплуатационных расходах. Компания PubNub, которая создает программное обеспечение для чат-ботов, использует Amazon Comprehend для внедрения локализованных функций чата для своих клиентов по всему миру. T-Mobile использует NLP для определения конкретных ключевых слов в текстовых сообщениях клиентов и предоставления персонализированных рекомендаций. Университет штата Оклахома внедряет чат-бот для вопросов и ответов для решения вопросов студентов с использованием технологии машинного обучения (ML)
Бизнес-аналитикаМаркетологи используют инструменты NLP, такие как Amazon Comprehend и Amazon Lex, чтобы получить образованное представление о том, что клиенты чувствуют к продукту или сервисам компании. Сканируя определенные фразы, они могут оценить настроение и эмоции клиента в письменных отзывах. Например, Success KPI предоставляет решения для обработки естественного языка, которые помогают компаниям сосредоточиться на целевых областях анализа тональности и помогают контакт-центрам получать полезную информацию из аналитики звонков.
Сканируя определенные фразы, они могут оценить настроение и эмоции клиента в письменных отзывах. Например, Success KPI предоставляет решения для обработки естественного языка, которые помогают компаниям сосредоточиться на целевых областях анализа тональности и помогают контакт-центрам получать полезную информацию из аналитики звонков.
Как работает NLP?
Обработка естественного языка сочетает в себе компьютерную лингвистику, машинное обучение и модели глубокого обучения для обработки человеческого языка.
Компьютерная лингвистикаКомпьютерная лингвистика – это наука о понимании и построении моделей человеческого языка с помощью компьютеров и программных инструментов. Исследователи используют методы компьютерной лингвистики, такие как синтаксический и семантический анализ, для создания платформ, помогающих машинам понимать разговорный человеческий язык. Такие инструменты, как переводчики языков, синтезаторы текста в речь и программное обеспечение для распознавания речи, основаны на компьютерной лингвистике.
Машинное обучение – это технология, которая обучает компьютер с помощью выборочных данных для повышения его эффективности. Человеческий язык имеет несколько особенностей, таких как сарказм, метафоры, вариации в структуре предложений, а также исключения из грамматики и употребления, на изучение которых у людей уходят годы. Программисты используют методы машинного обучения, чтобы научить приложения NLP распознавать и точно понимать эти функции с самого начала.
Глубокое обучениеГлубокое обучение – это особая область машинного обучения, которая учит компьютеры учиться и мыслить как люди. Это включает нейросеть, состоящую из узлов обработки данных, напоминающих операции человеческого мозга. С помощью глубокого обучения компьютеры распознают, классифицируют и сопоставляют сложные закономерности во входных данных.
Этапы внедрения NLPКак правило, процесс NLP начинается со сбора и подготовки неструктурированных текстовых или речевых данных из таких источников, как облачные хранилища данных, опросы, электронные письма или внутренние приложения бизнес-процессов.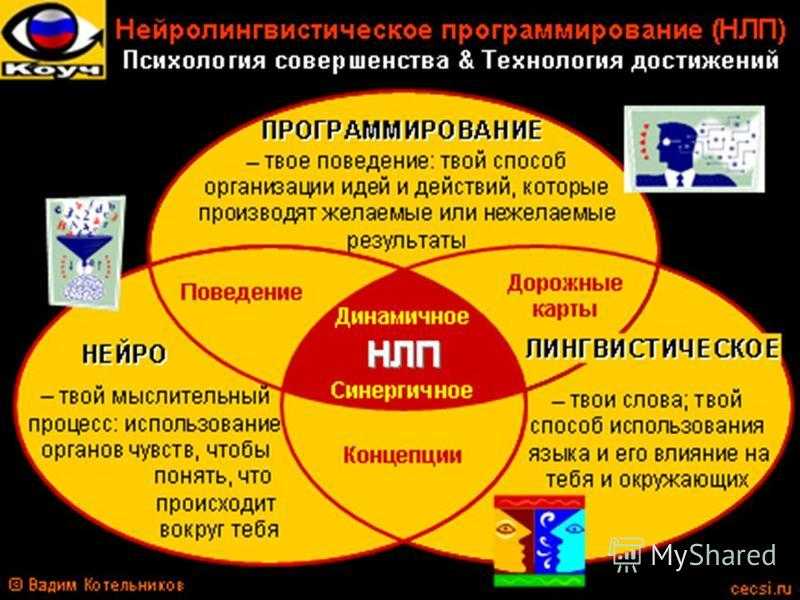
Программное обеспечение NLP использует методы предварительной обработки, такие как токенизация, стемминг, лемматизация и удаление стоп-слов, для подготовки данных для различных приложений.
- Токенизация разбивает предложение на отдельные единицы слов или фраз.
- Стемминг и лемматизация упрощают слова до их корневой формы. Например, эти процессы превращают начало в старт.
- Удаление стоп-слов гарантирует, что слова, которые не добавляют значимого смысла предложению, такие как для и с, будут удалены.
Исследователи используют предварительно обработанные данные для обучения моделей NLP с помощью машинного обучения для выполнения конкретных приложений на основе предоставленной текстовой информации. Обучение алгоритмов NLP требует предоставления программного обеспечения большими выборками данных для повышения их точности.
Затем специалисты по машинному обучению развертывают модель или интегрируют ее в существующую производственную среду. Модель NLP получает входные данные и прогнозирует выходные данные для конкретного сценария использования, для которого она предназначена. Приложение NLP можно запустить на живых данных и получить требуемый результат.
