Рекомендация: Обобщение
| Связанные элементы |
|
|---|
ОбобщениеМногие вещи в реальной жизни обладают общими. Например, и кошки, и собаки — животные. У объектов также могут быть общие свойства, которые можно выделить с помощью обобщения между их классами. Выделение общих свойств в отдельные классы упростит процесс изменения системы и управление ею в будущем. Обобщение подразумевает, что один класс наследует свойство другого класса. Наследующий класс называется потомком.
Класс, свойства которого наследуют, называется предком. Наследование означает, что определение предка, включая все его
свойства (атрибуты, отношения или операции его объектов) также верно и для объектов потомка. Обобщение можно выполнять в несколько стадий, что позволяет моделировать сложные многоуровневые иерархии наследования. Общие свойства располагаются в верхних уровнях иерархии, а специальные — в нижних. Другими словами, с помощью обобщения можно моделировать концепции более общего характера. Пример В системе по переработке отходов все классы (Консервная банка, Бутылка и Ящик) описывают разные типы отходов. Они обладают двумя общими свойствами — высотой и массой. С помощью атрибутов и операций эти свойства можно оформить в виде отдельного класса Отходы. Классы Консервная банка, Бутылка и Ящик унаследуют свойства этого класса. Классы Консервная банка, Бутылка и Ящик обладают общими свойствами — высотой и массой. Каждый из этих классов представляет собой частный случай общей концепции Отходы. Множественное наследование Класс может наследовать из нескольких других классов путем множественного наследования. При использовании множественного наследования будьте готовы к следующим потенциальным проблемам:
Множественное и повторяющееся наследование. Класс Окно с полосой прокрутки и вложенным окном наследует свойства класса Окно более чем один раз. Здесь может возникнуть вопрос «Сколько копий атрибутов класса Окно добавлено в класс Окно с полосой прокрутки и
вложенным окном?». Обычно правила языков программирования, касающиеся множественного наследования, очень сложны, и для правильного использования этих правил необходимо их очень хорошо понимать. Поэтому множественное наследование рекомендуется применять только при необходимости и с большой внимательностью. Абстрактные и конкретные классыКласс, не имеющий экземпляров, и существующий только для наследования другими классами, называется абстрактным классом. Классы, имеющие экземпляры, называются конкретными классами. Обратите внимание, что действующий абстрактный класс должен иметь по крайней мере одного потомка. Пример Сайт Палитра в системе управления складом товаров служит абстрактным сущностным классом, который обладает свойствами,
общими для различный типов сайтов Палитра. Класс-предок, в данном случае сайт Палитра, является абстрактным и не имеет собственных экземпляров. ИспользованиеПоскольку каждый стереотип классов имеет свое назначение, наследование между классами разных стереотипов не имеет смысла. Например, если пограничный класс унаследует свойства сущностного класса, то превратится в некий гибрид. Поэтому обобщение применяется только между классами одного стереотипа. Обобщение позволяет установить два вида отношений между классами:
Для создания таких отношений нужно выделить свойства, общие для нескольких классов, поместить их в отдельные классы и установить наследование от этих новых классов. Другой способ — создать новые классы, конкретизируя свойства более общих классов, и установить наследование, чтобы новые классы наследовали свойства более общих классов. Если эти два варианта совпадают, будет нетрудно правильно установить наследование между классами. Однако в некоторых случаях эти варианты не совпадают. Тогда нужно очень тщательно следить, чтобы структура наследования оставалась ясной и четкой. По крайней мере нужно знать назначение каждого экземпляра наследования в модели. Наследование и поддержка полиморфизма Отношение подтипов означает, что потомок является подтипом, который может полностью заменить всех своих предков в любой
ситуации. Пример В системе управления складом товаров класс Интерфейс Оборудование определяет базовый набор функций для связи со всеми типами транспортного оборудования, например, кранами и грузовиками. Этот класс определяет, помимо прочего, операцию executeTransport. Классы Интерфейс Грузовик и Интерфейс Кран наследуют свойства класса Интерфейс Оборудование. Таким образом, объекты
обоих классов будут отвечать на сообщение executeTransport. Класс Интерфейс Оборудование может быть абстрактным, то есть может не иметь собственные экземпляры. В этом случае он может только определять сигнатуру операции executeTransport, а классы-потомки будут ее реализовывать. В некоторых объектно-ориентированных языках программирования, например, в C++, иерархия классов используется как иерархия типов, вынуждая создавать подтипы в модели проектирования с помощью наследования. В других языках, например, в Smalltalk-80, при компиляции не используется контроль типов. Если объекты не могут ответить на полученное сообщение, они выдают сообщение об ошибке. Однако обобщение можно использовать для установления отношений подтипов и в языках без контроля типов. Наследование для поддержки повторного использования реализацииОтношение подклассов составляет основу концепции повторного использования при обобщении. При создании подклассов необходимо определить, какие части реализации будут повторно использоваться наследуемыми свойствами, определенными в других классах. Отношения подклассов экономят усилия и позволяют повторно использовать код при реализации классов. Пример В библиотеке классов Smalltalk-80 класс Dictionary наследует свойства класса Set. Причина этого обобщения в том, что класс Dictionary может повторно использовать некоторые общие методы и способы
хранения из реализации класса Set. Создание подклассов часто приводит к возникновению непоследовательности наследования в иерархиях, из-за чего структуру
наследования трудно понять и использовать. Поэтому наследование только в целях повторного использования следует
применять тогда, когда в инструкциях по работе с языком программирования не указаны другие способы. Работа с повторным
