НЛП Радуга игра on the App Store
НЛП Радуга — это одна из игр Нового кода, которая приведет Вас в высокопродуктивное состояние и перезагрузит Ваш мозг!
ФУНКЦИИ ПРИЛОЖЕНИЯ:
► Самый большой выбор настроек
► Можно выбрать Хлопки, Прыжки, Нажатия на экран или Все вместе
►
Настройка скорости игры с точностью до 0.01 секунды!
► Классическая игра + Игра с проверкой заданий
► Статистика всех игр
►
Сортировка игр по дате и результату
► Различное начертание слов, размер шрифта и расположение на экране
► Можно менять цвет фона и 12 игровых цветов
► Настройки фоновой мелодии, звуков начала, окончания игры и смены заданий
► Удобная помощь
► Оперативная техподдержка по электронной почте
Игра «Радуга» использует известный в психологии «Эффект Струпа»: когда цвет слова не совпадает с написанным, прочитать его становится труднее.
Благодаря этому эффекту, а также различным настройкам игры:
► в работу включаются оба полушария мозга
► усиливается концентрация внимания
► включается параллельный процессинг — умение выполнять сразу несколько действий одновременно.

Все это способствует переходу в высокопродуктивное состояние (high performance state, HPS), при котором мозг начинает работать более эффективно, гораздо быстрее решая сложные задачи.
Игры Нового кода — это своеобразная разминка для мозга перед началом работы (как разминка перед спортом). Тысячи людей и компаний используют их по всему миру.
ПРАВИЛА ИГРЫ
На экране появляется слово, обозначающее цвет, например: написано слово «синий». Нужно произнести вслух цвет слова. Например, если слово «синий» написано зеленым цветом, то мы говорим вслух «зеленый».
Помимо слов-цветов, в игре могут появляться другие слова (в зависимости от выбранных настроек): ХЛОПКИ, НАЖАТИЯ НА ЭКРАН, ПРЫЖКИ или ВСЕ ВМЕСТЕ. Это делает игру очень увлекательной и в то же время заставляет мозг работать более усердно!
ВРЕМЯ ИГРЫ
Обычно продолжительность игры — 10-15 минут. Для перехода в состояние высокой продуктивности большинству людей этого времени хватает.
Чтобы учесть все запросы пользователей, мы предусмотрели время игры от 1 до 20 минут. Его можно менять в любое время в Настройках игры.
Его можно менять в любое время в Настройках игры.
ПРОВЕРКА ЗАДАНИЙ
Хотя классический вариант игры не предусматривает проверку заданий, достаточно просто играть в течении 10-15 минут. Однако по запросам пользователей мы добавили данную функцию. Ее можно включить/отключить в Настройках игры. Если выбрана игра с проверкой заданий, то в конце игры ведется подсчёт правильных ответов.
СТАТИСТИКА
В игре предусмотрена статистика — можно отслеживать даты всех игр, время и скорость каждой игры, а также результат. Игры можно отсортировать по дате или результату, а также очищать статистику в случае необходимости.
НАСТРОЙКИ ИГРЫ
В игре предусмотрен самый большой выбор настроек:
— Время игры
— Скорость игры с точность до 0.01 секунды! Можно настроить 0.84 или 0.87 секунд для продвинутых пользователей.
— Проверка заданий (вкл/ выкл)
— Цвета букв: 12 цветов
- Начертание букв: прописные, строчные или случайные
— Размер букв
— Подложка для букв
— Расположение слов на экране — случайное или по центру
— Использовать: ХЛОПКИ, НАЖАТИЯ, ПРЫЖКИ или ВСЕ ВМЕСТЕ
- Частота хлопков/прыжков/нажатий
— Частота совпадения цвета и названия
— Настроить фразу в конце игры
— Большой выбор фоновых мелодий и звуков: звука начала и окончаний игры, звук смены заданий
Желаем Вам увлекательной игры, быстрого перехода в высокопродуктивное состояние и оперативного решения необходимых задач!
Если у Вас возникли вопросы и пожелания, Вы можете написать нам, нажав на кнопку «Задать вопрос» в приложении.![]() Мы постараемся ответить как можно быстрее!
Мы постараемся ответить как можно быстрее!
Заговор во имя совершенства — Тренинги И Семинары
Новый код НЛП: Заговор во имя совершенства (Алексей Каптерев)
Название тренинга родилось из фразы, оброненной автором Нового кода НЛП, Джоном Гриндером во время его визита в Москву. В этих четырех словах – суть всего Нового кода. В отличие от психологии, которая изучает среднее, типичное поведение и мышление, предмет изучения НЛП – это совершенство, гениальность. Классический код НЛП был беспрецедентно успешной попыткой моделирования гениев, совершенства других людей. Новый код посвящен раскрытию вашей собственной гениальности.
 Специальные упражнения – игры Нового кода высвобождают эти ресурсы, позволяя им работать на Вас.
Специальные упражнения – игры Нового кода высвобождают эти ресурсы, позволяя им работать на Вас.Новый код – это система творческого решения проблем и задач. Его упражнения предназначены:
• для «проработки» актуальных проблемных ситуаций и поиска новых, нестандартных решений;
• для работы с прошлым, с неприятными воспоминаниями, которые формируют Ваши убеждения о Ваших возможностях;
• для работы с будущим, для эмоциональной подготовки к ситуациям, которые только предстоят: сложным переговорам, выступлениям, экзаменам.
Конечно, цель тренинга – не в том, чтобы за два дня решить все ваши проблемы (хотя к концу тренига многие действительно жалуются, что проблем не осталось). Цель тренинга – дать вам опыт использования упражнений Нового кода для того, чтобы потом вы могли применять их самостоятельно, по мере необходимости.
• Подробнее о том, что такое Новый код
Для кого этот тренинг?
• Для людей, заинтересованных в изучении и развитии себя.
• Для амбициозных людей, для тех, кто верит в собственную гениальность (но может быть пока не знает, в чем именно она заключается).
• Для тех, кто не надеется на «волшебную таблетку», кто готов к последующей работе.
• Новый код для обычных людей
• Новый код и бизнес
• Отзывы участников тренинга
• Поискать отзывы в блогах
Тренинг продолжается два дня, с 10 до 19 часов. Первая половина тренинга — «тактическая», она посвящена работе с повседневными жизненными проблемами. Более конкретно, мы будем изучать:
• Основные принципы Нового кода, «Цепочку мастерства» и четырехшаговую модель изменений Джона Гриндера.
• Игры Нового кода: «Алфавит», «N.A.S.A.», «Дыхание хаоса», «Радуга»… Вы научитесь входить в высокопродуктивное состояние сознания с помощью игр Нового кода. Также вы научитесь переносить полученное состояние в те ситуации, где оно необходимо.