Что такое задачи NLP?
Методы NLP, или задачи NLP, разбивают человеческий текст или речь на более мелкие части, которые компьютерные программы могут легко понять. Общие возможности обработки и анализа текста в NLP приведены ниже.
Часть тегирования речиЭто процесс, при котором программное обеспечение NLP помечает отдельные слова в предложении в соответствии с контекстуальными обычаями, такими как существительные, глаголы, прилагательные или наречия. Это помогает компьютеру понять, как слова формируют значимые отношения друг с другом.
Некоторые слова могут иметь разные значения при использовании в разных сценариях. Например, слово «замок» в разных предложениях означает разные вещи.
- Замок – это средневековое строение.
- Люди используют замок, чтобы закрыть что-либо.
Устраняя неоднозначность смысла слов, программное обеспечение NLP определяет предполагаемое значение слова, обучая его языковую модель или ссылаясь на словарные определения.
Распознавание речи превращает голосовые данные в текст. Процесс включает в себя разбиение слов на более мелкие части и преодоление таких проблем, как акценты, оскорбления, интонация и неправильное использование грамматики в повседневном разговоре. Ключевым применением распознавания речи является транскрипция, которую можно выполнить с помощью сервисов преобразования речи в текст, таких как Amazon Transcribe.
Программное обеспечение для машинного перевода использует обработку естественного языка для преобразования текста или речи с одного языка на другой с сохранением контекстуальной точности. Сервис AWS, поддерживающий машинный перевод, – Amazon Translate.
Распознавание именованных сущностейЭтот процесс определяет уникальные имена людей, мест, событий, компаний и многого другого. Программное обеспечение NLP использует распознавание именованных сущностей для определения отношений между различными сущностями в предложении. Рассмотрим следующий пример.
Джейн отправилась во Францию на праздник и там побаловала себя местной кухней.
Программное обеспечение NLP выберет Джейн и Франция в качестве особых субъектов в предложении. Это может быть дополнительно расширено с помощью разрешения совместных ссылок, определяющего, используются ли разные слова для описания одного и того же субъекта. В приведенном выше примере и Джейн, и она указали на одного и того же человека.
В приведенном выше примере и Джейн, и она указали на одного и того же человека.
Анализ тональности – это основанный на искусственном интеллекте подход к интерпретации эмоций, передаваемых текстовыми данными. Программа NLP анализирует текст на наличие слов или фраз, которые показывают неудовлетворенность, счастье, сомнения, сожаление и другие скрытые эмоции.
Каковы подходы к обработке естественного языка?
Ниже мы приводим некоторые общие подходы к обработке естественного языка.
Контролируемая обработка естественного языка (NLP)Во время контролируемой обработки естественного языка программное обеспечение обучается с помощью набора маркированных или известных входов и выходов. Программа сначала обрабатывает большие объемы известных данных и учится получать правильные выходные данные из любого неизвестного ввода. Например, компании обучают инструменты NLP категоризации документов в соответствии с конкретными этикетками.
Неконтролируемая обработка естественного языка использует статистическую языковую модель для прогнозирования закономерности, которая возникает при подаче немаркированного ввода. Например, функция автозаполнения в текстовых сообщениях предлагает релевантные слова, которые имеют смысл для предложения, отслеживая ответ пользователя.
Понимание естественных языковПонимание естественного языка (NLU) – это подмножество NLP, которое фокусируется на анализе значения предложений. NLU позволяет программе находить похожие значения в разных предложениях или обрабатывать слова, которые имеют разные значения.
Генерация естественного языкаГенерация естественного языка (NLG) направлена на создание разговорного текста, как это делают люди, на основе определенных ключевых слов или тем. Например, интеллектуальный чат-бот с возможностями NLG может общаться с клиентами так же, как и сотрудники службы поддержки клиентов.
Как AWS может помочь в решении задач NLP?
AWS предоставляет самый широкий и полный набор сервисов искусственного интеллекта и машинного обучения для клиентов любого уровня знаний, связанных с полным набором источников данных.
Для клиентов, которым не хватает навыков машинного обучения, требуется более быстрый выход на рынок или которые хотят добавить интеллект к существующему процессу или приложению, AWS предлагает ряд языковых сервисов на основе машинного обучения, которые позволяют компаниям легко добавлять интеллектуальные данные в свои приложения искусственного интеллекта с помощью обученные API для речи, транскрипции, перевода, анализа текста и работы чат-бота. Сервисы включают Amazon Comprehend для поиска идей и связей в тексте, Amazon Transcribe для автоматического распознавания речи, Amazon Translate для свободного перевода текста, Amazon Polly для естественного звучания от текста к речи, Amazon Lex для создания чат-ботов для взаимодействия с клиентами и Amazon Kendra для интеллектуального поиска корпоративных систем для быстрого поиска нужного контента.
Для клиентов, которые хотят создать стандартное решение NLP в рамках своего бизнеса, Amazon SageMaker упрощает подготовку данных, создание, обучение и развертывание моделей машинного обучения для любого сценария использования с полностью управляемой инфраструктурой, инструментами и рабочими процессами, включая предложения без кода для бизнеса аналитики. С помощью Hugging Face на Amazon SageMaker вы можете развертывать и настраивать предварительно обученные модели от Hugging Face, поставщика моделей обработки естественного языка (NLP) с открытым исходным кодом, известного как Transformers, сокращая время настройки и использования этих моделей NLP с недель до минут.