использованием такого типа достаточно сложна. Любые изменения класса Set могут повлечь значительные изменения всех
классов, наследующих его свойства. Учтите это и устанавливайте наследование только от стабильных классов. Наследование
фактически остановит реализацию класса Set, потому что для его изменения придется приложить слишком много усилий. Наследование в языках программированияИспользование отношений обобщения при проектировании сильно зависит от семантики и соответствующих рекомендаций языка программирования. Объектно-ориентированные языки поддерживают наследование между классами, а остальные языки — нет. При работе с моделью проекта необходимо учитывать характеристики языка программирования. Если язык не поддерживает наследование или множественное наследование, необходимо смоделировать наследование при реализации. В таком случае это лучше сделать в модели проекта и не использовать обобщение для описания структур наследования. Моделирование структур наследования с помощью обобщения, а затем моделирование наследования при реализации может разрушить проект. Если язык не поддерживает наследование или множественное наследование, необходимо смоделировать наследование при
реализации. В таком случае это лучше сделать в модели проекта и не использовать обобщение для описания структур
наследования. Во время моделирования возможно потребуется изменить свойства интерфейсов и других объектов. Наследование рекомендуется моделировать одним из следующих способов:
Пример В этом примере потомки направляют сообщения своему предку через ссылки, которые являются экземплярами ассоциаций. Поведение, общее для объектов Консервная банка, Бутылка и Ящик, оформляется в отдельный класс. Объекты с таким же поведением при необходимости его выполнения посылают сообщение в объект Отходы. |

 Однако обычно у класса бывает
только один предок.
Однако обычно у класса бывает
только один предок. При использовании повторяющегося наследования необходимо иметь четкое определение его семантики. В
большинстве случаев семантика определяется языком программирования, который поддерживает повторяющееся наследование.
При использовании повторяющегося наследования необходимо иметь четкое определение его семантики. В
большинстве случаев семантика определяется языком программирования, который поддерживает повторяющееся наследование. Свойства этого класса наследуются конкретными классами (Приемный пункт,
Оборудование и Помещение), каждый из которых представляет собой сайт Палитра. Все эти объекты обладают общим свойством
— содержат одну или несколько палитр.
Свойства этого класса наследуются конкретными классами (Приемный пункт,
Оборудование и Помещение), каждый из которых представляет собой сайт Палитра. Все эти объекты обладают общим свойством
— содержат одну или несколько палитр.

 Эти объекты могут в любое время заменить Интерфейс
Оборудование и будут при этом обладать его поведением. Другие объекты (клиенты) могут послать сообщение в объект
Интерфейс Оборудование, не обладая информацией, откуда придет ответ — от Интерфейса Грузовик или от Интерфейса Кран.
Эти объекты могут в любое время заменить Интерфейс
Оборудование и будут при этом обладать его поведением. Другие объекты (клиенты) могут послать сообщение в объект
Интерфейс Оборудование, не обладая информацией, откуда придет ответ — от Интерфейса Грузовик или от Интерфейса Кран. В некоторых
случаях обобщение нужно использовать независимо от того, поддерживает ли его язык программирования. Это делается для
упрощения модели объекта и исходного кода и удобства их обслуживания. В целом, решение о том, применять ли
наследование, в большой степени зависит от специфики языка программирования.
В некоторых
случаях обобщение нужно использовать независимо от того, поддерживает ли его язык программирования. Это делается для
упрощения модели объекта и исходного кода и удобства их обслуживания. В целом, решение о том, применять ли
наследование, в большой степени зависит от специфики языка программирования. Хотя класс Dictionary можно рассматривать как класс Set (содержащий пары
ключ-значение), Dictionary не является подтипом Set, потому что в Dictionary нельзя добавлять объекты любых типов, а
только пары ключ-значение. Объекты, использующие Dictionary, не обладают информацией, что этот класс является классом
Set.
Хотя класс Dictionary можно рассматривать как класс Set (содержащий пары
ключ-значение), Dictionary не является подтипом Set, потому что в Dictionary нельзя добавлять объекты любых типов, а
только пары ключ-значение. Объекты, использующие Dictionary, не обладают информацией, что этот класс является классом
Set.
 Моделирование структур наследования с помощью обобщения, а затем моделирование наследования в реализации
может разрушить проект.
Моделирование структур наследования с помощью обобщения, а затем моделирование наследования в реализации
может разрушить проект.Логика сознания. Часть 10. Задача обобщения / Хабр
В принципе, любая информационная система сталкивается с одними и теми же вопросами. Как собрать информацию? Как ее интерпретировать? В какой форме и как ее запомнить? Как найти закономерности в собранной информации и в какой форме их записать? Как реагировать на поступающую информацию? Каждый из вопросов важен и неразрывно связан с остальными. В этом цикле мы пытаемся описать то, как эти вопросы решаются нашим мозгом. В этой части пойдет разговор о, пожалуй, самой загадочной составляющей мышления — процедуре поиска закономерностей.
Как собрать информацию? Как ее интерпретировать? В какой форме и как ее запомнить? Как найти закономерности в собранной информации и в какой форме их записать? Как реагировать на поступающую информацию? Каждый из вопросов важен и неразрывно связан с остальными. В этом цикле мы пытаемся описать то, как эти вопросы решаются нашим мозгом. В этой части пойдет разговор о, пожалуй, самой загадочной составляющей мышления — процедуре поиска закономерностей.Взаимодействие с окружающим миром приводит к накоплению опыта. Если в этом опыте есть какие-либо закономерности, то они могут быть выделены и впоследствии использованы. Наличие закономерностей можно интерпретировать, как присутствие чего-то общего в воспоминаниях, составляющих опыт. Соответственно, выделение таких общих сущностей принято называть обобщением.
