Причинно-следственный анализ в машинном обучении / Хабр
Что появилось первым: курица или яйцо?
Статистики давно уже нашли ответ на этот вопрос.
Причем несколько раз.
И каждый раз ответ был разным.
А если серьезно, то для машинного обучения становятся все более актуальными вопросы причинно-следственного анализа (causal inference) — когда главной целью моделирования является не прогноз и его качество, а то, как мы можем принимать решения на основе нашего алгоритма. И как это повлияет на мир, в котором эта модель будет действовать. Сделает ли модель его лучше, чем он был? Или наоборот.
Под катом я расскажу о причинно-следственном анализе, его ключевых методах и применении в машинном обучении. В следующей статье побеседуем о ключевых трендах в развитии методов причинно-следственного анализа в машинном обучении в 2020-2021 гг.
Что такое причинно-следственный анализ
Correlation doesn’t imply causation
Главный тезис эконометрики, который в последние 5 лет прочно пришел и в ML: «Корреляция не подразумевает причинно-следственную связь».
Корреляция — статистическая взаимосвязь двух показателей. Например, вес и рост скоррелированы — обычно более высокие люди весят больше. Но если человек наберет вес или похудеет, его рост не изменится — изменение веса не является причиной изменения роста. При этом если человек вырастет, вес, скорее всего, изменится — изменение роста будет являться причиной изменения веса.
Таким образом, корреляция — это линейная взаимосвязь двух показателей. Если меняется X, то обычно меняется и Y. А причинно-следственная связь показывает, что показатель X вызывает изменение Y или, другими словами, изменение Х является причиной изменения Y.
Вроде все просто и понятно, но, тем не менее, и сейчас, как и многие годы назад, мы продолжаем встречать неожиданные примеры, когда отсутствие внимания к этому тезису приводит к неожиданным проблемам.
Ниже моя подборка примеров.
Пример, который обычно приводится в лекциях на тему correlation doesn’t imply causation – это взаимосвязь покупок мороженого и солнцезащитных очков (иногда очки заменяют печальным показателем — числом утонувших людей).
 Эти показатели значимо скоррелированы, но говорить о причинно-следственной связи нельзя – если мы намеренно начнем есть мороженого больше, покупки солнцезащитных очков не увеличатся. Фактор, который определяет динамику этих показателей – погодные условия. Когда тепло, мы больше едим мороженого, и нам больше нужна защита от солнца.
Эти показатели значимо скоррелированы, но говорить о причинно-следственной связи нельзя – если мы намеренно начнем есть мороженого больше, покупки солнцезащитных очков не увеличатся. Фактор, который определяет динамику этих показателей – погодные условия. Когда тепло, мы больше едим мороженого, и нам больше нужна защита от солнца.В 90-х в рамках осуществлялась оценка применимости ML моделей для снижения издержек на здравоохранение (Cost-Effective HealthCare). По итогам программы нейронные сети значительно превзошли обычные модели (в основном, логрег) по качеству. Но невозможность интерпретировать предсказания нейронных сетей и системно анализировать причинно-следственные связи привело к отказу от их применения для этих задач (на тот момент).
Одной из важнейших задач программы было предсказание вероятности смерти от пневмонии. Цель – госпитализировать только людей с повышенным риском, остальных – лечить амбулаторно, снижая издержки. Rule-based системы для этой задачи показывали, что наличие у человека астмы значительно снижает риск смерти от пневмонии.
Такая закономерность явно наблюдалась в обучающем датасете. Причиной корреляции этих факторов являлось наличие регулярной врачебной помощи. Люди с астмой находились под особым медицинским наблюдением, следовательно, при заболевании пневмонией, были меньше подвержены осложнениям.Наличие в проде неинтерпретируемой ML-модели, выучившей подобную закономерность, привело бы к большим проблемам, чего, к счастью, удалось избежать.
Результаты знаменитого Стенфордского Зефирного эксперимента долгие годы гласили: сила воли ребенка определяет его успешность в будущем (Walter, Shoda, Peake, 1990). Сила воли в эксперименте понималась как способность ребенка удержаться от съедения запретной зефирки на какое-то время, чтобы в итоге получить большее вознаграждение.
Как выяснилось не так давно (Watts, Dunkan, 2018), в этом эксперименте было критическим влияние третьего фактора – успешности и благополучия родителей. Именно этот фактор в данном эксперименте оказывал влияние как на успешность ребенка в будущем, так и на то, способен ли он был удержаться от сладкого.
В более благополучных семьях зефир не являлся для ребенка диковинкой, поэтому и удержаться от того, чтобы его съесть, было проще.Надо сказать, что научный спор вокруг Зефирного эксперимента еще продолжается – если кто-то заинтересовался темой, ключевые вехи дискуссии можно посмотреть тут (2019 г.) и тут (2020 г.).
Серия Смешариков о борьбе с холодом замечательно показывает отличие корреляции от причинно-следственной связи на примере связи примет и изменения погоды. Придет ли весна к тебе быстрее, если прогнать из своего двора всех зябликов, вырубить черемуху и изменить направление дыма из трубы?
Немецкое издание Gawker.com в 2013 г. вольно проинтерпретировало выводы статьи «The Effect of Sexual Activity on Wages». В статье автор нашел значительную корреляцию частоты сексуальных контактов для домохозяйств в Греции и величиной их дохода, но явно уточнил, что исследования на наличие causal взаимосвязи не проводилось. Однако немецкому изданию это не помешало выйти с большими выводами о том, как прийти к высокому доходу в Германии.
 Эти показатели значимо скоррелированы, но говорить о причинно-следственной связи нельзя – если мы намеренно начнем есть мороженого больше, покупки солнцезащитных очков не увеличатся. Фактор, который определяет динамику этих показателей – погодные условия. Когда тепло, мы больше едим мороженого, и нам больше нужна защита от солнца.
Эти показатели значимо скоррелированы, но говорить о причинно-следственной связи нельзя – если мы намеренно начнем есть мороженого больше, покупки солнцезащитных очков не увеличатся. Фактор, который определяет динамику этих показателей – погодные условия. Когда тепло, мы больше едим мороженого, и нам больше нужна защита от солнца. Такая закономерность явно наблюдалась в обучающем датасете. Причиной корреляции этих факторов являлось наличие регулярной врачебной помощи. Люди с астмой находились под особым медицинским наблюдением, следовательно, при заболевании пневмонией, были меньше подвержены осложнениям.