Начните работу с обработкой естественного языка (NLP), создав аккаунт AWS уже сегодня.
NLP (Natural Language Processing) — обработка естественного языка
NLP (Natural Language Processing, обработка естественного языка) — это направление в машинном обучении, посвященное распознаванию, генерации и обработке устной и письменной человеческой речи. Находится на стыке дисциплин искусственного интеллекта и лингвистики.
Находится на стыке дисциплин искусственного интеллекта и лингвистики.
Инженеры-программисты разрабатывают механизмы, позволяющие взаимодействовать компьютерам и людям посредством естественного языка. Благодаря NLP компьютеры могут читать, интерпретировать, понимать человеческий язык, а также выдавать ответные результаты. Как правило, обработка основана на уровне интеллекта машины, расшифровывающего сообщения человека в значимую для нее информацию.
Процесс машинного понимания с применением алгоритмов обработки естественного языка может выглядеть так:
- Речь человека записывается аудио-устройством.
- Машина преобразует слова из аудио в письменный текст.
- Система NLP разбирает текст на составляющие, понимает контекст беседы и цели человека.
- С учетом результатов работы NLP машина определяет команду, которая должна быть выполнена.
Кто использует NLP
Приложения NLP окружают нас повсюду. Это поиск в Google или Яндексе, машинный перевод, чат-боты, виртуальные ассистенты вроде Siri, Алисы, Салюта от Сбера и пр. NLP применяется в digital-рекламе, сфере безопасности и многих других.
NLP применяется в digital-рекламе, сфере безопасности и многих других.
Технологии NLP используют как в науке, так и для решения коммерческих бизнес-задач: например, для исследования искусственного интеллекта и способов его развития, а также создания «умных» систем, работающих с естественными человеческими языками, от поисковиков до музыкальных приложений.
Как устроена обработка языков
Раньше алгоритмам прописывали набор реакций на определенные слова и фразы, а для поиска использовалось сравнение. Это не распознавание и понимание текста, а реагирование на введенный набор символов. Такой алгоритм не смог бы увидеть разницы между столовой ложкой и школьной столовой.
NLP — другой подход. Алгоритмы обучают не только словам и их значениям, но и структуре фраз, внутренней логике языка, пониманию контекста. Чтобы понять, к чему относится слово «он» в предложении «человек носил костюм, и он был синий», машина должна иметь представление о свойствах понятий «человек» и «костюм». Чтобы научить этому компьютер, специалисты используют алгоритмы машинного обучения и методы анализа языка из фундаментальной лингвистики.
Чтобы научить этому компьютер, специалисты используют алгоритмы машинного обучения и методы анализа языка из фундаментальной лингвистики.
Задачи NLP
Распознавание речи. Этим занимаются голосовые помощники приложений и операционных систем, «умные» колонки и другие подобные устройства. Также распознавание речи используется в чат-ботах, сервисах автоматического заказа, при автоматической генерации субтитров для видеороликов, голосовом вводе, управлении «умным» домом. Компьютер распознает, что сказал ему человек, и выполняет в соответствии с этим нужные действия.
Обработка текста. Человек может также общаться с компьютером посредством письменного текста. Например, через тех же чат-ботов и помощников. Некоторые программы работают одновременно и как голосовые, и как текстовые ассистенты. Пример — помощники в банковских приложениях. В этом случае программа обрабатывает полученный текст, распознает его или классифицирует. Затем она выполняет действия на основе данных, которые получила.
Извлечение информации. Из текста или речи можно извлечь конкретную информацию. Пример задачи — ответы на вопросы в поисковых системах. Алгоритм должен обработать массив входных данных и выделить из него ключевые элементы (слова), в соответствии с которыми будет найден актуальный ответ на поставленный вопрос. Для этого требуются алгоритмы, способные различать контекст и понятия в тексте.
Анализ информации. Это схожая с предыдущей задача, но цель — не получить конкретный ответ, а проанализировать имеющиеся данные по определенным критериям. Машины обрабатывают текст и определяют его эмоциональную окраску, тему, стиль, жанр и др. То же самое можно сказать про запись голоса.
Анализ информации часто используется в разных видах аналитики и в маркетинге. Например, можно отследить среднюю тональность отзывов и высказываний по заданному вопросу. Соцсети используют такие алгоритмы для поиска и блокировки вредоносного контента. В перспективе компьютер сможет отличать фейковые новости от реальных, устанавливать авторство текста. Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.
Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.
Генерация текста и речи. Противоположная распознаванию задача — генерация, или синтез. Алгоритм должен отреагировать на текст или речь пользователя. Это может быть ответ на вопрос, полезная информация или забавная фраза, но реплика должна быть по заданной теме. В системах распознавания речи предложения разбиваются на части. Далее, чтобы произнести определенную фразу, компьютер сохраняет их, преобразовывает и воспроизводит. Конечно, на границах «сшивки» могут возникать искажения, из-за чего голос часто звучит неестественно.
Генерация текста не ограничивается шаблонными ответами, заложенными в алгоритм. Для нее используют алгоритмы машинного обучения. «Говорящие» программы могут учиться на основе реальных данных. Можно добиться того, чтобы алгоритм писал стихи или рассказы с логичной структурой, но они обычно не очень осмысленные.