• Модель О.Р.У.Ж.И.Е. – вербальный способ вызова нужного состояния за несколько секунд в любой момент. Судя по отзывам, это одна из самых сильных и полезных техник.
Вторая часть тренинга – стратегическая. Она посвящена разработке вашей собственной долгосрочной стратегии.
 Это – ваш ответ на вопрос «зачем все это?», вопрос о цели и смысле вашей жизни.
Это – ваш ответ на вопрос «зачем все это?», вопрос о цели и смысле вашей жизни.Стратегия — это абсолютно необходимая часть, без нее легко удариться в бессмысленный перфекционизм и начать невероятно эффективно делать то, чего делать вообще не стоит.
Для решения этой задачи у Вас будет возможность поработать с Вашим личным видением, миссией, ценностями. Кроме того, мы будем делать упражнение, позволяющее осознать Ваши «тактические» цели, исходя из Вашего долгосрочного видения. Это способ перестать достигать целей и позволить им просто происходить, случаться в вашей жизни.
Вряд ли мы можем обещать, что вы полностью просветлитесь за один день тренинга. Но повторяя эти упражнения самостоятельно, вы с каждым разом будете находить все более и более точный ответ.
Кто проводит тренинг?
Автор и ведущий тренинга – Алексей Каптерев, сертифицированный тренер НЛП и один из самых опытных в России тренеров Нового кода, прошедший обучение на семинаре Джона Гриндера.
По вопросам приобретения полной версии семинара — пишите traning.
[email protected]

НЛП — авторы книг
Детство провел в Сибири. В 1972г. окончил филологический факультет Ленинградского университета. Работал лесорубом в тайге, охотником-промысловиком на Таймыре, скотогоном в Алтайских горах, журналистом, учителем — всего сменил около тридцати профессий.
Первая книга рассказов Хочу быть дворником вышла в 1983г. и сразу привлекла внимание критиков и читателей точностью и гибкостью стиля и неожиданностью сюжетов. За ней последовали Разбиватель сердец (1988), Технология рассказа (1989), Рандеву со знаменитостью (1990).
Бестселлерами стали Роман воспитания, Приключения майора Звягина (1991) и названная критиками самой смешной книгой последних лет Легенды Невского проспекта (I993).
Литературный скандал вызвал мини-роман Ножик Сережи Довлатова. Последний бестселлер, роман Гонец из Пизы (2000) выдержал за год 11 изданий.
Самый издаваемый сегодня из русских некоммерческих писателей — только в 2000г. Его книги выходили 38 раз общим тиражом около 400 тыс. экз.
Его книги выходили 38 раз общим тиражом около 400 тыс. экз.
Издавался в таких изданиях, как Литературная газета, Знамя, Октябрь, Дружба народов, Огонек и др.
Читал лекции по современной русской прозе в университетах Милана, Иерусалима, Копенгагена.
В свободное время живет в Москве, но работать продолжает в Таллине.
1950 Семья переезжает к новому месту службы отца в Забайкалье. До шестнадцатилетнего возраста Михаил меняет школы — постоянные переезды по гарнизонам Дальнего Востока и Сибири. Курсы планеристов при областном ДОСААФ.
1964 Переезд в Белоруссию.
1965 Первая публикация стихов в республиканской газете.
1966 Заканчивает с золотой медалью школу в городе Могилеве и поступает на отделение русской филологии филологического факультета Ленинградского университета. Живет в семье деда ‘профессора-биолога’, заведущего кафедрой одного из ленинградских институтов.
1967 — 68 Летние поездки в студенческие строительные отряды на Мангышлак и под Норильск.
1969 г. — Летом, на пари с друзьями, без денег выйдя из Ленинграда, за месяц добрался ‘зайцем’ до Камчатки, используя все виды транспорта и обманом получил по пути пропуск для въезда в ‘пограничную зону’, что вошло в легенды Ленинградского филфака. Одновременно — комсорг курса, один из секретарей бюро комсомола университета.
1970 г. — Симулирует психическую болезнь в психиатрической клинике для получения академического отпуска в университете. Весной уезжает в Среднюю Азию, где ведет бродяжническую жизнь по разным местам полгода. Осенью переезжает в Калининград, где экстерном сдает ускоренный курс матроса второго класса и уходит в рейс на траулере рыболовецкого флота.
1971 г. — Восстанавливается в университете, одновременно работая старшим пионервожатым в школе. Первая ‘публикация’ в Ленинграде — рассказ в университетской стенной газете.
1972 г. — Заканчивает университет. Защищает диплом по теме:
‘Типы композиции современного русского советского рассказа’. С обвинением в ‘формалистском уклоне’ диплом не зачтен. Повторная защита назначена в Пушкинском доме /Ленинградский Институт русской литературы при АН СССР/. Тот же диплом защищен. Распределен учителем в Ленинградскую область. Из-за отсутствия мест работает воспитателем группы продленного дня начальной школы.
Повторная защита назначена в Пушкинском доме /Ленинградский Институт русской литературы при АН СССР/. Тот же диплом защищен. Распределен учителем в Ленинградскую область. Из-за отсутствия мест работает воспитателем группы продленного дня начальной школы.
1973 г. — Учитель русского языка и литературы в сельской восьмилетней школе. Уволен по собственному желанию и по ходатайству педагогического коллектива.
Рабочий-бетонщик цеха сборных конструкций 4-ЖБК в Ленинграде Летом выезжает с бригадой так называвшихся ‘шабашников’ на Кольский полуостров, Терский берег Белого моря. Вальщик леса и землекоп.
1974 г. Младший научный сотрудник Государственного музея истории религии и атеизма /Казанский собор/. Научная тема: ‘Возникновение религии и ее ранние формы’. Водит экскурсии по собору. По хозяйственным соображениям переводится директором музея в столяры, затем — снабженец и заместитель директора по административно-хозяйственной части. Уволен ‘по собственному озверению’.
1975 г. Корреспондент заводской газеты обувного объединения ‘Скороход’ ‘Скороходовский рабочий’, и.о. завотделом культуры, и.о. завотделом информации. Первые публикации рассказов в ‘официальной государственной прессе’. Ежегодная премия газеты за лучший материал по культуре. Уволен ‘по моральной идиосинкразии’.
Корреспондент заводской газеты обувного объединения ‘Скороход’ ‘Скороходовский рабочий’, и.о. завотделом культуры, и.о. завотделом информации. Первые публикации рассказов в ‘официальной государственной прессе’. Ежегодная премия газеты за лучший материал по культуре. Уволен ‘по моральной идиосинкразии’.