Такая закономерность явно наблюдалась в обучающем датасете. Причиной корреляции этих факторов являлось наличие регулярной врачебной помощи. Люди с астмой находились под особым медицинским наблюдением, следовательно, при заболевании пневмонией, были меньше подвержены осложнениям. В более благополучных семьях зефир не являлся для ребенка диковинкой, поэтому и удержаться от того, чтобы его съесть, было проще.
В более благополучных семьях зефир не являлся для ребенка диковинкой, поэтому и удержаться от того, чтобы его съесть, было проще.
Почему Correlation != Causation
Обсудили, что корреляция не подразумевает причинно-следственную связь. Давайте теперь поговорим о том, почему это может быть так.
Общепринято выделять 4 причины.
Пропущенная переменная (Omitted variable). В случае, если Х и Y скоррелированы, причиной их изменения может быть другой, третий фактор F, воздействие которого и заставляет X и Y двигаться вместе (сонаправленно). Поэтому, если цель нашего исследования – изменить Y, изменение Х нам с этим не поможет. К изменению Y приведет только изменение F.
Выше можно найти ряд примеров, когда причиной корреляция не означает причинно-следственной связи, именно по причине пропущенного фактора. Так, в корреляции наличия астмы и низкой вероятности смерти от пневмонии третьим фактором оказалось регулярное врачебное наблюдение, необходимое при астме и оказывающее значительное влияние на снижение смерти от пневмонии. А для корреляции ЗП и сексуальной активности третьим фактором, по мнению автора исследования, является состояние здоровья.
Обратная причинность (Reverse Causality). Корреляция X и Y не подразумевает, что Х влияет на Y, поскольку влияние может быть обратным – Y влияет на Х. Самым известным примером reverse causality считается взаимосвязь курения и депрессии. Здесь возможна как прямая взаимосвязь (курение способствует депрессии), так и обратная (подавленное состояние способствует курению). Другие примеры из экономической теории: уровень дохода и счастье, бедность и безработица, сексуальная активность и уровень ЗП.
Смещение выборки (Selection bias). Третья возможная причина, почему корреляция не подразумевает причинно-следственной связи – нерепрезентативность выборки, на основе которой мы делаем выводы, для генеральной совокупности. Пример – исследование факторов роста заработной платы. При проведении подобного исследования мы неизбежно рассматриваем только работающих и, следовательно, получающих ЗП на текущий момент людей и делаем выводы о факторах, влияющих на их доход.
При этом в выборку не попадают неработающие люди (потерявшие работу, матери в декрете, официально безработные, и др.), данные о которых могут значимо повлиять на результат.Ошибка измерения (Measurement error). Способ получения данных и его уязвимости также могут влиять на результат. Самый распространенный пример – систематическое искажение данных в опросах. Так, пациенты могут систематически приукрашивать данные о регулярности приема лекарств и занижать – о приеме алкоголя. В опросах про доходы также часто встречается завышение низкого дохода и занижение высокого. Но не каждая ошибка измерения приводит к неверным выводам о причинно-следственной связи. В некоторых случаях она может быть вполне безобидной.
 При этом в выборку не попадают неработающие люди (потерявшие работу, матери в декрете, официально безработные, и др.), данные о которых могут значимо повлиять на результат.
При этом в выборку не попадают неработающие люди (потерявшие работу, матери в декрете, официально безработные, и др.), данные о которых могут значимо повлиять на результат.Определение Causal Inference
Сформулируем определения причинно-следственной связи и эффекта.
Есть два типа определений для CI: определение через воздействие (Intervention – Что случится с Y, если я сделаю Х?) и контрфактическое определение (Counterfactual – Давайте представим мир с Y таким, в котором мы сделали или не сделали Х).
В intervention определении X является причиной Y тогда и только тогда, когда изменение Х влечет за собой изменение Y. Эффектом считается масштаб изменения Y после изменения Х на 1 единицу.
В counterfactual логике X является причиной Y тогда и только тогда, когда мир Y, где присутствует/сделано X отличается от мира Y без Х. Эффектом считается масштаб отличия мира Y в случае присутствия Х от мира Y без Х.
Определение причины и причинно-следственного эффекта в Causal Inference
Методы Causal Inference
Evidence Ladder для систематизации методов causal inference
В различных докладах и статьях по причинно-следственному анализу мне всегда не хватало систематизации методов. Многие причисляют отдельные методы к каким-то категориям, подкатегориям, но общей классификации не дают, и в итоге возникает путаница. Непонятно, как собрать воедино все, что разрабатывается в этой области. Когда начинаешь прицельно искать систематизацию, то оказывается, что их очень много. И у каждой, как водится, свои плюсы и минусы.
И у каждой, как водится, свои плюсы и минусы.
Расскажу вам про лучшую, на мой взгляд, систематизацию – Evidence Ladder от A.Rebecq (2020).
Методы Causal Inference можно упорядочить с помощью так называемой доказательной лестницы (Evidence Ladder). От нижней ступени к верхней будет расти, во-первых, доказательная сила метода, во-вторых, простота применения, или, другими словами, снижаться число необходимых проверок на устойчивость результата применения метода (robustness checks).
На вершине этой лестницы находятся естественные эксперименты (Natural Experiments). Это, например, классические лабораторные эксперименты в физике и химии, когда мы можем создать полностью одинаковые условия для двух вариантов Y, отличающихся только наличием Х. Можно представить себе две одинаковые пробирки в химии (Y), где в одну добавлено какое-либо вещество (X), а в другую – нет. Тогда отличие Y где нет Х от Y с Х и будет выявленным причинно-следственным эффектом. Мы будем абсолютно уверены, что изменение состояния Y вызвано участием Х.
Мы будем абсолютно уверены, что изменение состояния Y вызвано участием Х.
Следующая ступень – статистические эксперименты (Statistical Experiments) aka рандомизированные контролируемые эксперименты (Randomized Controlled Trials) aka АБ-тестирование (AB Testing). Здесь мы не можем обеспечить идеально одинаковые Y, но можем случайным образом собрать выборки объектов Y в пилотную (вводим событие Х) и контрольную (не вводим событие Х) группы таким образом, что размер этих выборок компенсирует различия Y между собой. То есть, пилотная и контрольная выборки должны быть достаточно объемны и однородны, чтобы статистический тест был корректным с точки зрения статистической мощности и значимости. На практике подобные тесты чаще всего возможны в e-commerce, где объектов (клиентов магазина, посетителей сайтов) много.