Автоматический пересказ. Это направление также подразумевает анализ информации, но здесь используется и распознавание, и синтез.Задача — обработать большой объем информации и сделать его краткий пересказ. Это бывает нужно в бизнесе или в науке, когда необходимо получить ключевые пункты большого набора данных.
Машинный перевод. Программы-переводчики тоже используют алгоритмы машинного обучения и NLP. С их использованием качество машинного перевода резко выросло, хотя до сих пор зависит от сложности языка и связано с его структурными особенностями. Разработчики стремятся к тому, чтобы машинный перевод стал более точным и мог дать адекватное представление о смысле оригинала во всех случаях.
Машинный перевод частично автоматизирует задачу профессиональных переводчиков: его используют для перевода шаблонных участков текста, например в технической документации.
Как обрабатывается текст
Алгоритмы не работают с «сырыми» данными. Большая часть процесса — подготовка текста или речи, преобразование их в вид, доступный для восприятия компьютером.
Большая часть процесса — подготовка текста или речи, преобразование их в вид, доступный для восприятия компьютером.
Очистка. Из текста удаляются бесполезные для машины данные. Это большинство знаков пунктуации, особые символы, скобки, теги и пр. Некоторые символы могут быть значимыми в конкретных случаях. Например, в тексте про экономику знаки валют несут смысл.
Препроцессинг.
- приведение символов к одному регистру, чтобы все слова были написаны с маленькой буквы;
- токенизация — разбиение текста на токены. Так называют отдельные компоненты — слова, предложения или фразы;
- тегирование частей речи — определение частей речи в каждом предложении для применения грамматических правил;
- лемматизация и стемминг — приведение слов к единой форме.
 Стемминг более грубый, он обрезает суффиксы и оставляет корни. Лемматизация — приведение слов к изначальным словоформам, часто с учетом контекста;
Стемминг более грубый, он обрезает суффиксы и оставляет корни. Лемматизация — приведение слов к изначальным словоформам, часто с учетом контекста; - удаление стоп-слов — артиклей, междометий и пр.;
- спелл-чекинг — автокоррекция слов, которые написаны неправильно.
 Стемминг более грубый, он обрезает суффиксы и оставляет корни. Лемматизация — приведение слов к изначальным словоформам, часто с учетом контекста;
Стемминг более грубый, он обрезает суффиксы и оставляет корни. Лемматизация — приведение слов к изначальным словоформам, часто с учетом контекста;Методы выбирают согласно задаче.
Векторизация. После предобработки на выходе получается набор подготовленных слов. Но алгоритмы работают с числовыми данными, а не с чистым текстом. Поэтому из входящей информации создают векторы — представляют ее как набор числовых значений.
Популярные варианты векторизации — «мешок слов» и «мешок N-грамм». В «мешке слов» слова кодируются в цифры. Учитывается только количество слова в тексте, а не их расположение и контекст. N-граммы — это группы из N слов. Алгоритм наполняет «мешок» не отдельными словами с их частотой, а группами по несколько слов, и это помогает определить контекст.
Применение алгоритмов машинного обучения. С помощью векторизации можно оценить, насколько часто в тексте встречаются слова. Но большинство актуальных задач сложнее, чем просто определение частоты — тут нужны продвинутые алгоритмы машинного обучения. В зависимости от типа конкретной задачи создается и настраивается своя отдельная модель.
С помощью векторизации можно оценить, насколько часто в тексте встречаются слова. Но большинство актуальных задач сложнее, чем просто определение частоты — тут нужны продвинутые алгоритмы машинного обучения. В зависимости от типа конкретной задачи создается и настраивается своя отдельная модель.
Алгоритмы обрабатывают, анализируют и распознают входные данные, делают на их основе выводы. Это интересный и сложный процесс, в котором много математики и теории вероятностей.
Что такое обработка естественного языка? — Объяснение НЛП
Что такое НЛП?
Обработка естественного языка (NLP) — это технология машинного обучения, которая дает компьютерам возможность интерпретировать, манипулировать и понимать человеческий язык. Сегодня организации имеют большие объемы голосовых и текстовых данных из различных каналов связи, таких как электронная почта, текстовые сообщения, новостные ленты социальных сетей, видео, аудио и многое другое. Они используют программное обеспечение НЛП для автоматической обработки этих данных, анализа намерений или настроений в сообщении и реагирования в режиме реального времени на человеческое общение.
Почему важно НЛП?
Обработка естественного языка (NLP) имеет решающее значение для полного и эффективного анализа текстовых и речевых данных. Он может работать с различиями в диалектах, сленге и грамматическими неточностями, типичными для повседневных разговоров.
Компании используют его для нескольких автоматизированных задач, таких как:
• Обработка, анализ и архивирование больших документов
• Анализ отзывов клиентов или записей колл-центра
• Запуск чат-ботов для автоматизированного обслуживания клиентов
• Ответы на вопросы «кто-что-когда-где»
• Классификация и извлечение текста
Вы также можете интегрировать НЛП в клиентские приложения для более эффективного общения с клиентами. Например, чат-бот анализирует и сортирует запросы клиентов, автоматически отвечая на распространенные вопросы и перенаправляя сложные запросы в службу поддержки. Эта автоматизация помогает сократить расходы, избавляет агентов от траты времени на избыточные запросы и повышает удовлетворенность клиентов.