1976 г. С мая по октябрь работает перегонщиком импортного скота из Монголии в Бийск по Алтайским горам. По упоминаниям в текстах, вспоминал это время как лучшее и крутое в своей жизни.
Осенью, вернувшись в Ленинград, всецело переключается на литературную работу. Классический вариант: первые рассказы отклоняются всеми редакциями.
1977 г. — В мае пешком и на попутных машинах отправляется на Черное море. До октября бродяжит по черноморскому побережью от Одессы до Батуми.
Осенью вступает в семинар молодых ленинградских фантастов под руководством Бориса Стругацкого. За рассказ ‘Кнопка’ получает первую премию на конкурсе фантастов Северо-запада.
Участвует в Конференции молодых писателей Северо-запада. Рассказы отмечены и одобрены, но к публикации руководством конференции не рекомендованы /?!/.
Рассказы отмечены и одобрены, но к публикации руководством конференции не рекомендованы /?!/.
Нигде не работает. Период полного нищенства.
1978 г. — Первые публикации в городских ленинградских газетах — короткие юмористические рассказы.
Лето — вальщик леса в госхозе ‘Усть-Куломский’ в Коми АССР, бригадир железнодорожных путейцев-строителей там же.
Осень-зима — кратковременная служба в Советской Армии: старший офицер батареи наземной артиллерии, старший лейтенант.
1979 г. — Рассказы по-прежнему отклоняются всеми журналами и издательствами.
Премия на очередном конкурсе фантастов Севера-Запада.
Приработок литобработкой военных мемуаров при издательстве ‘Лениздат’ и рецензиями в журнале ‘Нева’.
Вступление в студию прозы при журнале ‘Звезда’ с намерением облегчить себе публикации. Публикаций не следует.
Осень — переезд в Эстонию, в Таллинн, в попытке издать сборник рассказов в местном издательстве. Работа в республиканской газете ‘Молодежь Эстонии’.
Книга отклонена издательством ‘Ээсти Раамат’.
1980 г. — Первые публикации в журналах: ‘Таллин’, ‘Литературная Армения’, ‘Урал’.
Увольнение из газеты.
Вступление в ‘профсоюзную группу’ при Союзе писателей Эстонии, что давало право в СССР официально не работать.
Лето-осень — путешествие из Ленинграда в Баку на грузовом судне, репортажи с пути в газету ‘Водный транспорт’. Бродяжничество по Кавказу и Закавказью.
1981 г. — Книга одобрена и принята издательством.
В Эстонском кукольном театре ставится пьеса ‘Настоящий слоненок’, выплачен гонорар.
1982 г. — Работа в госпромхозе ‘Таймырский’ в районе низовий руки Пясины в качестве охотника-промысловика.
1983 г. — Выход первой книги — сборника рассказов ‘Хочу быть дворником’. Первые рецензии, рекомендации в Союз писателей от Бориса Стругацкого и Булата Окуджавы. Участие в Московской международной книжной выставке-ярмарке. Продажа прав за рубеж.
1984 г. — Перевод книги на эстонский, армянский, бурятский языки. Переводы отдельных рассказов во Франции, Италии, Голландии, Болгарии, Польше.
1985 г. — Летняя работа в археологической экспедиции в Ольвии и на острове Березань. Осень-зима: рабочий-кровельщик.
1986 г. — Женитьба на выпускнице факультета журналистики Московского университета Анне Агриомати.
1987 г. — Рождение дочери Валентины.
1988 г. — Выход второй книги рассказов ‘Разбиватель сердец’. Прием в Союз писателей СССР.
Заведующий отделом русской литературы таллиннского русскоязычного журнала ‘Радуга’ Первые публикации Бродского, Довлатова, Аксенова, Мандельштама, Введенского.
Первое в СССР издание книги Оруэлла ‘Скотский хутор’.
1989 г. — Первое издание книги ‘Технология рассказа’.
1990 г. — Публикация рассказа ‘Узкоколейка’ в журнале ‘Нева’,
рассказа ‘Хочу в Париж’ в журнале ‘Звезда’, рассказа ‘Положение во гроб’ в журнале ‘Огонек’.
Статус профессионального писателя.
Выходит книга ‘Рандеву со знаменитостью’.
Появление публикаций рассказов в эмигрантской русской прессе.
По рассказу ‘А вот те шиш’ поставлен художественный фильм на Мосфильмовской студии ‘Дебют’.
Главный редактор и основатель первого в СССР еврейского культурного журнала ‘Иерихон’. Выпуск первого номера.
Октябрь-ноябрь — чтение лекций по русской прозе в университетах Милана и Турина.
1991 г. — Первое издание романа ‘Приключения майора Звягина’ — в Ленинграде, но под маркой эстонского издательства ‘Периодика’. Стотысячный тираж разошелся в три недели.
1993 г. — Ни одно российское издательство не принимает книгу новелл ‘Легенды Невского проспекта’. Тиражом 500 экз. ее издает в Таллинне Эстонский фонд культуры.
1994 г. — Очередное стотысячное издание ‘Приключений майора Звягина’ возглавляет топ-десятку ‘Книжного обозрения’.
Чтение лекций по современной русской прозе в университете Оденсе /Дания/.
1995 г. — Петербургское издательство ‘Лань’ массовыми дешевыми изданиями выпускает ‘Легенды Невского проспекта’ — продано около 800 000 экз. Самая читаемая книга года в Санкт-Петербурге. Следуют переиздания всех книг в ‘Лани’, издательствах ‘Вагриус’ (Москва), ‘Нева’ (Санкт-Петербург), ‘Фолио’ (Харьков).
На осенней Московской книжной ярмарке Веллер — самый издаваемый русский писатель года.
1996 г. — Летом со всей семьей надолго уезжает в Израиль.
В ноябре новый роман ‘Самовар’ первым изданием выходит в иерусалимском издательстве ‘Миры’. Презентации книги в правительственном пресс-центре и на тель-авивской новогодней ярмарке.
Лекции по современной русской прозе в Иерусалимском университете.
1997 г. — Апрель — возвращение в Эстонию.
Сентябрь — выпуск четырехтомника двухсоттысячным тиражом петербургским финансовым холдингом ‘Объединенный капитал’.
1998 г. — Выход восьмисотстраничной философской ‘всеобщей теории всего’ ‘Все о жизни’.
Поездка по Германии с читательскими встречами и выступлениями в Гамбурге, Бремене, Берлине, Дрездене, Ганновере, Кельне, Ахене.
Читательские встречи в Голландии — Амстердам и Роттердам.