Если случайный отбор не работает, мы вынуждены спускаться еще на ступень ниже – к квази-экспериментам (Quasi-Experiments). На практике категории статистических экспериментов и квази-экспериментов чаще всего смешиваются, и называются просто АБ-тестами. В квази-экспериментах объекты Y могут существенно отличаться и их общего количества недостаточно, чтобы обеспечить однородные выборки и корректный статистический эксперимент. Поэтому в таких АБ-тестах мы вынуждены прибегать к дополнительным мерам снижения дисперсии типа CUPED и линеаризации, и другим танцам с бубном типа проверок репрезентативности выборки для генеральной совокупности и созданию синтетического контроля при критически малом количестве объектов. В АБ-тестах для офлайн-бизнеса чаще всего возможно применение только квази-экспериментов, вследствие малого количества объектов, на которых мы можем позволить себе проведение пилота (долго, дорого, трудно).
В квази-экспериментах объекты Y могут существенно отличаться и их общего количества недостаточно, чтобы обеспечить однородные выборки и корректный статистический эксперимент. Поэтому в таких АБ-тестах мы вынуждены прибегать к дополнительным мерам снижения дисперсии типа CUPED и линеаризации, и другим танцам с бубном типа проверок репрезентативности выборки для генеральной совокупности и созданию синтетического контроля при критически малом количестве объектов. В АБ-тестах для офлайн-бизнеса чаще всего возможно применение только квази-экспериментов, вследствие малого количества объектов, на которых мы можем позволить себе проведение пилота (долго, дорого, трудно).
Иногда бизнес-ограничения не позволяют добиться и корректной оценки даже с помощью квази-экспериментов. В таком случае, мы вынуждены спуститься в самый низ нашей доказательной лестницы – к контрфактическим методам (Counterfactuals). Тут мы отказываемся от идеи пилотной и контрольной групп (на самом деле, не совсем), и, по сути, моделируем временной ряд Y по историческим данным без участия Х в будущее, где Х уже вступает в игру. Таким образом, в период проведения эксперимента мы сможем сравнить фактические данные Y (где Х участвовал) с модельными (прогноз Y без участия Х) и предположить размер эффекта, скорректировав его на точность модели для Y. Однако, чтобы это предположение оказалось близким к правде, нам нужно сделать наибольшее количество тестов на устойчивость метода. Результирующий эффект будет критически зависеть не только от качества модели, но и в целом от корректности применения выбранного метода CI категории Counterfactuals: от выбора самого метода до подбора гиперпараметров и учета при моделировании всех необходимых ковариатов (факторов, помимо Х).
Таким образом, в период проведения эксперимента мы сможем сравнить фактические данные Y (где Х участвовал) с модельными (прогноз Y без участия Х) и предположить размер эффекта, скорректировав его на точность модели для Y. Однако, чтобы это предположение оказалось близким к правде, нам нужно сделать наибольшее количество тестов на устойчивость метода. Результирующий эффект будет критически зависеть не только от качества модели, но и в целом от корректности применения выбранного метода CI категории Counterfactuals: от выбора самого метода до подбора гиперпараметров и учета при моделировании всех необходимых ковариатов (факторов, помимо Х).
На практике необходимость в counterfactual методах возникает не так уж и редко. Например, построили mvp по какому-то проекту (не обязательно ML), прикинули в уме, что вроде норм, взяли и раскатали в прод сразу на все объекты Y. Как теперь оценить эффект от внедрения, если контрольной группы нет в принципе, а на объекты Y ежедневно воздействует миллион внешних факторов: от макроэкономических трендов до внутренних изменений в бизнес-процессах? Знакомо?
Или другой случай: бюджета проекта хватает только на один объект Y, а эффект оценить хочется.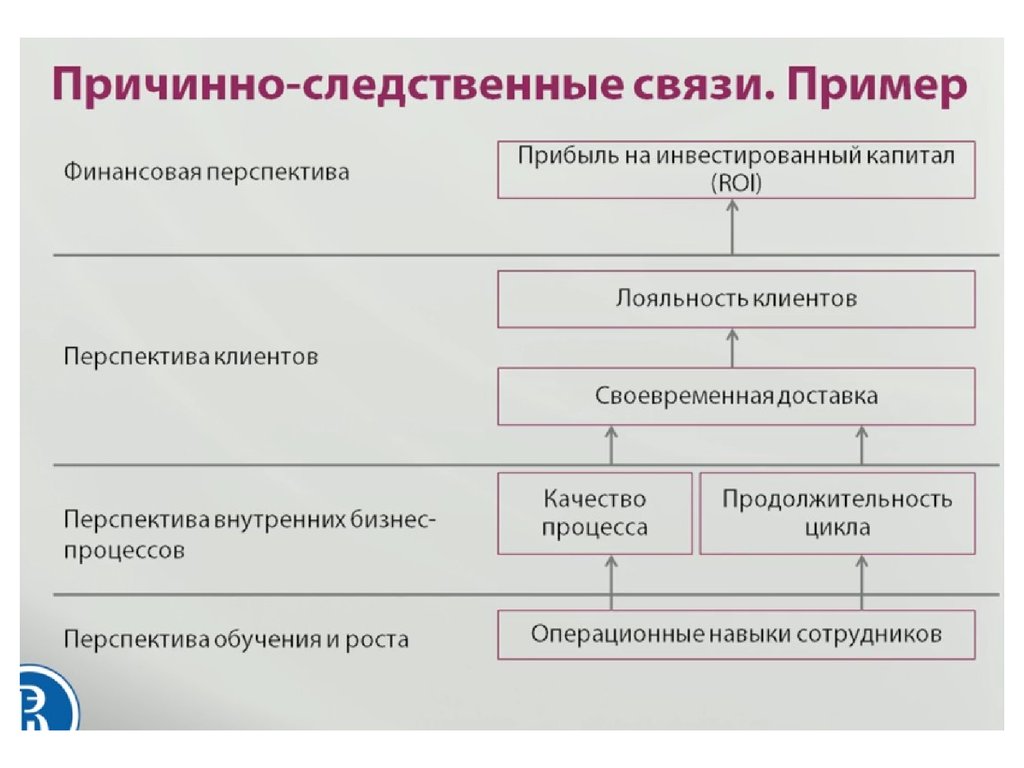 Как ни мучайся, подбирая синтетический контроль из множества других объектов Y, сделать это почти невозможно.
Как ни мучайся, подбирая синтетический контроль из множества других объектов Y, сделать это почти невозможно.
Ну и третий случай: мы хотим на исторических данных, там, где никакого эксперимента не проводили, понять, а был ли эффект от какого-то действия/события Х на целевую переменную Y. В последнем случае, мы чаще всего не можем собрать корректные контрольную и тестовую группы, историческое событие Х чаще всего распределено сложно, внедрялось либо во всех объектах, либо в малом количестве и в разное время.