Каковы варианты использования НЛП для бизнеса?
Предприятия используют программное обеспечение и инструменты для обработки естественного языка (NLP) для упрощения, автоматизации и рационализации операций эффективно и точно. Ниже мы приводим несколько примеров использования.
Редактирование конфиденциальных данных
Предприятия, работающие в сфере страхования, права и здравоохранения, обрабатывают, сортируют и извлекают большие объемы конфиденциальных документов, таких как медицинские записи, финансовые данные и личные данные. Вместо проверки вручную компании используют технологию NLP для редактирования информации, позволяющей установить личность, и защиты конфиденциальных данных. Например, Chisel AI помогает страховым компаниям извлекать номера полисов, даты истечения срока действия и другие личные атрибуты клиентов из неструктурированных документов с помощью Amazon Comprehend.
Взаимодействие с клиентами
Технологии НЛП позволяют чатам и голосовым ботам быть более похожими на людей при общении с клиентами. Предприятия используют чат-ботов, чтобы масштабировать возможности и качество обслуживания клиентов, сводя к минимуму эксплуатационные расходы. Компания PubNub, которая создает программное обеспечение для чат-ботов, использует Amazon Comprehend для внедрения локализованных функций чата для своих клиентов по всему миру. T-Mobile использует НЛП, чтобы определять определенные ключевые слова в текстовых сообщениях клиентов и предлагать персонализированные рекомендации. Университет штата Оклахома развертывает чат-бот для вопросов и ответов, чтобы отвечать на вопросы студентов с помощью технологии машинного обучения.
Предприятия используют чат-ботов, чтобы масштабировать возможности и качество обслуживания клиентов, сводя к минимуму эксплуатационные расходы. Компания PubNub, которая создает программное обеспечение для чат-ботов, использует Amazon Comprehend для внедрения локализованных функций чата для своих клиентов по всему миру. T-Mobile использует НЛП, чтобы определять определенные ключевые слова в текстовых сообщениях клиентов и предлагать персонализированные рекомендации. Университет штата Оклахома развертывает чат-бот для вопросов и ответов, чтобы отвечать на вопросы студентов с помощью технологии машинного обучения.
Бизнес-аналитика
Маркетологи используют инструменты NLP, такие как Amazon Comprehend и Amazon Lex, чтобы получить обоснованное представление о том, что клиенты думают о продукте или услугах компании. Просматривая определенные фразы, они могут оценить настроение и эмоции клиентов в письменных отзывах. Например, Success KPI предоставляет решения для обработки естественного языка, которые помогают компаниям сосредоточиться на целевых областях при анализе настроений и помогают контакт-центрам получать полезную информацию из аналитики вызовов.
Как работает НЛП?
Обработка естественного языка (NLP) объединяет вычислительную лингвистику, машинное обучение и модели глубокого обучения для обработки человеческого языка.
Компьютерная лингвистика
Компьютерная лингвистика — это наука о понимании и построении моделей человеческого языка с помощью компьютеров и программных средств. Исследователи используют методы вычислительной лингвистики, такие как синтаксический и семантический анализ, для создания структур, которые помогают машинам понимать разговорный человеческий язык. Такие инструменты, как языковые переводчики, синтезаторы текста в речь и программное обеспечение для распознавания речи, основаны на вычислительной лингвистике.
Машинное обучение
Машинное обучение — это технология, которая обучает компьютер с помощью образцов данных для повышения его эффективности. В человеческом языке есть несколько особенностей, таких как сарказм, метафоры, вариации в структуре предложений, а также исключения из грамматики и использования, на изучение которых у людей уходят годы. Программисты используют методы машинного обучения, чтобы научить приложения НЛП распознавать и точно понимать эти функции с самого начала.
Программисты используют методы машинного обучения, чтобы научить приложения НЛП распознавать и точно понимать эти функции с самого начала.
Глубокое обучение
Глубокое обучение — это особая область машинного обучения, которая учит компьютеры учиться и думать, как люди. Он включает в себя нейронную сеть, состоящую из узлов обработки данных, структура которых напоминает человеческий мозг. Благодаря глубокому обучению компьютеры распознают, классифицируют и связывают сложные закономерности во входных данных.
Этапы внедрения НЛП
Обычно внедрение НЛП начинается со сбора и подготовки неструктурированных текстовых или речевых данных из таких источников, как облачные хранилища данных, опросы, электронные письма или внутренние приложения бизнес-процессов.
Предварительная обработка
Программное обеспечение НЛП использует методы предварительной обработки, такие как токенизация, выделение корней, лемматизация и удаление стоп-слов, чтобы подготовить данные для различных приложений.
Вот описание этих методов:
- Токенизация разбивает предложение на отдельные единицы слов или фраз.
- Основы и лемматизация упрощают слова до их корневой формы. Например, эти процессы превращают «запуск» в «запуск».
- Удаление стоп-слов обеспечивает удаление слов, не добавляющих существенного значения предложению, таких как «для» и «с».
Обучение
Исследователи используют предварительно обработанные данные и машинное обучение для обучения моделей НЛП выполнению определенных приложений на основе предоставленной текстовой информации. Обучение алгоритмов НЛП требует загрузки в программное обеспечение больших выборок данных для повышения точности алгоритмов.