Задача обобщения – это ключевая задача во всех дисциплинах, которые хоть как-то связаны с анализом данных. Математическая статистика, машинное обучение, нейронные сети – все это вращается вокруг задачи обобщения. Естественно, что и мозг не остался в стороне и как мы можем иногда наблюдать на собственном опыте, тоже порой неплохо справляется с обобщением.
Естественно, что и мозг не остался в стороне и как мы можем иногда наблюдать на собственном опыте, тоже порой неплохо справляется с обобщением.
Несмотря на то, что обобщение возникает всегда и везде сама задача обобщения, если рассматривать ее в общем виде, остается достаточно туманной. В зависимости от конкретной ситуации в которой требуется выполнить обобщение постановка задачи обобщения может меняться в очень широком диапазоне. Различные постановки задачи порождают очень разные и порой совсем непохожие друг на друга методы решения.
Многообразие подходов к обобщению создает ощущение, что процедура обобщения – это нечто собирательное и что универсальной процедуры обобщения, видимо, не существовует. Однако, мне кажется, что универсальное обобщение возможно и именно оно и свойственно нашему мозгу. В рамках описываемого в этом цикле подхода удалось придумать удивительно красивый (по крайней мере мне он кажется таким) алгоритм, который включает в себя все классические вариации задачи обобщения. Этот алгоритм не только хорошо работает, но и самое удивительное — он идеально ложится на архитектуру биологических нейронных сетей, что заставляет верить, что, действительно, где-то так работает и реальный мозг.
Этот алгоритм не только хорошо работает, но и самое удивительное — он идеально ложится на архитектуру биологических нейронных сетей, что заставляет верить, что, действительно, где-то так работает и реальный мозг.
Перед тем как описывать алгоритм такого универсального обобщения попробуем разобраться с тем какие формы обобщения принято выделять и, соответственно, что и почему должен включать в себя универсальный подход.
Философско-семантический подход к обобщению понятий
Философия имеет дело с семантическими конструкциями. Проще говоря, выражает и записывает свои утверждения фразами на естественном языке. Философско-семантический подход к обобщению заключается в следующем. Имея понятия, объединенные неким видовым признаком, требуется перейти к новому понятию, которое дает более широкое, но менее конкретное толкование, свободное от видового признака.Например, имеется понятие «наручные часы», которое описывается как: «указатель времени, закрепленный на руке с помощью ремешка или браслета». Если мы избавимся от видового признака «закрепленный на руке…», то получим обобщенное понятие «часы», как любой инструмент, определяющий время.
Если мы избавимся от видового признака «закрепленный на руке…», то получим обобщенное понятие «часы», как любой инструмент, определяющий время.
В примере с часами в самом названии наручных часов содержалась подсказка для обобщения. Достаточно было отбросить лишнее слово и получалось требуемое понятие. Но это не закономерность, а следствие семантики, построенной «от обратного», когда нам уже известен результат обобщения.
Задача чистого обобщения
В формулировке Френка Розенблатта задача чистого обобщения звучит так: «В эксперименте по «чистому обобщению» от модели мозга или персептрона требуется перейти от избирательной реакции на один стимул (допустим, квадрат, находящийся в левой части сетчатки) к подобному ему стимулу, который не активирует ни одного из тех же сенсорных окончаний (квадрат в правой части сетчатки)» (Rosenblatt, 1962).Акцент на «чистое» обобщение подразумевает отсутствие «подсказок». Если бы нам предварительно показали квадрат во всех возможных позициях сетчатки и дали возможность все это запомнить, то узнавание кадрата стало бы тривиальным. Но по условию квадрат нам показали в одном месте, а узнать мы должны его совсем в другом. Сверточные сети решают эту задачу за счет того, что в них изначально заложены правила «перетаскивания» любой фигуры по всему пространству сетчатки. За счет знания того как «перемещать» изображение они могут взять квадрат, увиденный в одном месте и «примерить» его ко всем возможным позициям на сетчатке.
Но по условию квадрат нам показали в одном месте, а узнать мы должны его совсем в другом. Сверточные сети решают эту задачу за счет того, что в них изначально заложены правила «перетаскивания» любой фигуры по всему пространству сетчатки. За счет знания того как «перемещать» изображение они могут взять квадрат, увиденный в одном месте и «примерить» его ко всем возможным позициям на сетчатке.
Ту же задачу мы в нашей модели решаем за счет создания пространства контекстов. Отличие от сверточных сетей в том, кто к кому идет — «гора к Магомеду» или «Магомед к горе». В сверточных сетях при анализе новой картинки каждый предварительно известный образ варьируется по всем возможным позициям и «примеряется» к анализируемой картинке. В контекстной модели каждый контекст трансформирует (перемешает, поворачивает, масштабирует) анализируемую картинку так как ему предписывают его правила, а затем «сдвинутая» картинка сравнивается с «неподвижными» заранее известными образами. Эта, на первый взгляд, небольшая разница дает последующее очень сильное различее в подходах и их возможностях.
Эта, на первый взгляд, небольшая разница дает последующее очень сильное различее в подходах и их возможностях.