Доказательная лестница (Evidence Ladder) в причинно-следственном анализеСистематизация методов Causal Inference. Более детальное описание каждой ступени можно найти в моем докладе тут.
Применение методов Causal Inference
Потребность в применении методов причинно-следственного анализа развивается со временем. В начале она была сконцентрирована, в основном, в науках: социальных науках, экономике, медицине, биологии, генетике. В последние пять лет наблюдается резкий рост этой потребности для бизнеса. Основными отраслями применения методов являются IT-компании, игровая индустрия, ритейл и e-commerce. Ключевыми используемыми методами являются АБ-тесты, но с каждым годом встречается все больше отдельных интересных кейсов. Часто эти кейсы возникают из проблем применения классического ML для задач, когда мы хотим управлять параметрами моделей, тем самым, меняя целевую переменную Y. К этой категории можно отнести истории про исключение эффекта эндогенности при исследовании эффекта изменения цен на выручку при динамическом ценообразовании, оценку реального причинно-следственного эффекта изменения параметров персональной промо-кампании на выручку, которую она генерирует (uplift-модели), повышение эффективности работы прокатного стана за счет управления параметрами его работы, оценка эффекта генерации дополнительного спроса от установки различных видов прилавков (мясо, рыба, хлеб, и др.) в продуктовых магазинах.
Основными отраслями применения методов являются IT-компании, игровая индустрия, ритейл и e-commerce. Ключевыми используемыми методами являются АБ-тесты, но с каждым годом встречается все больше отдельных интересных кейсов. Часто эти кейсы возникают из проблем применения классического ML для задач, когда мы хотим управлять параметрами моделей, тем самым, меняя целевую переменную Y. К этой категории можно отнести истории про исключение эффекта эндогенности при исследовании эффекта изменения цен на выручку при динамическом ценообразовании, оценку реального причинно-следственного эффекта изменения параметров персональной промо-кампании на выручку, которую она генерирует (uplift-модели), повышение эффективности работы прокатного стана за счет управления параметрами его работы, оценка эффекта генерации дополнительного спроса от установки различных видов прилавков (мясо, рыба, хлеб, и др.) в продуктовых магазинах.
В целом, о кейсах бизнес-применения causal inference 2021 г. я рассказывала в одном из постов tg-канала @Reliable_ML еще в начале года.
Causal Inference и Machine Learning
Causal Inference как ключ к балансу классического ML и эконометрики
На мой взгляд, который озвучивала еще в 2019 г., data science можно определить через сближение дисциплин эконометрики и машинного обучения.
Основой моделирования для классического машинного обучения является качество прогноза. Вопросы интерпретируемости модели при этом вторичны. В начале развития ML стремление к интерпретируемости модели воспринималось, скорее, негативно – как упрощение модели в жертву способности ее интерпретировать.
Эконометрика – статистическая наука, основой которой является интерпретируемость. При этом во время становления дисциплины машинного обучения, когда в моду вошли слова data mining, эконометристы воспринимали их также с негативным окрасом. Мы добиваемся роста метрик качества, используя любые преобразования данных, не понимая логику модели – как она в действительности принимает решения.
При этом постепенно происходило сближение этих дисциплин в науку о данных – data science. Можно обозначить ее как гармонию принципов классического ML и эконометрики. Интерпретируемость здесь трактуется как необходимость принятия моделей бизнесом, но она не должна быть абсолютной и не должна снижать качество прогноза.
В 2021 г. вышла статья Judea Pearl с более глубокой проработкой идеи роли Causal Inference в ML. В ней автор определяет data science как объединение дисциплины машинного обучения как школы радикального эмпиризма (когда только данные генерируют модель реальности) и эконометрики как школы интерпретации данных (когда модель процессов/реальности генерирует данные). Методы CI в данном случае выступают ключом к балансу эмпиризма и интерпретируемости в DS.
Этот баланс достигается с помощью трех ключевых принципов:
Целесообразности. Модели реальности и Causal Inference помогают ускорить эволюцию ML-моделей. Так при резком появлении в нашей жизни COVID-19 отсутствие фактических исторических данных не дало бы возможность строить модели машинного обучения с прогнозами развития и принимать какие-либо решения.
Развитию моделей помогли теоретические модели о принципах развития пандемии, которые объединялись с доступными историческими данными. Таким образом, модели быстро эволюционировали.Прозрачности. Использование инструментов и принципов причинно-следственного анализа критически полезно для управления процессами исследования и интерпретации данных.
Объяснимости. Модель должна быть полезна конечному пользователю.
Causal Inference как ключ к балансу классического ML и эконометрики
 Развитию моделей помогли теоретические модели о принципах развития пандемии, которые объединялись с доступными историческими данными. Таким образом, модели быстро эволюционировали.
Развитию моделей помогли теоретические модели о принципах развития пандемии, которые объединялись с доступными историческими данными. Таким образом, модели быстро эволюционировали.Causal Inference в ML
В 2020 году в отчете State of AI впервые в явном виде была обозначена необходимость интеграции классического ML c методами Causal Inference.
Yoshua Bengio и Yann LeCun отметили, что ML-системы, построение которых основано на корреляциях, часто не справляются с задачами в реальном мире. Это происходит вследствие того, что реальный мир отличается от данных для обучения модели:
Мир не является статичным.
Условия, в которых работает модель, постоянно меняются. Если модель опирается на причинно-следственные связи, а не на корреляции, она будет более устойчива к изменениям.Параметры модели могут влиять на изменение целевой переменной, а целевая переменная, в свою очередь, может влиять на параметры модели. Так, цены влияют на спрос на товар, а спрос влияет на цены. С таким явлением также помогают бороться методы причинно-следственного анализа. Например, инструментальные переменные.
Работа модели в продуктиве/реальном мире может менять закономерности, которые были выучены на исторических данных. Особенно уязвимы к этому системы, основанные на корреляциях. Так, в примере про высокую корреляцию вероятности умереть от пневмонии и наличия астмы, если в продуктиве мы будем меньше лечить тех, кто болен астмой, то вскоре кардинально поменяем ситуацию.
 Условия, в которых работает модель, постоянно меняются. Если модель опирается на причинно-следственные связи, а не на корреляции, она будет более устойчива к изменениям.