Голландский фильм по рассказу ‘Колечко’ представлен на кинофестивале в Амстердаме.
1999 г. — Издательство ‘ОЛМА-ПРЕСС’ более двадцати раз переиздает книги Веллера в разных форматах и обложках массовыми тиражами.
Поездка по США с выступлениями перед читателями в Нью-Йорке, Бостоне, Кливленде, Чикаго.
Выход книги рассказов ‘Памятник Дантесу’.
2000 г. — Новый роман ‘Гонец из Пизы’, он же первоначально ‘Ноль часов’. Бесчисленные переиздания.
Кажется, фактический переезд в Москву.
По слухам — работа над книгой ‘Легенды очень нового Арбата’.
Тренинг «НЛП-ПРАКТИК»
Хотите учиться у лучших?
Забронируйте место
на выгодных условиях
Для тех, кто стремится к успеху в бизнесе, карьере, отношениях
Старт 9 сентября Онлайн
6-7 ноября живой в Москве
Пошаговая 8-ми модульная система обучения (подходит для начинающих)
Инна Паустовская — опытный тренер команды со-основателя НЛП Фрэнка Пьюселика и его последователь
Международный сертификат «NLP Practitioner», признаваемый во всем мире
Три самые распространенные «страшилки» про НЛП
Нечестный способ управления людьми
Зомбирование и воздействие под гипнозом
Манипуляции подсознанием
А что на самом деле?
Настоящее НЛП – экологичный и эффективный способ выстраивания коммуникаций с окружающим миром, который помогает:
Найти общий язык с другими людьми, выстроить гармоничные взаимоотношения
Решать проблемы во всех сферах жизни, работая со своими убеждениями
Понимать истинные намерения людей, отличать правду от лжи и реагировать соответственно ситуации
НЛП моделирует опыт успешных людей и позволяет использовать это для повышения качества и эффективности собственной жизни. Приглашаем и Вас совершить мощный рывок в новую реальность.
Приглашаем и Вас совершить мощный рывок в новую реальность.
Курс «НЛП-Практик» ведет прямая последовательница Фрэнка Пьюселика – одного из разработчиков НЛП, тренер его команды, международный тренер NLP — Инна Паустовская
«Инна – одна из моих особенных тренеров. Она талантлива, трудолюбива, понимает НЛП лучше, чем большинство людей.. Вы получите знания, вырастите. Вам будет весело! Вы правильно выбрали тренера!..»
Что Вы сможете благодаря тренингу:
Быстро устанавливать контакты и создавать полезные связи с важными людьми
Быть успешным в переговорах и управлении командой
Стремительно и эффективно достигать поставленных целей
Решать конфликты и убеждать оппонентов в своей правоте
Продвигаться по карьерной лестнице, строить собственный бизнес и больше зарабатывать
Справиться со своими страхами и фобиями, преодолеть внутренние барьеры и ограничители
Наладить отношения (семья, друзья, начальство, дети)
Уметь управлять своим внутренним эмоциональным состоянием
Тренинг «НЛП-Практик» –
первая ступень в изучении нейро-лингвистического программирования
Для эффективного усвоения материала
в программу тренинга включены:
Живой в Москве
Упражнения в малых группах
Видеоуроки и вебинары
Деловые и ролевые игры
«Живые» отработки в zoom в парах и группе
Поддержка куратора и чата
Упражнения и домашние задания
20% теории 80% практики в живом формате
125 видеоуроков + 84 часа практики в формате онлайн
Почему Вам стоит обучаться именно здесь:
Профессиональный тренер
Тренер – ИННА ПАУСТОВСКАЯ, с большим практическим опытом работы. Последователь Фрэнка Пьюселика. Подача информации, харизма тренера помогут Вам получить первые результаты уже в процессе прохождения тренинга.
Последователь Фрэнка Пьюселика. Подача информации, харизма тренера помогут Вам получить первые результаты уже в процессе прохождения тренинга.
• Международный сертифицированный тренер NLP, сертифицированный бизнес-тренер, тренер программ личного развития
• Тренер META Int., команды Френка Пьюселика, одного из основателей НЛП
• Клинический психолог, системный семейный психолог
• Профессиональный консультант со стажем более 10 лет
Соответствие международным стандартам
Будьте осторожны! Сейчас появилось огромное количество компаний, обучающих НЛП.
Но… Ключевым навыкам НЛП можно научится только у компетентного и лицензированного тренера! Обучаясь на нашем тренинге «НЛП-Практик», Вы получаете информацию от тренеров, которые лично обучались у со-основателя НЛП Фрэнка Пьюселика и работают в его команде.
Экологичность методов
Многие тренеры искажают сущность НЛП и используют манипулятивный подход. В нашем тренинге Вы работаете над собой, а не манипулируете другими, изменяете тактики своего поведения и с помощью этого меняете свою жизнь и жизнь вокруг Вас.
Наставничество и работа в мини-группах
Вы отрабатываете упражнения в парах или тройках. За эффективностью усвоения материала и правильностью выполнения всегда следит личный куратор.
Специальная авторская программа для контроля собственных изменений и достижения желаемых целей
Имея эту программу, Вы всегда будете знать ориентир в своем развитии и сможете получить своевременную поддержку и ответы на возникшие вопросы между модулями.
Сертификат международного образца после окончания тренинга
После тренинга Вы проходите независимую сертификацию у приглашенных экспертов.
Участники имеют возможность получить международный сертификат компании «МЕТА International Inc.», которая основана в Калифорнии в 1977 году Джоном Гриндером и Фрэнком Пьюселиком, как первая сертифицирующая организация для проведения тренингов НЛП всех уровней
Сертификат признается во всем мировом сообществе НЛП.
Если по какой-то причине Вы не сдадите экзамен, Вы получите сертификат участника тренинга НЛП.
Гарантия для каждого участника тренинга «НЛП-Практик»
Мы гарантируем высокое качество, полезность и эффективность предоставляемой информации. Каждый тренер центра имеет профильное образование международной сертификации и большой практический опыт обучения.
Но если по какой-то причине Вы поймете, что наша система не подходит для Вас, в течение первого дня тренинга сообщите об этом организаторам и получите назад свои деньги.
Вы ничем не рискуете!
Забронируйте место и сделайте
первый шаг к новым горизонтам в жизни.
НЛП открывает огромные возможности по улучшению всех сфер жизни:
Семья и отношения
Работа и бизнес
Общение и коммуникация
Финансы и личная эффективность
Здоровье и энергия для действий
Формат обучения
живого тренинга
Живой тренинг в МСК старт 6-7 ноября
Структура – 8 полноценных разноплановых модулей
Межмодульные встречи, отработки, 1 раз в месяц вечером
Продолжительность – 8 месяцев, 1 модуль в месяц
Занятия 1 раз в месяц —
суббота и воскресенье с 10:00 до 18:00
Формат обучения
онлайн тренинга
ОНЛАЙН тренинг, старт 9 сентября
Структура — 8 разноплановых модулей.