Родственна задаче чистого обобщения задача инвариантного представления. Имея явление, предстающее перед нами в разных формах, требуется инвариантно описать эти представления с целью узнавания явления в любых его проявлениях.
Задача классификации
Есть множество объектов. Есть предварительно заданные классы. Есть обучающая выборка – набор объектов, про которые известно к каким классам они относятся. Требуется построить алгоритм, который обоснованно отнесет любые объекты из исходного множества к одному из классов. В математической статистике задачи классификации относят к задачам дискриминантного анализа.В машинном обучении задача классификации считается задачей обучения с учителем. Есть обучающая выборка, про которую известно: какой стимул на входе приводит к какой реакции на выходе. Предполагается, что реакция не случайна, а определяется некой закономерностью. Требуется построить алгоритм, который наиболее точно воспроизведет эту закономерность.
Требуется построить алгоритм, который наиболее точно воспроизведет эту закономерность.
Алгоритм решение задачи классификации зависит от характера входных данных и типов получаемых классов. О том, как решается задача классификации в нейронных сетях и как происходит обучение с учителем в нашей модели мы говорили в предыдущей части.
Задача кластеризации
Предположим у нас есть множество объектов и нам известна степень похожести их друг на друга, заданная матрицей расстояний. Требуется разбить это множество на подмножества, называемые кластерами, так, чтобы каждый кластер объединял схожие объекты, а объекты разных кластеров сильно отличались друг от друга. Вместо матрицы расстояний могут быть заданы описания этих объектов и указан способ, как искать расстояние между объектами по этим описаниям.В машинном обучении, кластеризация попадает под обучение без учителя.
Кластеризация – очень соблазнительная процедура. Удобно разбить множество объектов на относительное небольшое количество классов и впоследствии использовать не исходные, возможно громоздкие описания, а описания через классы. Если при разбиении заранее известно какие признаки важны для решаемой задачи, то кластеризация может «делать акцент» на эти признаки и получать классы удобные для последующего принятия решений.
Если при разбиении заранее известно какие признаки важны для решаемой задачи, то кластеризация может «делать акцент» на эти признаки и получать классы удобные для последующего принятия решений.
Однако, в общем случае ответ на вопрос о важности признаков лежит за пределами задачи кластеризации. Последующее обучение, называемое обучением с подкреплением, должно само, исходя из анализа того насколько удачно или нет оказалось поведение ученика, определить какие признаки важны, а какие нет. При этом «самыми удачными» признаками могут оказаться не признаки из исходных описаний, а уже обобщенные классы, взятые как признаки. Но для определения важности признаков надо, чтобы эти признаки уже присутствовали в описании на момент работы обучения с подкреплеием. То есть получается, что заранее неизвестно какие признаки могут оказаться важными, но понять это можно только уже имея эти признаки.
Другими словами, в зависимости от того какие признаки исходного описания использовать, а какие игнорировать при проведении кластеризации получаются различные системы классов. Одни из них оказываются более полезными для последующих целей, другие менее. В общем случае выходит, что хорошо бы перебрать все возможные варианты кластеризаций, чтобы понять какие из них наиболее удачны для решения конкретной задачи. Причем для решения другой задачи может оказаться удачной совсем другая система кластеризации.
Одни из них оказываются более полезными для последующих целей, другие менее. В общем случае выходит, что хорошо бы перебрать все возможные варианты кластеризаций, чтобы понять какие из них наиболее удачны для решения конкретной задачи. Причем для решения другой задачи может оказаться удачной совсем другая система кластеризации.
Даже если мы решим на что стоит сделать акцент при кластеризации все равно останется вопрос об оптимальной детализации. Дело в том, что в общем случае нет априорной информации о том на сколько классов надо поделить исходное множество объектов.