Условия, в которых работает модель, постоянно меняются. Если модель опирается на причинно-следственные связи, а не на корреляции, она будет более устойчива к изменениям.Решением указанных выше проблем ученые считают применение методов Causal Inference в ML. Обозначают это как путь к новому витку усиления ML-алгоритмов за счет повышения обобщающей способности моделей, их устойчивости и применимости для процесса принятия решений.
Causal Inference в ML: материалы
Материалы, систематизирующие методы causal inference в ML:
Causal Inference Book. Это очередное обновленное издание замечательной фундаментальной книги по causality от Hernan & Robins. На Data Fest 2020 Антон Лебедевич в своем докладе разбирал основные интересные примеры из этой книги.
A Survey on Causal Inference — Liuyi Yao et al. (2020). В этой статье авторы сравнивают по единому фреймворку ключевые существующие (и главное, применяемые на практике) методы Causal Inference, обсуждают тонкости их применения в R/Python.
Материалы по обобщающим Causal Inference фреймворкам:
Библиотека DoWhy для python с различными датасетами, специально собранными или разработанными для тестирования, сравнения и бенчмаркинга различных методов causal inference. Если вы утром за чашечкой чая вдруг придумали новый метод причинно-следственного анализа, то вам дорога к этой библиотеке, чтобы понять, насколько ваш метод конкурентоспособен среди остальных.
Подробнее про библиотеку и ее возможности можно почитать тут.Auto Causal Inference. Попытка создания AutoCI — один из трендов, возникших в рамках интеграции Causal Inference c машинным обучением. Можно ли, только загрузив датасет в библиотеку, понять структуру данных, существующие взаимосвязи и выбрать наилучший метод для из анализа, или для коррекции предсказаний модели, чтобы были учтены необходимые causal inference взаимосвязи? Пока исследования в данном направлении далеки от финальной стадии, но одна из его важных вех этого процесса – публикация от Netflix 2020 г. по Computational Causal Inference.
Proximal Causal Inference – о возможностях непараметрической и полупараметрической оценки причинно-следственного эффекта, на примере медицинских исследований.
Spatial Causal Inference – обзор методов для выявления причинно-следственных эффектов на пространственных данных.
Causal Inference using DL – фреймворк для выявления причинно-следственного эффекта с помощью DL.
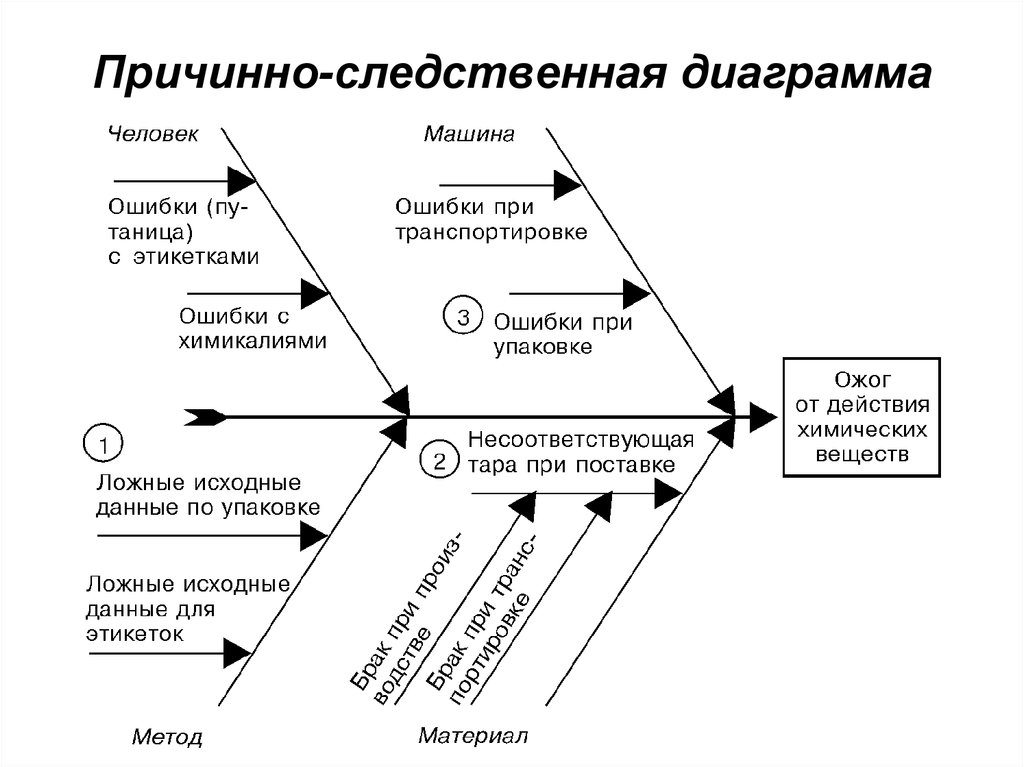 Подробнее про библиотеку и ее возможности можно почитать тут.
Подробнее про библиотеку и ее возможности можно почитать тут.
Causal Inference в ML: инструменты
Tool Boxes для Python:
Dowhy — Propensity-based Stratification, PSM, IPW, Regression
Causal ML — Tree-based algorithms, X/T/X/R-learner
CausalNex — Structural Causal Models based on Bayesian Networks
EconML — Doubly Robust Learner, Orthogonal Random Forests, Meta-Learners, Deep Instrumental Variables
causalImpact — Bayesian structural time-series model (сейчас активна реализация c бекендом на tensorflow-probability вместо pystan)
Tool Boxes для R:
causalToolbox — BART, Causal Forest, T/X/S-learner with BART/RF as base learner
causalImpact — Bayesian structural time-series model
did — Classical Difference-in-Difference (group-time average treatment effects)
synthdid — Synthetic difference in difference estimator (SDID) for the average treatment effect in panel data, Arkhangelsky et al (2019) – доклад на Causal Inference in ML Track 2020
causalweight — Inverse probability weighting (IPW)
Выводы: Causal Inference в ML как часть концепции Reliable ML
Итак, в наши дни направление causal inference прочно вошло в развитие машинного обучения. По сути, стало частью большой концепции под названием Reliable ML.
По сути, стало частью большой концепции под названием Reliable ML.
Концепция Reliable ML – это о том, что делать, чтобы результат работы data science/big data команд был, во-первых, применим в бизнес-процессах компании-заказчика, а, во-вторых, приносил этой компании пользу.
Что для этого нужно?
Уметь составлять грамотный план исследования и развития продукта, учитывающий дальнейшее применение модели.