125 видеоуроков + 84 часа практикии
Отработка в мини группах и поддержка в чате
Продолжительность 8 месяцев, 1 модуль в месяц
1 раз в неделю практика в zoom (4 за месяц)
20-25 видеоуроков в месяц
Каждый участник получает
ЖИВОЙ в МОСКВЕ
Доступ к видеоурокам на платформе на год
Вебинары и «живая» отработка в zoom в парах и группе
Раздаточные обучающие материалы
Проверка домашних заданий
Доступ в закрытый чат
Поддержка и помощь кураторов
Поддержка и помощь кураторов
Участие и практика в межмодульных встречах
Раздаточные обучающие материалы
Доступ в закрытый чат
Видеозапись всего тренинга
Список литературы
Стоимость тренинга
«НЛП-Практик»
Живой тренинг в Москве и онлайн одинаковая стоимость, так как программа и упражнения ничем не отличаются и даются максимально полно одинаково в обоих форматах
Оплата за весь тренинг
До 15 августа — 68 000 руб
(8500 руб за модуль при единовременной оплате)
До 18 сентября — 80 000 руб
(10 000 руб за модуль при единовременной оплате)
*для того, чтобы забронировать место по этой цене, внесите предоплату 5000 р. и остаток оплатите до старта тренинга
Оплата помодульно
Стоимость 1 модуля
До 15 августа — 12 500 руб
До 18 сентября — 15 000 руб
*при бронировании сейчас эта стоимость сохраняется за Вами на все модули тренинга
Подробнее о программе тренинга
(нажмите на название и ознакомьтесь с программой модуля)
Ближайший тренинг стартуеТ
9 сентября онлайн и 6 ноября живой в Москве
Всего 30 участников в группе. По объективным причинам мы не возьмем всех желающих, так как заинтересованы в успехах каждого ученика и качественной обратной связи, что невозможно при больших группах.
Узнайте подробности участия и
забронируйте место на лучших условия:
P. S. Следующий поток будет набираться только через 12 месяцев.
S. Следующий поток будет набираться только через 12 месяцев.
Подумайте, стоит ли откладывать свою жизнь на потом…
Ведь уже в этом году Вы можете получить следующие результаты:
Обретете уверенность в себе
Высокий уровень мотивации на пути к целям. Избавитесь от страха неудачи. Научитесь вести за собой других
Отпустите негативное прошлое
Избавитесь от болезненных воспоминаний, барьеров, ложных убеждений
Повысите самооценку
Трансформируете слабые стороны в сильные. Поверите в себя и безграничные возможности
Сможете управлять эмоциями и конфликтами
Эмоции под контролем! Быстрое решение конфликтов. Избавитесь от стресса. Повысите продуктивность
Избавитесь от стресса. Повысите продуктивность
Научитесь эффективной коммуникации
Научитесь выстраивать доверительные отношения. Расширите круг общения. Избавитесь от страха выступлений перед публикой
Поймете как быстро достигать целей
Изучите стратегии правильной постановки и достижения целей. Мечты начнут исполняться!
Важно! Полученные результаты НЕ исчезнут со временем
1. Это не краткосрочный эффект, а трансформация, при которой Ваша жизнь меняется навсегда.
2. Вы получаете навыки НЛП и профессию, признанную и востребованную во всем мире.
Посмотрите, что ждет Вас на тренинге
Вот что говорят выпускники предыдущих потоков тренинга «НЛП-Практик»
Еще три гири на чашу весов в пользу тренинга «НЛП-Практик»
БЕЗ ВОДЫ
только проверенная информация
БЕЗ ХАОСА
Систематизированный, логичный материал
БЕЗ ЛИШНЕГО
Только то, что используется на практике
Как принять участие в тренинге «НЛП-Практик»
Оставить заявку на сайте
Выбрать вариант участия и оплатить
Забронировать место
Участвовать и получить
результат
Получите эффективные инструменты и станьте Хозяином своей Жизни
NLP: Rainbow от Юрия Радченко — более подробная информация, чем в App Store и Google Play от AppGrooves — Настольные игры
ЦЕЛЬ ИГРЫ: переход в состояние высокой производительности (HPS). Состояние характеризуется более высокой мозговой активностью (по сравнению с обычным состоянием). Он помогает принимать решения, получать ответы на сложные вопросы, находить выходы из проблемных ситуаций и, возможно, даже кардинально менять отношение к таким ситуациям.
Состояние характеризуется более высокой мозговой активностью (по сравнению с обычным состоянием). Он помогает принимать решения, получать ответы на сложные вопросы, находить выходы из проблемных ситуаций и, возможно, даже кардинально менять отношение к таким ситуациям. В разных частях экрана случайным образом отображается название слова — цветное название слова «CLAP».Цвет слова тоже выбирается случайным образом. Вам нужно произнести цвет (а не написанное слово) и хлопнуть в ладоши, если вы видите слово «CLAP».
*** НАСТРОЙКИ ИГРЫ ***
В настройках игры вы можете выбрать:
• 9 цветов для игры: синий, зеленый, красный, коричневый, оранжевый, розовый, фиолетовый, желтый, бирюзовый.
• Процент соответствия цвета и названия цвета.
• Стиль написания слов.
• Процент хлопков для игры, с учетом или без учета положения ладоней при хлопке.
• Расположение текста на экране: случайное или по центру.
• Музыка и звуки во время игры и по ее окончании.
Кроме того, вы можете выбрать язык для названий цветов:
английский, русский, немецкий, французский, испанский, португальский, итальянский, украинский, белорусский, казахский, арабский, иврит, польский, чешский, румынский, венгерский, сербский, эстонский , Латышский, литовский, грузинский, армянский, азербайджанский, турецкий, греческий, албанский, хорватский, шведский, датский, голландский, финский, норвежский, боснийский, болгарский, македонский, словацкий, словенский, ирландский, исландский, тайский, филиппинский, вьетнамский, японский , Корейский, китайский
*** ПРАВИЛА ИГРЫ ***
НАЧАЛО ИГРЫ
Подумайте о проблемной ситуации: представьте ее, запомните звуки, положение тела, почувствуйте это, запишите. Как можно больше ассоциируйте себя с проблемной ситуацией или задачей.
Как можно больше ассоциируйте себя с проблемной ситуацией или задачей.