Вместо знания о количестве классов можно использовать критерий, указывающий на то насколько точно должны все объекты соответствовать созданным классам. В этом случае можно начинать кластеризацию с некого начального количества классов и добавлять новые классы если остаются объекты, для которых ни один класс не подходит достаточно хорошо. Но процедура с добавлением не снимает вопроса оптимальности детализации. При задании низкого порога соответствия объекта классу получаются большие классы, отражающие основные закономерности.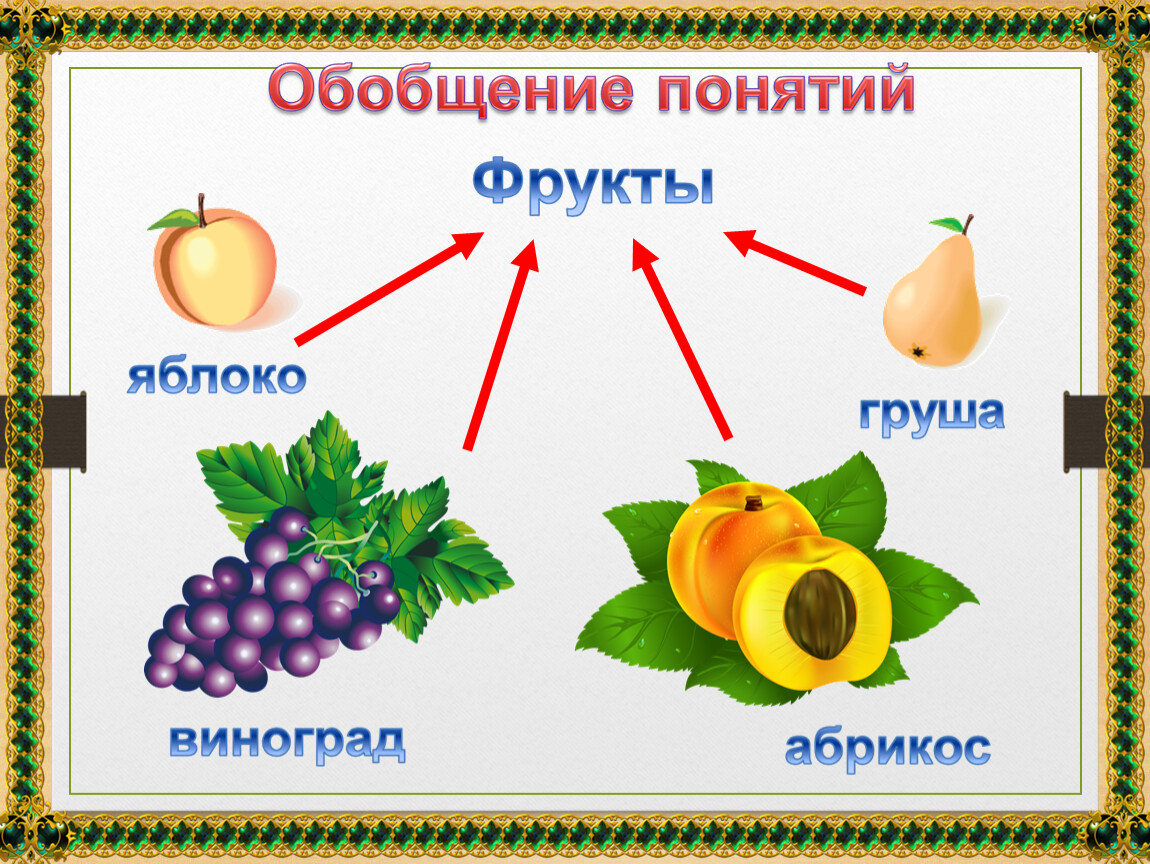 При выборе высокого порога получается много классов с небольшим числом объектов. Эти классы учитывают мелкие детали, но за деревьями становится не видно леса.
При выборе высокого порога получается много классов с небольшим числом объектов. Эти классы учитывают мелкие детали, но за деревьями становится не видно леса.
Факторный анализ
Предположим, что мы имеем множество объектов в котором все объекты снабжены признаковыми описаниями. Такие описания можно записать соответствующими векторами. Далее предположим, что признаки имеют количественную природу.Удобно центрировать описания, то есть рассчитать среднее для каждого признака и скорректировать признаки на их среднее значение. Это равносильно переносу начала координат в «центр масс». Можно посчитать корреляции между признаками. Если записать корреляционную матрицу признаков и найти ее собственные вектора, то эти вектора будут являться новым ортогональным базисом, в котором можно описать исходное множество объектов.
В базисе из исходных признаков за счет их возможной коррелированности линейные закономерности были «размазаны» между признаками. При переходе к ортогональному базису начинает четче проступать внутренняя структура закономерностей. Так как ортогональный базис определен с точностью до вращения, то можно так повернуть базис из собственных векторов, чтобы направления осей наилучшим образом соответствовали тем направлениям, вдоль которых данные имеют наибольший разброс.
Так как ортогональный базис определен с точностью до вращения, то можно так повернуть базис из собственных векторов, чтобы направления осей наилучшим образом соответствовали тем направлениям, вдоль которых данные имеют наибольший разброс.
Собственные числа, соответствующие собственным векторам, показывают какой процент от общей дисперсии приходится на какой собственный вектор. Собственные вектора, на которые приходится наиболее существенный процент дисперсии называют главными компонентами. Часто бывает удобно перейти от описания в исходных признаках к описанию в главных компонентах.
Так как главные компоненты отражают наиболее существенные линейные закономерности, свойственные исходному множеству, то они могут называться определенным обобщением исходных данных.
Замечательное свойство факторного анализа — это то, что факторы могут не только напоминать исходные признаки, но и могут оказаться новыми ненаблюдаемыми сущностями.
Если сравнивать обобщения, которые получаются через классы и которые получаются через факторы, то условно можно сказать, что классы выделяют «области», а факторы – «направления».
Часто для отнесения объекта к классу смотрят не столько на близость объекта к центру класса, а на соответствие объекта параметрам распределения, свойственным классу (на этом, например, построен EM алгоритм). То есть если в пригороде города стоит тюрьма, то человек которого вы встретите рядом с тюрьмой скорее всего горожанин, а не заключенный, хотя расстояние до центра города значительно выше чем до центра тюрьмы. «Области» стоит понимать с учетом этого замечания.
Ниже приведена картинка, по которой можно приблизительно соотнести обобщение классами и факторами.
Графики распределения роста и веса игроков американской футбольной лиги (NFL). Сверху игроки защиты, снизу игроки нападения. Цветами выделены позиции игроков (Dr. Craig M. Booth).Все множество игроков можно разбить на классы по их роли на поле. По параметрам «вес — рост» можно выделить глобальные факторы (не показаны) или факторы для каждого из классов.
Цветные линии соответствуют первому главному фактору в каждом из классов. Этот фактор можно интерпретировать как «размер игрока». Он определяется как проекция точки игрока на эту ось. Значение проекции дает значение, которое отбрасывает «не идеальность» игрока. Если к первой оси провести вторую ортогональную, то она будет описывать второй фактор «тип телосложения», проще говоря, худой игрок или толстый.