Различать подходы, направленные на прогноз и на управление параметрами модели в дальнейшем для изменения ее результата (например, управление периодом и форматом проведения промо-активностей для максимизации выручки компании). Для второй цели – которая на практике встречается гораздо чаще просто прогноза – важно ориентироваться в подходах причинно-следственного анализа.
Принимать взвешенные решения о дальнейшем развитии проекта и его потенциальном финансовом эффекте. Для этого необходимо не только проработать качественный дизайн пилотного эксперимента для вашей модели, но и затем сделать корректную статистическую оценку эффекта пилота, а также расчет ожидаемого финансового эффекта.
Уметь интерпретировать работу и результат модели как для технической команды, так и для конечного пользователя (бизнеса).
Уметь выбрать не только корректные технические метрики качества для решаемой задачи, но и сформулировать правильные бизнес-метрики, связанные с процессом применения модели, связать их с техническими метриками и итоговым финансовым результатом применения модели.

Таким образом, концепция Reliable ML охватывает не только технические особенности ML, но и построение процессов работы DS и взаимодействия с бизнесом для достижения максимального финансового эффекта.
Data Fest 3.0 — Reliable ML — Call for presentations
В этом году — 21 мая 2022 г. — состоится Data Fest 3.0 — крупнейшая конференция крупнейшего русскоязычного сообщества Open Data Science в области анализа данных. Конференция будет онлайн, о деталях проведения скоро будет известно.
А сейчас хотелось бы объявить сбор заявок на доклады по теме Reliable ML. Форма для заявок вот тут.
Форма для заявок вот тут.
Будем рады, если сможете рассказать об интересных теоретических аспектах, или о кейсах применения в бизнесе по следующим темам:
Планирование исследований и развития продукта – #planning
Причинно-следственный анализ в машинном обучении – #causal_inference
АБ-тестирование – #ab_testing
Управление рисками инвестиционных инициатив – #investment_process
Интерпретация моделей – #interpretable_ml
Выбор технических и бизнес-метрик для оценки качества моделей — #metrics
Обо всех составляющих концепции Reliable ML можно прочитать в телеграм-канале @Reliable ML. Эта статья была также собрана из серии постов в канале.
Почему? Новая наука о причинно-следственной связи. Джуда Перл, Дана Маккензи», Smart Reading – Литрес
Оригинальное название:
The Book of Why: The New Science of Cause and Effect
Авторы:
Judea Pearl, Dana Mackenzie
Тема:
Менеджмент
Правовую поддержку обеспечивает юридическая фирма AllMediaLaw
www. allmedialaw.ru
allmedialaw.ru
Чтобы наконец-то понять, вреден ли кофе
«Почему? Новая наука о причинно-следственной связи» – это адаптированный для широкой публики вариант научных публикаций Джуды Перла. Зачем читать популярное нечто о статистике? Причина чисто шкурная (в прямом смысле слова): мы регулярно сталкиваемся с тем, что «британские ученые установили», «британские ученые опровергли то, что они же установили днем ранее» или «британские ученые придерживаются прямо противоположных точек зрения». Все бы ничего, если бы эти «открытия» не касались продуктов регулярного использования (например, кремов и сывороток для лица) или оценки наших ежедневных действий (бегать утром или вечером, бег или качалка – что лучше?). Чтобы из вороха информации выделять более надежные источники, необходимо понимать статистические принципы «правильных» исследований. А в случае полного разочарования от противоположных мнений ученых – методологические причины этого.
Другие два момента: моделирование причинно-следственных связей сверхважно для развития искусственного интеллекта, поэтому теоретические разработки в этой области примерно указывают на логику, которой будет следовать развитие искусственного интеллекта (а нам всем все же интересно, когда уже нас заменят роботы). Также книга дает представление о теоретической дискуссии внутри статистики как науки.
Также книга дает представление о теоретической дискуссии внутри статистики как науки.
Учитывая все это, утверждать, что книга читается легко, конечно, нельзя. Но все-таки, когда привыкаешь к формулам (полностью без них у авторов не получилось), чтение становится приятным. Также нельзя не отметить: автор не очень тактично отзывается о многих ученых, занимавшихся статистикой.
Несколько слов об искусственном интеллекте: Джуда Перл убежден, что развитие искусственного интеллекта на базе причинно-следственных связей – единственно верный путь. Его преимущество перед глубинным обучением состоит в том, что причинно-следственные связи прозрачны, а глубинное обучение – нет. Так, хотя разработанная Google программа AlphaGo побеждает профессиональных игроков в го, что казалось невозможным (в отличие от шахмат, там слишком много вариантов и их невозможно все выучить), разработчики не знают, как она работает. Джуда Перл уверен, что роботы должны понимать сослагательное наклонение, ведь только оно позволяет коммуницировать с людьми и гарантирует возможность обучения на прошлых ошибках.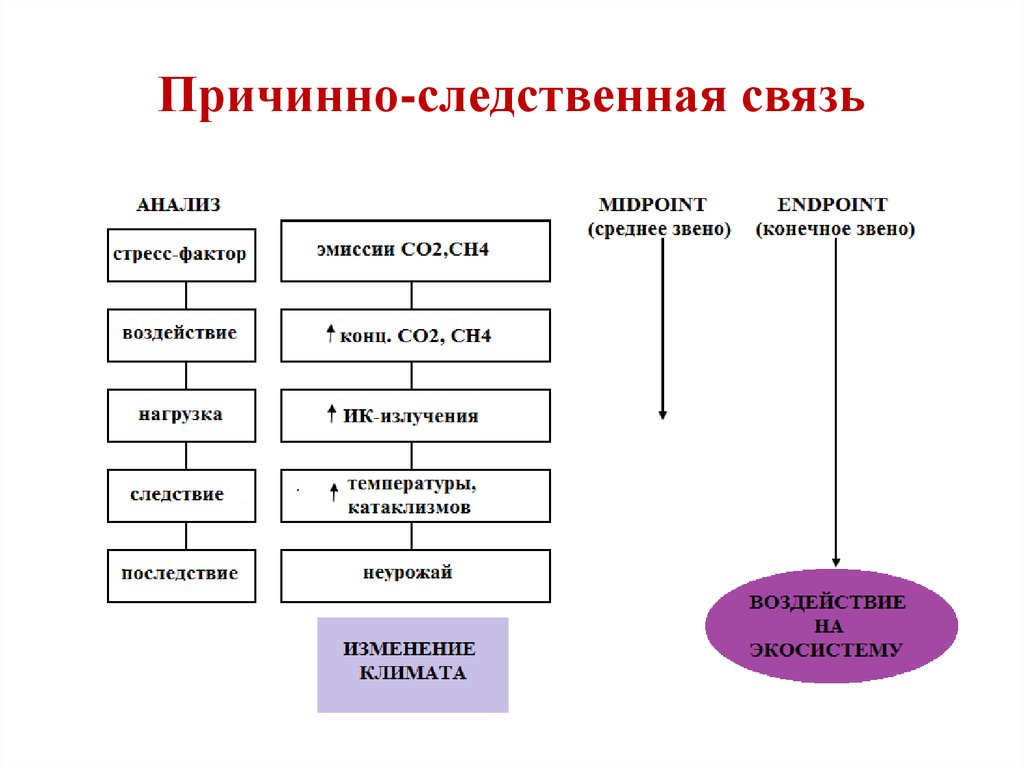
Чем не устраивает обычная статистика?