ПЕРЕХОД К ИГРЕ
Измените положение тела, вдохните, потрясите плечами. И сразу же запускаем игру.
САМА ИГРА
Выберите скорость игры, чтобы она была для вас сложной и достаточно интересной, чтобы игра была с азартом.
Выберите время игры: минимум 2 минуты, рекомендуется 10-15 минут.
Запускаем игру.
На экране отображается слово любого цвета с названием случайного цвета или слово «хлопать».Иногда название цвета и отражаемый цвет могут совпадать, иногда нет. Вы должны говорить цвет независимо от написанного слова. При этом, если отображается слово «хлопок», нужно хлопать в ладоши.
Усложнить игру можно в настройках:
1. Выбрать дополнительные цвета.
2. Установите вариант разных слов для хлопка. Хлопать в ладоши так, чтобы левая или правая ладонь была сверху при хлопке.
3. От руки показать направления, в которых появилось слово.
ЗАКЛЮЧИТЕЛЬНАЯ ЧАСТЬ
Вернитесь в контекст задачи. Может быть, сразу не получится. Для этого нужно приложить все усилия. Это важно.
Может быть, сразу не получится. Для этого нужно приложить все усилия. Это важно.
Реализуй задачу еще раз. Обратите внимание на изменение вашего отношения к задаче.
ЗНАЕТЕ ЛИ ВЫ, ЧТО
Игра является одной из игр НЛП New Code (нейро-лингвистическое программирование), которые дают равномерную и безопасную нагрузку на мозг и помогают перейти в состояние высокой производительности. Это позволяет на какое-то время по-другому взглянуть на мир.
Рекомендуется играть регулярно — 2-3 раза в неделю.
В этой игре используется эффект Струпа (исследование этого эффекта опубликовано в 1935 году) — задержка реакции на чтение слова, если это слово означает один цвет, а написано другим.
Если возникнут проблемы, напишите мне:
Настройки -> О приложении -> Написать или [email protected]
Нейролингвистическое программирование | Лайф-коучинг Purple Genie
НЛП, как известно многим, — это нейро-лингвистическое программирование, и его приложения использовались по всему миру для огромного количества преобразований для людей.
Редко что что-либо так положительно влияло на психологическое благополучие стольких людей за такой короткий промежуток времени. Его истоки — модели трех терапевтов, которые добились огромных успехов в создании огромных положительных изменений для клиентов.
Не просто клиенты, они часто получали тяжелые травмы или жили со странными проблемами, в которых психиатры, психологи и консультанты часто не могли помочь.
Затем область продолжила расширяться и изучать передовые навыки в других областях, таких как спортивные результаты, в которых вопрос заключался в том, как спортсмены попадают в зону?
Одним из примеров является то, что спортивные игроки четко визуализируют в своем уме, как идеально ударяют по мячу для гольфа, с яркими микроскопическими деталями.Другой способ — сделать вид, будто это первый выстрел. Другой — выяснить, что у игроков в гольф есть собственная стратегия мышления, которая приводит их в состояние высокой результативности. Другой способ — использовать техники НЛП Нового кода, чтобы ввести человека в состояние.
Вопрос всегда заключался в том, какая разница, которая отличает?
Существует так много методов лечения, которые помогают клиентам измениться, и именно НЛП поднялось на голову выше остальных, потому что эти методы позволяют людям меняться эффективно, надолго и быстро.
На примере депрессии некоторые психологи собирают группы депрессивных людей на собрания, чтобы они могли сидеть и обсуждать свою депрессию, другие рекомендовали тратить месяцы на разговоры о детстве и выяснение причин депрессии, третьи заставляли людей принимать лекарства, как наш доктора сегодня.
Практикующие НЛП обратились непосредственно к людям, которые находились в депрессивном состоянии и преодолели депрессию, и выяснили, что именно эти люди сделали психологически, чтобы пережить это.
Они сделали то же самое с людьми, которые пережили фобии, проблемы с гневом и все, что вы можете прочитать на этом сайте. НЛП в терапии использует то, что работает, оно изменило нашу жизнь и изменит вашу жизнь.
НЛП существует с 70-х годов, нам посчастливилось обучаться Новому Кодексу, который представляет собой новейшие разработки НЛП, которые были развиты Кармен Бостик Сент-Клер и человеком, который соавтором НЛП и лично моделировал эти три. терапевты, о которых вы читали, Джон Гриндер.
Нас также обучал Майкл Кэрролл, ведущий тренер Академии обучения № 1 в Великобритании и Европе, NLP Academy.
Все началось на семинаре Энтони Роббинса в Лондоне, и с тех пор мы изучили многих других лидеров в этой области, включая другого соавтора классического НЛП Ричарда Бэндлера, который руководит ведущим учебным заведением в США.
Мы вместе читали книги, слушали аудиозаписи и смотрели видеозаписи успешных практикующих в этой области, и теперь мы делаем свои собственные и жертвуем.
Для большей ясности в том, что такое НЛП, вы можете прочитать наш блог и посмотреть видео о том, что такое НЛП?
Turbo, улучшенная цветовая карта радуги для визуализации
Варианты использования расходящейся картыХотя карта цветов Turbo была разработана для последовательного использования (т.
 Е. Значений [0-1]), ее также можно использовать в качестве расходящейся цветовой карты, например, в разностных изображениях. При таком использовании ноль означает зеленый цвет, отрицательные значения — оттенки синего, а положительные значения — оттенки красного.Однако обратите внимание, что отрицательный минимум темнее положительного максимума, поэтому он не сбалансирован.
Е. Значений [0-1]), ее также можно использовать в качестве расходящейся цветовой карты, например, в разностных изображениях. При таком использовании ноль означает зеленый цвет, отрицательные значения — оттенки синего, а положительные значения — оттенки красного.Однако обратите внимание, что отрицательный минимум темнее положительного максимума, поэтому он не сбалансирован. | Изображение несоответствия «наземной истины» | Расчетное изображение несоответствия |
| Изображение различия (истинное — оценочное изображение), визуализированное с помощью Turbo |
Мы протестировали Turbo с помощью симулятора дальтонизма и обнаружили, что для всех условий, кроме ахроматопсии (полная дальтонизм), карта остается различимой и гладкой.
 В случае ахроматопсии низкие и высокие значения неоднозначны. Поскольку заболевание поражает 1 из 30 000 человек (или 0,00003%), Turbo должны использовать 99,997% населения.