Развертывание и вывод
Затем специалисты по машинному обучению развертывают модель или интегрируют ее в существующую производственную среду. Модель НЛП получает входные данные и прогнозирует выходные данные для конкретного варианта использования, для которого предназначена модель. Вы можете запустить приложение НЛП на реальных данных и получить требуемый результат.
Вы можете запустить приложение НЛП на реальных данных и получить требуемый результат.
Что такое задачи НЛП?
Методы обработки естественного языка (NLP), или задачи NLP, разбивают человеческий текст или речь на более мелкие части, которые могут быть легко поняты компьютерными программами. Общие возможности обработки и анализа текста в НЛП приведены ниже.
Тегирование частей речи
Это процесс, при котором программное обеспечение НЛП помечает отдельные слова в предложении в соответствии с их контекстуальным употреблением, например, существительные, глаголы, прилагательные или наречия. Это помогает компьютеру понять, как слова образуют значимые отношения друг с другом.
Устранение неоднозначности смысла слов
Некоторые слова могут иметь разные значения при использовании в разных сценариях. Например, слово «летучая мышь» означает разные вещи в этих предложениях:
- Летучая мышь — ночное существо.
- Игроки в бейсбол бьют по мячу битой.
Благодаря устранению неоднозначности смысла слова программное обеспечение НЛП идентифицирует предполагаемое значение слова либо путем обучения его языковой модели, либо путем обращения к словарным определениям.
Распознавание речи
Распознавание речи преобразует голосовые данные в текст. Процесс включает в себя разбиение слов на более мелкие части и понимание акцентов, оскорблений, интонации и нестандартного использования грамматики в повседневном разговоре. Ключевым применением распознавания речи является транскрипция, которую можно выполнять с помощью сервисов преобразования речи в текст, таких как Amazon Transcribe.
Машинный перевод
Программное обеспечение для машинного перевода использует обработку естественного языка для преобразования текста или речи с одного языка на другой с сохранением контекстуальной точности. Сервис AWS, поддерживающий машинный перевод, называется Amazon Translate.
Распознавание именованных объектов
 Программное обеспечение НЛП использует распознавание именованных объектов для определения отношений между различными объектами в предложении.
Программное обеспечение НЛП использует распознавание именованных объектов для определения отношений между различными объектами в предложении.Рассмотрим следующий пример: «Джейн поехала в отпуск во Францию и побаловала себя местной кухней».
Программное обеспечение НЛП выберет «Джейн» и «Франция» в качестве особых сущностей в предложении. Это может быть дополнительно расширено за счет разрешения совместных ссылок, определяющего, используются ли разные слова для описания одного и того же объекта. В приведенном выше примере «Джейн» и «она» указывают на одного и того же человека.
Анализ настроений
Анализ настроений — это основанный на искусственном интеллекте подход к интерпретации эмоций, передаваемых текстовыми данными. Программное обеспечение НЛП анализирует текст на наличие слов или фраз, выражающих неудовлетворенность, счастье, сомнение, сожаление и другие скрытые эмоции.
Каковы подходы к обработке естественного языка?
Ниже мы приводим некоторые распространенные подходы к обработке естественного языка (NLP).
НЛП с учителем
Методы НЛП с учителем обучают программное обеспечение набором помеченных или известных входных и выходных данных. Сначала программа обрабатывает большие объемы известных данных и учится получать правильные выходные данные из любых неизвестных входных данных. Например, компании обучают инструменты НЛП классифицировать документы в соответствии с определенными метками.
Неконтролируемое НЛП
Неконтролируемое НЛП использует статистическую языковую модель для прогнозирования шаблона, который возникает при подаче немаркированного ввода. Например, функция автозаполнения в текстовых сообщениях предлагает релевантные слова, которые имеют смысл для предложения, отслеживая ответ пользователя.
Понимание естественного языка
Понимание естественного языка (NLU) — это подмножество НЛП, основное внимание в котором уделяется анализу смысла предложений. NLU позволяет программе находить похожие значения в разных предложениях или обрабатывать слова, имеющие разные значения.
Генерация естественного языка
Генерация естественного языка (NLG) фокусируется на создании разговорного текста, как это делают люди, на основе определенных ключевых слов или тем. Например, интеллектуальный чат-бот с возможностями NLG может общаться с клиентами так же, как и персонал службы поддержки.
Как AWS может помочь с вашими задачами НЛП?
AWS предоставляет самый широкий и полный набор сервисов искусственного интеллекта и машинного обучения (AI/ML) для клиентов с любым уровнем знаний. Эти сервисы подключены к обширному набору источников данных.
Для клиентов, которым не хватает навыков машинного обучения, которым нужно ускорить выход на рынок или которые хотят добавить интеллектуальные возможности в существующий процесс или приложение, AWS предлагает ряд языковых сервисов на основе машинного обучения. Это позволяет компаниям легко добавлять интеллектуальные функции в свои приложения ИИ с помощью предварительно обученных API для речи, транскрипции, перевода, анализа текста и функций чат-бота.
Вот список языковых сервисов AWS на основе машинного обучения:
- Amazon Comprehend помогает находить ценные сведения и взаимосвязи в тексте
- Amazon Transcribe выполняет автоматическое распознавание речи
- Amazon Translate свободно переводит текст
- Amazon Polly превращает текст в естественно звучащую речь
- Amazon Lex помогает создавать чат-ботов для взаимодействия с клиентами
- Amazon Kendra выполняет интеллектуальный поиск корпоративных систем, чтобы быстро находить нужный контент
Для клиентов, которые хотят создать стандартное решение для обработки естественного языка (NLP) в своем бизнесе, рассмотрите Amazon SageMaker . SageMaker упрощает подготовку данных, а также создание, обучение и развертывание моделей машинного обучения для любого варианта использования благодаря полностью управляемой инфраструктуре, инструментам и рабочим процессам, включая предложения без кода для бизнес-аналитиков.