Традиционные статистические методы в целом показывают корреляцию, но не причинно-следственные связи. Эту истину вдалбливают в голову всем студентам на курсах статистики. Традиционные методы статистики позволили выявить множество закономерностей, но они серьезно ограничивают возможности познания мира в XXI веке. Ведь корреляция порой не только вводит нас в заблуждение (песни петуха на заре никак не причина восхода солнца), но и не позволяет ответить на такие вопросы: «Какова основная причина выздоровления пациента?», «Что было бы, если бы население резко сократило потребление алкоголя?», «Что будет, если изменить налоговую ставку?». И множество других, для получения ответа на которые невозможно провести эксперимент с контрольной группой. (Последнее стало стандартом в медицине и постепенно распространяется и в других областях.)
Отсутствие понятийного аппарата для отражения причинно-следственных связей – основная причина этого положения. При этом вопросы из серии «Что, если?» – неотъемлемая часть нашего мышления. Во всех областях жизни мы руководствуемся именно анализом происходящего и размышлениями о том, что будет, если поступить так или иначе. Воображение – важнейший фактор формирования человека и развития общества, как показал Юваль Харари в своей книге «Sapiens. Краткая история человечества».
При этом вопросы из серии «Что, если?» – неотъемлемая часть нашего мышления. Во всех областях жизни мы руководствуемся именно анализом происходящего и размышлениями о том, что будет, если поступить так или иначе. Воображение – важнейший фактор формирования человека и развития общества, как показал Юваль Харари в своей книге «Sapiens. Краткая история человечества».
Чтобы обогатить статистический аппарат, Джуда Перл предлагает диаграммы со стрелками (ниже мы расскажем о них подробно). Пункт X и пункт Y соединены стрелкой, острие которой указывает, какой показатель «прислушивается» к другому. Джуда Перл не был первым, кто графически представил взаимосвязь двух событий. Причинно-следственная революция проходила постепенно на протяжении более чем полувека.
Благодаря стрелкам – это новшество лишь на первый взгляд кажется дребеденью, но по факту требует нетривиальных логических способностей (не расслабляйтесь) – анализ вышел на новый, третий уровень. Лестница показывает предыдущие два: первый – это корреляция, мы лишь наблюдаем за происходящим (да, анализ больших данных и искусственный интеллект находятся на нем), на следующем уровне мы задумаемся о последствиях своих действий, то есть вмешиваемся (здесь расположены исследования с контрольными группами), на третьем – переход к сослагательному наклонению, когда для ответа на вопрос «Что, если?» требуются лишь данные и стрелочки, искусно помноженные на привычные статистические методы.
Causal: Платформа бизнес-планирования
🚀 Мы только что запустили Causal for Startups, новый продукт для начинающих компаний! Нажмите сюда, чтобы проверить это.
Спасибо! Ваша заявка принята!
Ой! Что-то пошло не так при отправке формы.
Посмотреть демонстрацию
Гибкое моделирование
Хватит возиться со ссылками на ячейки и неверными формулами.
Все, что вы можете делать в Excel, вы можете делать и в Causal, используя в 10–100 раз меньше формул. Чем меньше формул, тем меньше ошибок, а наш естественный язык формул позволяет вашей команде проверять модели за считанные секунды.
ПЛАНИРОВАНИЕ СЦЕНАРИЙ
Запуск сценариев «что, если» в режиме реального времени.
Настройка неограниченного количества сценариев на основе драйверов, автоматически управляемых Causal. Для неуверенных драйверов используйте диапазоны («от 5 % до 10 %) и просмотрите весь диапазон возможных результатов.
Любимец людей по всему миру
Послушайте, что наши пользователи говорят о Causal
Если вы когда-нибудь занимались моделированием/прогнозированием — я серьезно не могу рекомендовать @CausalHQ достаточно. Это такой отличный продукт.
Это такой отличный продукт.
Объединение вероятностных моделей с @CausalHQ чертовски футуристично.
Вчера вечером я писал спецификацию проекта. CAC против цены и коэффициента конверсии — причинно-следственные связи.
В течение 45 м я детально изучал сценарии, опираясь на данные.
Самая безумная часть? Он встраивается в Notion 🤯
Да, я построил МНОГО финансовых моделей в свое время, и @CausalHQ просто упростил создание одной с нуля. НАМНОГО проще, чем мои электронные таблицы. Я одержим!
Играл с @CausalHQ в течение последнего часа или около того, и я очень впечатлен простотой, но продуманностью функций и взаимодействий. Отличная работа!
Я использовал @CausalHQ в течение последних двух недель, чтобы перестроить нашу финансовую модель, и это такой глоток свежего воздуха по сравнению с хрупкими статическими моделями, которые я в итоге создал в Excel/Таблицах.
Подготовка финансовой модели для Daybridge в @CausalHQ, и я должен сказать, что это феноменальная программа с огромным потенциалом. Волшебно наблюдать, как вещи перезагружаются в режиме реального времени. Мне нужно знать их технологический стек!
Волшебно наблюдать, как вещи перезагружаются в режиме реального времени. Мне нужно знать их технологический стек!
Нужно построить модель? Этот продукт потрясающий.
👊👊 @CausalHQ
На демо с @CausalHQ через @makerpad
Это меняет правила игры в моделировании. Финансовые директора и менеджеры по проектам будут грызть бит, чтобы заполучить его.
👏
Скорость улучшения продукта от @CausalHQ невероятна.
Classdojo запускает в нем все прогнозы, сценарии и финансовое планирование, без единого FTE в функции 🤯
Я немного увлекаюсь электронными таблицами/моделированием, и я был очень впечатлен @CausalHQ. Среди прочего, я думаю, мы перестроим динамическую версию нашего калькулятора безубыточности основателя. Должно быть весело.