Этот фактор можно интерпретировать как «размер игрока». Он определяется как проекция точки игрока на эту ось. Значение проекции дает значение, которое отбрасывает «не идеальность» игрока. Если к первой оси провести вторую ортогональную, то она будет описывать второй фактор «тип телосложения», проще говоря, худой игрок или толстый.
При всей красоте и удобстве факторов есть с ними и сложности. Так же, как и с классами всегда стоит вопрос сколько и каких факторов стоит выделять и использовать. Конечно, удобно, когда несколько первых главных компонент несут почти всю информацию, но на практике такое бывает нечасто. Например, возьмем 10 000 наиболее популярных фильмов, несколько миллионов человек и проанализируем оценки, которые они поставили тем фильмам, что посмотрели. Несложно составить корреляционную матрицу для фильмов. Положительная корреляция между двумя фильмами говорит о том, что люди, которые оценивают один фильм выше среднего скорее всего выше среднего оценивают и другой.
Проведем факторный анализ корреляционной матрицы и затем вращение осей для удобной интерпретации факторов. Окажется, что существенную роль играют первые пять-шесть факторов. Они соответствуют наиболее общим закономерностям. Это, конечно, жанры фильмов: «боевик», «комедия», «мелодрама». Кроме того, выделятся факторы: «русское кино» (если люди будут из России) и «авторское кино». Последующие факторы тоже можно интерпретировать, но их вклад в объяснение дисперсии будет все меньше и меньше.
Окажется, что существенную роль играют первые пять-шесть факторов. Они соответствуют наиболее общим закономерностям. Это, конечно, жанры фильмов: «боевик», «комедия», «мелодрама». Кроме того, выделятся факторы: «русское кино» (если люди будут из России) и «авторское кино». Последующие факторы тоже можно интерпретировать, но их вклад в объяснение дисперсии будет все меньше и меньше.
Первые пять самых существенных факторов объясняют порядка 30 процентов общей дисперсии. Это не особо много, учитывая, что дисперсия – это квадрат среднеквадратического отклонения. Соответственно, основные факторы объясняют всего 17 процентов общего разброса оценок. Если посмотреть на остальные факторы, то многие из них объясняют всего лишь десятые или сотые доли процента общей дисперсии и вроде бы несущественны.
Но каждый мелкий фактор, как правило, соответствует некой локальной закономерности. Он объединяет фильмы одного режиссера, одного сценариста или одного актера. Оказывается, что когда мы хотим что-либо понять про конкретный фильм, то основные факторы объясняют свои 30 процентов дисперсии и при этом процентов 40-50 дисперсии объясняют один-два мелких фактора, которые несущественны для общей массы, но оказываются чрезвычайно важны именно для этого фильма.
Принято говорить, что «дьявол в деталях». Это относится именно к тому, что практически нет факторов, которыми можно пренебречь. Каждая мелочь может оказаться решающей в определенной ситуации.
Формирование понятий
Результатом обобщения может являться формирование понятий с использованием которых строятся последующие описания. Есть разные мнения относительно того, что является основным принципом, по которому человек выделяет те или иные понятия. Собственно, все пункты настоящего перечисления имеют к этому непосредственное отношение.Задача идеализации
В процессе обобщения мы получаем понятия, которые по неким признакам объединяют множество явлений, с которыми мы ранее сталкивались. Выделение того общего, что есть в этих явлениях приводит к тому, что мы можем описать свойства неких идеальных понятий, свободных от индивидуальных деталей отдельных явлений.Именно идеальные понятия лежат в основе математики. Точка, прямая, плоскость, число, множество – это идеализации объектов из нашего повседневного опыта. Математика вводит для этих понятий формальную систему правил, которая позволяет строить утверждения, преобразовывать эти утверждения, доказывать или опровергать их истинность. Но если для самой математики базовые понятия первичны, то для человека они связаны с опытом их использования. Это позволяет математикам не использовать полный перебор при поисках доказательств, а осуществлять более целенаправленный поиск, основанный на опыте, лежащем за идеальными понятиями.
Математика вводит для этих понятий формальную систему правил, которая позволяет строить утверждения, преобразовывать эти утверждения, доказывать или опровергать их истинность. Но если для самой математики базовые понятия первичны, то для человека они связаны с опытом их использования. Это позволяет математикам не использовать полный перебор при поисках доказательств, а осуществлять более целенаправленный поиск, основанный на опыте, лежащем за идеальными понятиями.
Логическая индукция
Логическая индукция подразумевает получение общего закона по множеству частных случаев.Разделяют полную индукцию:
Множество А состоит из элементов: А1, А2, А3, …, Аn.
- А1 имеет признак В
- А2 имеет признак В
- Все элементы от А3 до Аn также имеют признак В

И неполную индукцию:
Множество А состоит из элементов: А1, А2, А3, …, Аn.
- А1 имеет признак В
- А2 имеет признак В
- Все элементы от А3 до Аk также имеют признак B
Неполная индукция имеет дело с вероятностью и может быть ошибочной (проблема индукции).
Индукция связана с обобщением в двух моментах. Во-первых, когда говорится о множестве объектов, то подразумевается, что предварительно что-то послужило основанием объединить эти объекты в единое множество. То есть нашлись какие-то механизмы, которые позволили сделать предварительное обобщение.
Во-вторых, если мы методом индукции обнаруживаем некий признак, который свойственен элементам некой группы, которая описывает определенное понятие, то мы можем использовать этот признак, как характеризующий для отнесения к этой группе.