С помощью Hugging Face на Amazon SageMaker можно развертывать и настраивать предварительно обученные модели Hugging Face, поставщика моделей НЛП с открытым исходным кодом, известного как Transformers. Это сокращает время, необходимое для настройки и использования этих моделей НЛП, с недель до минут.
Начните работу с NLP, создав аккаунт AWS уже сегодня.
Как работают системы обработки естественного языка?
Время чтения: 5 минут Вероятно, вы уже знаете, что искусственный интеллект и машинное обучение окружают нас повсюду, от телефонов до устройств и огромного количества промежуточных вещей. Но знаете ли вы, какая основная технология позволяет этим устройствам работать эффективно? Это обработка естественного языка или НЛП. Вы когда-нибудь сталкивались с ситуациями, когда вы печатаете что-то на своем смартфоне, и он предлагает варианты слов, основанные на том, что вы сейчас печатаете, и что вы обычно печатаете? Конечно, да, и это система обработки естественного языка в действии. Мы, конечно, упускаем из виду технологию и воспринимаем ее как должное, но в сфере бизнеса это одна из самых больших инноваций, которая изменила всю область.
Мы, конечно, упускаем из виду технологию и воспринимаем ее как должное, но в сфере бизнеса это одна из самых больших инноваций, которая изменила всю область.
Цель этого поста дать вам обзор того, что такое система обработки естественного языка , как она работает и некоторые из ее наиболее распространенных приложений. Давайте углубимся.
1- Что такое система обработки естественного языка? В основе лежит обработка естественного языка . — это подмножество искусственного интеллекта, которое помогает машинам понимать, интерпретировать и манипулировать естественным языком, используемым людьми, например текстом и речью. Его основная цель — заполнить пробелы между компьютерным пониманием и человеческим общением. Обработка естественного языка — это новая технология, которая управляет различными формами искусственного интеллекта, к которым мы привыкли. Хотя обработка естественного языка не является чем-то новым и изучается в течение значительного числа десятилетий, в наши дни она быстро развивается благодаря доступности больших данных, усовершенствованных алгоритмов, мощных вычислений и повышенному интересу к общению между людьми и машинами. .
.
Выполнение обработки естественного языка трудно в основном из-за сложной природы человеческого языка. Всестороннее понимание человеческого языка требует понимания понятий и слов, а также того, как они связаны между собой, чтобы обеспечить желаемые результаты. Хотя мы можем довольно легко освоить язык, неточные характеристики и двусмысленность естественных языков являются двумя самыми важными аспектами, которые делают обработку естественного языка 9.0192 Систему сложно внедрить.
Чтобы понять, как работает система обработки естественного языка, было бы полезно понять, как мы используем язык. Каждый день мы генерируем, например, сотни слов в объявлении, которые интерпретируются другими людьми для выполнения множества задач. Для нас это простое общение, но все знают, что слова имеют более глубокий контекст. Всегда есть какой-то контекст, который мы получаем из того, что мы говорим и как мы это говорим. Всякий раз, когда мы говорим что-то другому человеку, этот человек может понять, что мы на самом деле пытаемся сказать. Причина в том, что люди учатся и развивают способность понимать вещи через опыт. Здесь вопрос в том, как мы можем предложить этот опыт машине. Ответ заключается в том, что нам нужно предоставить ему достаточно данных, чтобы помочь ему учиться на собственном опыте.
Всякий раз, когда мы говорим что-то другому человеку, этот человек может понять, что мы на самом деле пытаемся сказать. Причина в том, что люди учатся и развивают способность понимать вещи через опыт. Здесь вопрос в том, как мы можем предложить этот опыт машине. Ответ заключается в том, что нам нужно предоставить ему достаточно данных, чтобы помочь ему учиться на собственном опыте.
Первый рабочий этап системы обработки естественного языка зависит от приложения системы. Например, голосовые системы, такие как Google Assistant или Alexa, должны переводить слова в текст. Обычно это делается с помощью системы HMM (скрытых марковских моделей). HMM использует математические модели, чтобы определить, что сказал человек, и перевести это в текст, используемый системой обработки естественного языка . Следующим шагом является фактическое понимание контекста и языка. Хотя методы немного отличаются от одного обработки естественного языка на другую, в целом они следуют довольно похожему формату. Системы пытаются разбить каждое слово на его существительное, глагол и т. д. Это происходит с помощью ряда закодированных правил, которые зависят от алгоритмов, включающих статистическое машинное обучение, чтобы помочь определить контекст.
Системы пытаются разбить каждое слово на его существительное, глагол и т. д. Это происходит с помощью ряда закодированных правил, которые зависят от алгоритмов, включающих статистическое машинное обучение, чтобы помочь определить контекст.
Если вы думаете о рабочей процедуре системы обработки естественного языка, отличной от преобразования речи в текст, система пропускает начальный шаг и сразу переходит к анализу слов с использованием алгоритмов и правил грамматики.