В случае ахроматопсии низкие и высокие значения неоднозначны. Поскольку заболевание поражает 1 из 30 000 человек (или 0,00003%), Turbo должны использовать 99,997% населения. | Тестовое изображение |
Turbo является заменой Jet и предназначен для повседневных задач, где единообразие восприятия не критично, но все же требуется высококонтрастная и плавная визуализация базовых данных.Ее можно использовать как последовательную, так и расходящуюся карту, что делает ее хорошей универсальной картой в наборе инструментов. Вы можете найти данные цветовой карты и инструкции по использованию для Python здесь и для C / C ++ здесь. Здесь также есть полиномиальное приближение для случаев, когда справочная таблица может быть нежелательной. Наша команда использует ее для визуализации карт диспаратности, карт ошибок и различных других скалярных величин, и мы надеемся, что вы также найдете это полезным .

Благодарности
Амбрус Часар вместе со мной рассматривал множество цветовых палитр, чтобы выбрать правильный компромисс между единообразием и акцентированием деталей.Кристиан Хене интегрировал карту в инструменты нашей команды, которые стали широко использоваться и, таким образом, стимулировали дальнейшие улучшения. Матиас Крамм и Руофей Ду предложили приближения в закрытой форме.
Карты ложных цветов используются во многих приложениях компьютерного зрения и машинного обучения, от визуализации изображений глубины до более абстрактных применений, таких как различие изображений. Раскрашивание изображений помогает зрительной системе человека выделять детали, оценивать количественные значения и замечать закономерности в данных более интуитивно понятным образом.Однако выбор цветовой карты может существенно повлиять на поставленную задачу. Например, интерпретация «радужных карт» связана с более низкой точностью в критически важных приложениях, таких как получение медицинских изображений. Тем не менее, во многих приложениях предпочтительны «радужные карты», поскольку они показывают больше деталей (за счет точности) и позволяют более быструю визуальную оценку.
Тем не менее, во многих приложениях предпочтительны «радужные карты», поскольку они показывают больше деталей (за счет точности) и позволяют более быструю визуальную оценку.
| Слева: Изображение с неравномерностью отображается в оттенках серого. Справа: Часто используемая карта радуги Jet используется для создания изображения в ложных цветах. |
 Поскольку скорость, с которой цвет изменяется «в восприятии», непостоянна, Jet не является перцептивно однородным. Эти эффекты еще более выражены для пользователей с дальтонизмом, что делает карту неоднозначной:
Поскольку скорость, с которой цвет изменяется «в восприятии», непостоянна, Jet не является перцептивно однородным. Эти эффекты еще более выражены для пользователей с дальтонизмом, что делает карту неоднозначной: Сегодня существует множество современных альтернатив, которые являются единообразными и доступными для дальтоников, например Viridis или Inferno из matplotlib. Хотя эти линейные карты яркости решают многие важные проблемы с Jet, их ограничения могут сделать их неоптимальными для повседневных задач, где требования не такие строгие.
| Viridis | Inferno |
 Вы можете найти данные цветовой карты и инструкции по использованию для Python здесь и C / C ++ здесь, а также полиномиальное приближение здесь.
Вы можете найти данные цветовой карты и инструкции по использованию для Python здесь и C / C ++ здесь, а также полиномиальное приближение здесь. Разработка
Для создания цветовой карты Turbo мы создали простой интерфейс, который позволил нам интерактивно настраивать кривые sRGB с помощью 7-узлового кубического сплайна, сравнивая результат на выбранных образцах изображений, а также на других хорошо известных цветные карты.
| Снимок экрана интерфейса, используемого для создания и настройки Turbo. |
| |
| Turbo |
| Jet |
Viridis — это линейная цветовая карта, которая обычно рекомендуется, когда требуется ложный цвет, потому что это приятен для глаз и решает большинство проблем с Jet.
 Inferno имеет те же линейные свойства, что и Viridis , , но имеет более высокий контраст, что позволяет лучше различать детали. Однако некоторые считают, что это может быть резким для глаз. Хотя это не является проблемой для публикации, это влияет на выбор людей, когда им приходится тратить длительные периоды времени на изучение визуализаций.
Inferno имеет те же линейные свойства, что и Viridis , , но имеет более высокий контраст, что позволяет лучше различать детали. Однако некоторые считают, что это может быть резким для глаз. Хотя это не является проблемой для публикации, это влияет на выбор людей, когда им приходится тратить длительные периоды времени на изучение визуализаций. Из-за быстрой смены цвета и яркости Jet подчеркивает детали фона, которые менее заметны при использовании Viridis и даже Inferno. В зависимости от данных некоторые детали могут быть полностью потеряны невооруженным глазом.Фон на следующих изображениях едва различим в Inferno (который и так резче, чем Viridis), но четкий в Turbo.
| Inferno | Turbo |
 Это ценная функция, поскольку она значительно улучшает детализацию, когда можно использовать цвет для устранения неоднозначности низких и высоких частот.
Это ценная функция, поскольку она значительно улучшает детализацию, когда можно использовать цвет для устранения неоднозначности низких и высоких частот.| Графики яркости, созданные путем преобразования значений sRGB в CIECAM02-UCS и отображения значения яркости (J) в оттенках серого. Черная линия показывает значение яркости от нижнего края цветовой карты (слева) до верхнего края (справа). |

Хотя эта кривая «низкий-высокий-низкий» увеличивает детализацию, она достигается за счет неоднозначности легкости. При визуализации в оттенках серого окраска будет неоднозначной, поскольку некоторые из более низких значений будут выглядеть идентично более высоким значениям.Следовательно, Turbo не подходит для печати в оттенках серого и для людей с редким случаем ахроматопсии.
Семантические уровни
При изучении карт диспаратности часто бывает желательно сразу сравнить значения на разных сторонах изображения. Эта задача намного проще, когда значения можно мысленно сопоставить с отдельным семантическим цветом, например красным или синим. Таким образом, наличие большего количества цветов способствует простоте и точности оценки.
 Это намного сложнее определить с помощью Viridis или Inferno, у которых гораздо меньше различных цветов. По сравнению с Jet, Turbo также намного более плавный и не имеет «ложных слоев» из-за полос. Вы можете увидеть это улучшение более четко, если квантовать входящие значения:
Это намного сложнее определить с помощью Viridis или Inferno, у которых гораздо меньше различных цветов. По сравнению с Jet, Turbo также намного более плавный и не имеет «ложных слоев» из-за полос. Вы можете увидеть это улучшение более четко, если квантовать входящие значения: | Слева: Квантованная палитра Turbo. До 33 квантованных цветов остаются различимыми и плавными как по яркости, так и по изменению оттенка. Справа: Цветовая карта квантованной струи. Многие соседние цвета выглядят одинаково; Желтый и голубой цвета кажутся ярче остальных. |
При быстром сравнении двух изображений гораздо легче определить разницу в цвете, чем в яркости (поскольку наша система внимания уделяет приоритетное внимание оттенку). Например, представьте, что у нас есть выходное изображение из алгоритма оценки глубины рядом с наземной истиной.