Людям, которые любят математику и не умеют кодировать, стоит попробовать @CausalHQ. Я чувствую себя специалистом по данным, использующим его, хотя на самом деле я не специалист по данным и не ученый.
Если вы еще не проверили @CausalHQ, это невероятный способ создавать обновляемые в реальном времени прогнозы с помощью встроенных инструментов для моделирования неопределенности
Одно из моих любимых веб-приложений: http://causal. app
app
Quickly легко создавать финансовые модели + автоматически создавать динамические презентации на основе этих моделей. Блестящая работа @CausalHQ
Настоятельно рекомендуем @CausalHQ для интерактивного финансового моделирования. для любого моделирования.
глоток свежего воздуха от попыток сделать эти вещи в Excel
Превратите свою финансовую команду в настоящего делового партнера.
Мы помогли сотням компаний оптимизировать процессы планирования и анализа. Мы хотели бы сделать то же самое для вас.
Заказать демонстрацию
Careers – Causal
Мы привлекли 20 млн долларов США серии А под руководством Coatue + Accel! Нажмите здесь, чтобы прочитать объявление.
КАРЬЕРА
Присоединяйтесь к нам, поскольку мы строим будущее электронных таблиц
Наша миссия состоит в том, чтобы помочь людям использовать числа, чтобы вместе принимать лучшие решения. Нам предстоит многое сделать, пока мы создаем Causal, чтобы он стал де-факто инструментом для работы с числами — мы будем рады вашей помощи.
Просмотреть все открытые роли
ЖИЗНЬ В КАУЗАЛЕ
Наши ценности
Внешнее превосходство
Наша работа, обращенная наружу, должна быть красивой. Мы гордимся дизайном нашей продукции, маркетинговыми материалами, письменным содержанием и взаимодействием с клиентами.
Склонность к действию + обучение
Мы подходим к новым задачам с установкой на рост и верим в свою способность «разобраться». Мы быстро запускаем первоначальные версии проектов и итерируем их.
Автономия + Собственность
Мы возлагаем на нашу команду ответственность за свою работу. Мы ценим сотрудничество, но считаем, что у всех проектов должны быть определенные владельцы, которые несут ответственность за их успех.
Прозрачность
Мы принимаем решения открыто, чтобы обеспечить полный бизнес-контекст в организации. Мы приветствуем откровенные отзывы друг о друге и используем их, чтобы сделать нас лучше.
Доброта + Смирение
Мы относимся к людям с сочувствием и заботимся о чувствах друг друга.
 Мы действуем в интересах Causal и оставляем свое эго за дверью.
Мы действуем в интересах Causal и оставляем свое эго за дверью.КАРЬЕРА
Открытые вакансии в Causal
Мы активно набираем сотрудников во все команды компании. Если какая-либо из ролей ниже выглядит интересной, мы будем рады услышать от вас!
Инжиниринг
Инженер пользовательского интерфейса
Мы ищем инженеров по интерфейсу/полному стеку для ускорения разработки нашего продукта. Нам приходится решать различные сложные инженерные/UX проблемы: — Наш внешний интерфейс, похожий на электронные таблицы: этот интерфейс сопряжен с множеством задач UI/UX для поддержки сложной функциональности, не будучи сложным, и должен быть невероятно производительным. Causal нужен низкий пол и высокий потолок — он должен быть достаточно простым, чтобы с ним мог начать каждый, но достаточно мощным для действительно сложных случаев использования. — Наши возможности инструментальной панели и визуализации данных: мы должны позволить пользователям создавать красивые диаграммы и таблицы для связи с числами.

Подать заявку
Удаленный
Инженер по работе с клиентами
Мы ищем активного и динамичного специалиста по решению проблем, который поможет нам продолжать предоставлять лучшую в своем классе поддержку для клиентов Causal! Как один из первых членов нашей группы поддержки клиентов, инженер по работе с клиентами будет устранять проблемы с моделированием, отвечать на запросы клиентов, проводить расследования и многое другое. Вы будете первой линией защиты, которая гарантирует, что проблемы клиентов не просто будут решены, а превратятся в положительные эмоции, ведущие к потенциальному росту. Это важная роль, которая отлично подходит для людей, которые хотят познакомиться со всеми областями причинно-следственной связи. Вы не только станете техническим экспертом по лучшему в своем классе продукту, но и станете ключевой частью линии связи между клиентами и нашей командой. Если это звучит интересно для вас, то я хотел бы поболтать! -Адам, вице-президент GTM
Применить
Удаленный (США, Великобритания, Канада)
Инженер по продукту
Мы ищем старших инженеров по продуктам, которые помогут нам создать наиболее гибкий и простой в использовании инструмент для обработки чисел.
 Нам приходится решать различные сложные инженерные/UX-проблемы: Наш внешний интерфейс, похожий на электронные таблицы: этот интерфейс сопряжен с множеством задач UI/UX для поддержки сложной функциональности, не будучи сложным, и должен быть невероятно производительным. Causal нужен низкий пол и высокий потолок — он должен быть достаточно простым, чтобы с ним мог начать каждый, но достаточно мощным для действительно сложных случаев использования. Наши возможности инструментальной панели и визуализации данных: мы должны позволить пользователям создавать красивые диаграммы и таблицы для связи с числами. Я хотел бы пообщаться, если вы готовы принять вызов! Лукас (технический директор)
Нам приходится решать различные сложные инженерные/UX-проблемы: Наш внешний интерфейс, похожий на электронные таблицы: этот интерфейс сопряжен с множеством задач UI/UX для поддержки сложной функциональности, не будучи сложным, и должен быть невероятно производительным. Causal нужен низкий пол и высокий потолок — он должен быть достаточно простым, чтобы с ним мог начать каждый, но достаточно мощным для действительно сложных случаев использования. Наши возможности инструментальной панели и визуализации данных: мы должны позволить пользователям создавать красивые диаграммы и таблицы для связи с числами. Я хотел бы пообщаться, если вы готовы принять вызов! Лукас (технический директор)Подать заявку
Удаленный (США, Великобритания, Канада)
Backend Engineer — Data
Мы ищем frontend/backend/full-stack инженеров для ускорения разработки нашего продукта. Нам приходится решать различные сложные инженерные/UX-проблемы: масштабировать наш вычислительный движок: наш вычислительный движок выполняет расчеты для причинно-следственных моделей — задача состоит в том, чтобы показать пользователю мгновенные результаты, когда это возможно, и выполнить сложные операции (моделирование Монте-Карло, вызовы API) .