Например, мы обнаруживаем, что существуют механические приборы с характерным циферблатом и стрелками. По внешнему сходству мы делаем обобщение и относим их к классу часы, и формируем соответствующее понятие.
Далее мы замечаем, что часы могут определять время. Это позволяет нам сделать неполную индукцию. Мы заключаем, что свойство всех часов – способность определять время.
Теперь мы можем сделать следующий шаг обобщения. Мы можем сказать, что к «часам» можно отнести вообще все, что позволяет следить за временем. Теперь часами мы можем назвать и солнце, которое отмеряет сутки и школьные звонки, отсчитывающие уроки.
Логическая индукция имеет много общего с семантическим обобщением понятий. Но семантическое обобщение делает несколько иной акцент. Семантический подход говорит о признаках, которые составляют описание понятия, и возможности отбрасывания их части для получения более общей формулировки. При этом остается открытым вопрос — откуда должны взяться такие определения понятий, которые позволят выполнить переход к обобщению «через отбрасывание». Неполная логическая индукция как раз и показывает путь формирования таких описательных признаков.
Неполная логическая индукция как раз и показывает путь формирования таких описательных признаков.
Задача дискретизации
Имея дело с непрерывными величинами, часто требуется перейти к их описанию в дискретных значениях. Для каждой непрерывной величины выбор шага квантования определяется той точностью описания, которую требуется сохранить. Получившиеся в результате интервалы дробления объединяют различные значения непрерывной величины, ставя им в соответствие определенные дискретные понятия. Такую процедуру можно отнести к обобщению по тому факту, что объединение значений происходит, исходя из их попадания в интервал квантования, что говорит об их определенной общности.Соотнесение понятий
Осуществляя обобщение любым из возможных способов, мы можем представить результат обобщения через систему понятий. При этом обобщенные понятия не просто образуют набор независимых друг от друга элементов, а приобретают внутреннюю структуру взаимоотношений.Например, классы, получаемые в результате кластеризации, образуют некую пространственную структуру, в которой какие-то классы оказываются ближе друг к другу, какие-то дальше.
При использовании описания чего-либо через факторы используют набор факторных весов. Факторные веса принимают вещественные значения. Эти значения можно аппроксимировать набором дискретных понятий. При этом для этих дискретных понятий будет характерна система отношений «больше – меньше».
Таким образом, нас каждый раз интересует не просто выделение обобщений, но и формирование некой системы, в которой будет понятно, как эти обобщения соотносятся со всеми остальными обобщениями.
Чем-то похожая ситуация возникает при анализе естественного языка. Слова языка имеют определенные взаимосвязи. Природа этих связей может быть различна. Можно говорить о частоте совместного проявления слов в реальных текстах. Можно говорить о похожести их смыслов. Можно строить систему отношений, основанную на переходах к более общему содержанию. Подобные построения приводят к семантическим сетям разного вида.
Пример семантической сети (Автор: Знанибус — собственная работа, CC BY-SA 3.0, commons. wikimedia.org/w/index.php?curid=11912245)
wikimedia.org/w/index.php?curid=11912245)Говорят, что в правильной постановке задачи содержится три четверти верного ответа. Очень похоже, что это справедливо и для задачи обобщения. Что мы хотим видеть результатом обобщения? Устойчивые классы? Но где границы этих классов? Факторы? Какие и сколько? Закономерности? Редкие, но сильные совпадения или нечеткие, но подкрепленные большим числом примеров зависимости? Если мы накопили данные и провели обобщения, то как из множества возможных понятий выбрать те, что лучше всего подходят для описания конкретной ситуации? Что вообще есть обобщения? Как выглядит система соотнесения обобщений между собой?
Далее я попробую дать и «правильную» постановку задачи, и возможный ответ, подкрепленный работающим кодом. Но это будет через статью. Пока же, в следующей части, нам предстоит познакомиться с одной очень важной биологической подсказкой, дающей, пожалуй, главный ключ к пониманию механизма обобщения.
Алексей Редозубов
Логика сознания.Часть 1. Волны в клеточном автомате
Логика сознания. Часть 2. Дендритные волны
Логика сознания. Часть 3. Голографическая память в клеточном автомате
Логика сознания. Часть 4. Секрет памяти мозга
Логика сознания. Часть 5. Смысловой подход к анализу информации
Логика сознания. Часть 6. Кора мозга как пространство вычисления смыслов
Логика сознания. Часть 7. Самоорганизация пространства контекстов
Логика сознания. Пояснение «на пальцах»
Логика сознания. Часть 8. Пространственные карты коры мозга
Логика сознания. Часть 9. Искусственные нейронные сети и миниколонки реальной коры
Логика сознания. Часть 10. Задача обобщения
Логика сознания. Часть 11. Естественное кодирование зрительной и звуковой информации
Логика сознания. Часть 12. Поиск закономерностей. Комбинаторное пространство
Логика сознания. Часть 13. Мозг, смысл и конец света
 Часть 1. Волны в клеточном автомате
Часть 1. Волны в клеточном автоматеИнформация для студентов и преподавателей
«Мы предоставляем надежные, доступные и точные рецензируемые учебные пособия, которые отражают мнение экспертов — все на языке, понятном студентам университета!»