Конечным результатом является способность классифицировать то, что человек говорит, разными способами. Результаты используются по-разному в зависимости от основной цели системы обработки естественного языка .
Когда вы изучаете, как работает система обработки естественного языка , также важно получить общее представление о ее ключевых компонентах. Давайте кратко рассмотрим каждый из них.
- Синтаксический анализ: Синтаксис означает расположение слов в предложении таким образом, чтобы они могли иметь грамматический смысл. В обработка естественного языка , синтаксический анализ используется для оценки того, как естественный язык согласуется с грамматическими правилами. Здесь грамматические правила применяются с помощью компьютерных алгоритмов к группе слов, чтобы извлечь из них значение.
- Семантический анализ: Семантический анализ относится к структуре, разработанной синтаксическим анализатором, который присваивает значения. Здесь применяются компьютерные алгоритмы, чтобы понять интерпретацию и значение слов, а также структуру предложений. Важно отметить, что этот компонент только абстрагирует реальное значение или словарное значение от данного контекста.
 В обработка естественного языка , синтаксический анализ используется для оценки того, как естественный язык согласуется с грамматическими правилами. Здесь грамматические правила применяются с помощью компьютерных алгоритмов к группе слов, чтобы извлечь из них значение.
В обработка естественного языка , синтаксический анализ используется для оценки того, как естественный язык согласуется с грамматическими правилами. Здесь грамматические правила применяются с помощью компьютерных алгоритмов к группе слов, чтобы извлечь из них значение.Для реализации системы обработки естественного языка применяются два популярных метода — машинное обучение и статистическая интерференция.
3- Некоторые наиболее распространенные области применения систем обработки естественного языка. Вот некоторые наиболее распространенные области применения этой технологии. 3.1- Чат-боты
3.1- Чат-боты Чат-боты несут большую ответственность за смягчение разочарования клиентов в связи со службой поддержки по телефону. Они предлагают виртуальную помощь для решения простых проблем клиента, где не требуется никаких навыков. В наши дни чат-боты завоевывают большую популярность и доверие как у потребителей, так и у разработчиков.
3.2- Программа языкового переводаОбработка естественного языка системы часто внедряются, чтобы помочь программам языкового перевода, которые могут переводить с одного языка на другой (например, с английского на немецкий). Технология позволяет выполнять элементарный перевод до того, как в дело вступит переводчик-человек. Это сокращает время, необходимое для перевода документов.
3.3- Анализ настроений Здесь системы обработки естественного языка используются для понимания и анализа ответов на деловые сообщения, размещенные на платформах социальных сетей. Это помогает бизнесу анализировать эмоциональное состояние и отношение человека, комментирующего или взаимодействующего с постами. Анализ настроений, широко используемый в социальных сетях и веб-мониторинге, реализуется с использованием комбинации статистики и обработка естественного языка путем присвоения значения текстам и последующей попытки определить настроение, лежащее в основе контекста.
Это помогает бизнесу анализировать эмоциональное состояние и отношение человека, комментирующего или взаимодействующего с постами. Анализ настроений, широко используемый в социальных сетях и веб-мониторинге, реализуется с использованием комбинации статистики и обработка естественного языка путем присвоения значения текстам и последующей попытки определить настроение, лежащее в основе контекста.
Поиск автозаполнение – это еще одно применение обработки естественного языка , которое многие люди используют на регулярной основе. Поисковые системы Интернета и некоторые личные поисковые системы компаний интегрировали это приложение для повышения удобства работы пользователей. Иногда пользователи могут знать только одно ключевое слово, а не весь поисковый запрос или фразу. Автозаполнение поиска помогает им найти правильный поисковый запрос и быстрее получить ответы.
3. 5- Описательная аналитика
5- Описательная аналитика Получение отзывов о продуктах/услугах дает множество преимуществ. С их помощью можно не только повысить доверие потенциальных клиентов, но и активировать рейтинги продавцов. Предприятия используют средства обработки естественного языка, оснащенные , которые могут собирать отзывы потребителей и анализировать их, указывая, как часто упоминаются различные типы плюсов и минусов.
3.6- Автокоррекция поиска – это совершенно нормально делать ошибки при вводе чего-либо и не осознавать этого. Если поисковая система на веб-сайте компании не идентифицирует ошибку и выдает «нет результатов», для потенциальных покупателей естественно предположить, что в магазине нет ответа или информации, которую они ищут. С помощью систем обработки естественного языка вероятность таких случаев может быть уменьшена путем оснащения веб-сайта функцией автозамены при поиске. Он выявляет ошибки и выдает соответствующие результаты, не требуя от пользователей выполнения каких-либо дополнительных действий, как при поиске в Google.
Проверка орфографии является одним из наиболее часто используемых приложений систем обработки естественного языка . Он прост в использовании и может избавить от многих головных болей как агентов, так и пользователей. Не каждый пользователь тратит время на составление грамматически правильных предложений при письме агенту по продажам или в службу поддержки клиентов. С помощью обработки естественного языка, оборудованных контактными формами , предприятия теперь могут сделать жизнь как пользователей, так и руководителей службы поддержки клиентов, потому что сообщения с ошибками не только трудно интерпретировать, но и могут привести к разочарованию и недопониманию для сотрудников. все вовлеченные.
Прощальные мысли В этот момент обработка естественного языка пытается определить нюансы в значении языка, возникающие по разным причинам – от орфографических ошибок или диалектных различий до отсутствия контекста.