Крис Дрю, доктор философии
Основатель и главный редактор
 youtube.com/embed/dQPJaJCwjmE» frameborder=»0″ allowfullscreen=»allowfullscreen»> 900 20
youtube.com/embed/dQPJaJCwjmE» frameborder=»0″ allowfullscreen=»allowfullscreen»> 900 20«ЛЮБОВЬ, ЛЮБОВЬ, ЛЮБОВЬ Крис. Один из лучших учителей, которые у меня когда-либо были. Мне нравится его легкий и понятный стиль преподавания».
Джессика Т.
Студент социальных наук
«Я был так впечатлен поддержкой и присутствием Криса. Крис такой вовлеченный, поддерживающий и энергичный. Я бы не учился так же хорошо, как в университете, без его замечательного руководства и энтузиазма».
Салли Р.
Бакалавр педагогических наук Студент
«Крис поддерживает и очень эффективно учит. У него отличный способ объяснить суть и разбить все на мелкие кусочки. Он изо всех сил старается помочь своим ученикам стать лучше».
Кристин С.
Молодежная студентка
«Крис выходит за рамки любого другого учителя, которого я когда-либо имел, очень доступный и в курсе всех мельчайших деталей. Большое спасибо Крису».
Большое спасибо Крису».
Джеймс Л.
Бакалавр гуманитарных наук Студент
Пройти курс написания эссе
Как показано вThe Economist
Readers Digest
Times Высшее образование
Журнал eLearn
Просмотр сайта
Навыки академического письма
Поиск
Советы по обучению в колледже
Поиск
Тематические учебные пособия
Поиск
Поиск для учебных пособий
Лучшие руководства по академическому письму и обучению
Как написать введение, которое поразит вашего учителя
Практические советы о том, как написать введение для вашего следующего эссе.
Как избежать прокрастинации во время учебы
Вот 11 научно обоснованных советов о том, как не отвлекаться от учебы.
Как начать эссе (если не знаешь, что написать)
Иногда первое предложение самое сложное. Вот ваше решение.
Как найти научные источники в Интернете (бесплатно)
Простое руководство по получению тех научных источников, которые вам нужны для вашей следующей статьи.
Моя идеальная формула структуры абзаца
Это один из моих самых больших и лучших приемов для написания потрясающих глубоких эссе.
Должны ли вы получить Grammarly? Вот мое мнение.
Я смотрю на аргументы с обеих сторон этой темы.
Как перефразировать как профессионал, чтобы получить высшие оценки
Перефразировать сложно, но с помощью этой простой формулы я превратил это в искусство.
Как отредактировать эссе, чтобы получить на 13% более высокие оценки
Исследования показывают, что правильное редактирование повысит вашу оценку на 13%. Вот как.
Вот как.
Как написать выводы с помощью моего метода заключения 5 Cs
Стильно завершите свое эссе с помощью этого простого и эффективного метода написания выводов.
Оставайтесь на связи
Информация для студентов и преподавателей
«Мы предоставляем надежные, доступные и точные рецензируемые учебные пособия, которые отражают мнение экспертов — все на языке, понятном студентам университета!»
Крис Дрю, доктор философии
Основатель и главный редактор
«ЛЮБОВЬ, ЛЮБОВЬ, ЛЮБОВЬ Крис. Один из лучших учителей, которые у меня когда-либо были. Мне нравится его легкий и понятный стиль преподавания».
Один из лучших учителей, которые у меня когда-либо были. Мне нравится его легкий и понятный стиль преподавания».
Джессика Т.
Студент социальных наук
«Я был так впечатлен поддержкой и присутствием Криса. Крис такой вовлеченный, поддерживающий и энергичный. Я бы не учился так же хорошо, как в университете, без его замечательного руководства и энтузиазма».
Салли Р.
Бакалавр педагогических наук Студент
«Крис поддерживает и очень эффективно учит. У него отличный способ объяснить суть и разбить все на мелкие кусочки. Он изо всех сил старается помочь своим ученикам стать лучше».
Кристин С.
Молодежная студентка
«Крис выходит за рамки любого другого учителя, которого я когда-либо имел, очень доступный и в курсе всех мельчайших деталей. Большое спасибо Крису».
Джеймс Л.
Бакалавр гуманитарных наук Студент
Пройти курс написания эссе
Как показано вThe Economist
Readers Digest
Times Высшее образование
Журнал eLearn
Просмотр сайта
Академическое письмо Навыки
Поиск
Советы по учебе в колледже
Поиск
Тематические учебные пособия
Поиск
Поиск учебных пособий
Лучшие учебные пособия по академическому письму и обучению
Как написать введение, которое поразит вашего учителя
Практические советы о том, как написать введение для вашего следующего эссе.
Как избежать прокрастинации во время учебы
Вот 11 научно обоснованных советов о том, как не отвлекаться от учебы.
Как начать эссе (если не знаешь, что написать)
Иногда первое предложение самое сложное. Вот ваше решение.
Как найти научные источники в Интернете (бесплатно)
Простое руководство по поиску научных источников, необходимых для вашей следующей статьи.
Моя идеальная формула структуры абзаца
Это один из моих самых больших и лучших приемов для написания потрясающих глубоких эссе.
Должны ли вы получить Grammarly? Вот мое мнение.
Я смотрю на аргументы с обеих сторон этой темы.
Как перефразировать как профессионал, чтобы получить высшие оценки
Перефразировать сложно, но с помощью этой простой формулы я превратил это в искусство.
Как отредактировать эссе, чтобы получить на 13% более высокие оценки
Исследования показывают, что правильное редактирование повысит вашу оценку на 13%.