 С Turbo легко понять, согласны ли они между собой, а какие регионы могут не согласиться.
С Turbo легко понять, согласны ли они между собой, а какие регионы могут не согласиться.| «Выход» Виридис | «Истина на земле» Виридис |
| Турбо «Выход» | Турбо «Истина на земле» |
Варианты использования расходящейся карты
Хотя цветовая карта Turbo была разработана для последовательного использования (т.е., значения [0-1]), его также можно использовать как расходящуюся цветовую карту, например, в разностных изображениях. При таком использовании ноль означает зеленый цвет, отрицательные значения — оттенки синего, а положительные значения — оттенки красного. Однако обратите внимание, что отрицательный минимум темнее положительного максимума, поэтому он не сбалансирован.
| Изображение несоответствия «наземной истины» | Расчетное изображение несоответствия |
| Изображение различия (истинное — оценочное изображение), визуализированное с помощью Turbo |
Мы протестировали Turbo с помощью симулятора дальтонизма и обнаружили, что для всех условий, кроме ахроматопсии (полная дальтонизм), карта остается различимой и гладкой.В случае ахроматопсии низкие и высокие значения неоднозначны. Поскольку заболевание поражает 1 из 30 000 человек (или 0,00003%), Turbo должны использовать 99,997% населения.
| Тестовое изображение |
Turbo представляет собой сменную замену Jet и предназначен для повседневных задач, где единообразие восприятия не критично, но все же необходимо высококонтрастная, плавная визуализация исходных данных.
 Ее можно использовать как последовательную, так и расходящуюся карту, что делает ее хорошей универсальной картой в наборе инструментов. Вы можете найти данные цветовой карты и инструкции по использованию для Python здесь и для C / C ++ здесь. Здесь также есть полиномиальное приближение для случаев, когда справочная таблица может быть нежелательной. Наша команда использует ее для визуализации карт диспаратности, карт ошибок и различных других скалярных величин, и мы надеемся, что вы также найдете это полезным .
Ее можно использовать как последовательную, так и расходящуюся карту, что делает ее хорошей универсальной картой в наборе инструментов. Вы можете найти данные цветовой карты и инструкции по использованию для Python здесь и для C / C ++ здесь. Здесь также есть полиномиальное приближение для случаев, когда справочная таблица может быть нежелательной. Наша команда использует ее для визуализации карт диспаратности, карт ошибок и различных других скалярных величин, и мы надеемся, что вы также найдете это полезным . Благодарности
Амбрус Часар вместе со мной рассматривал множество цветовых палитр, чтобы выбрать правильный компромисс между единообразием и акцентированием деталей.Кристиан Хене интегрировал карту в инструменты нашей команды, которые стали широко использоваться и, таким образом, стимулировали дальнейшие улучшения. Матиас Крамм и Руофей Ду предложили приближения в закрытой форме.
Программа лидерства в районе
Что такое программа добрососедского лидерства?
Программа развития местного лидерства проводится Городским бюро жилищного строительства и обслуживания районов Лонг-Бич. Эта многоязычная программа на пять (5) месяцев помогает местным жителям и предоставляет вам навыки, знания и ресурсы, необходимые для улучшения качества жизни в нашем сообществе.Эта программа бесплатна для участников и частично финансируется через Федеральную программу блочных грантов на развитие сообществ (CDBG).
Эта многоязычная программа на пять (5) месяцев помогает местным жителям и предоставляет вам навыки, знания и ресурсы, необходимые для улучшения качества жизни в нашем сообществе.Эта программа бесплатна для участников и частично финансируется через Федеральную программу блочных грантов на развитие сообществ (CDBG).
Программа лидерства в районе iClip
Эта программа поможет вам:
- Улучшите свои коммуникативные навыки
- Признать преимущества разнообразия
- Создавайте инновационные решения для улучшения вашего района
- Определите ресурсы и партнерские отношения
- Подать заявку на грант
- Спланировать и завершить общественный проект
- Обретите уверенность в себе как оратор
Познакомьтесь с лицами, принимающими решения в Лонг-Бич:
- Мэр и городской совет
- Лидеры сообществ, государственных и некоммерческих организаций
- Выпускники программы добрососедского лидерства
Для получения дополнительной информации, пожалуйста, обращайтесь в Бюро районных служб по телефону (562) 570-1010 или по электронной почте Франциско. [email protected]. Узнайте больше о Программе добрососедского лидерства, просмотрев брошюру ниже.
[email protected]. Узнайте больше о Программе добрососедского лидерства, просмотрев брошюру ниже.
Основные моменты информационного бюллетеня для выпускников
Класс 2019 года
Класс 2018 года
Класс 2017 года
Выпуск 2016 г.
Класс 2015 г.
Класс 2014 г., г. Йоккаити, Япония
Класс 2014 г.
Класс 2013 г.
Класс 2012 г.
Класс 2011 г.
Выпуск 2010 г.

Класс 2009 г.
Класс 2008 г.
Выпуск 2007 г.
Класс 2006 г.
Выпуск 2005 г.
Класс 2004 г.
Выпуск 2003 г.
Выпуск 2002 г.
Класс 2001 г.
Класс 2000 г.
Выпуск 1999 г.
Выпуск 1998 г.
1997 г. выпуска
Класс 1996 г.
Класс 1994 г.
Выпуск 1992 г.
NLPwin — Microsoft Research
Введение Люси Вандервенде *
* от имени всех, кто внес вклад в разработку NLPwin
NLPwin — это программный проект Microsoft Research, целью которого является предоставление инструментов обработки естественного языка для Windows (отсюда и NLPwin). Проект был начат в 1991 году, когда Microsoft открыла исследовательскую группу Microsoft; хотя активное развитие NLPwin продолжалось в течение 2002 года, он все еще регулярно обновляется, в основном для обслуживания машинного перевода.
Проект был начат в 1991 году, когда Microsoft открыла исследовательскую группу Microsoft; хотя активное развитие NLPwin продолжалось в течение 2002 года, он все еще регулярно обновляется, в основном для обслуживания машинного перевода.
NLPwin использовался и до сих пор используется в ряде продуктов Microsoft, среди которых Index Server (1992-3), Word Grammar Checker (анализ каждого предложения в логической форме с 1996 года), функция запросов на английском языке для SQL Server (SQL Server 1998 — 2000), интерфейс запросов на естественном языке для Encarta (1999, 2000), Intellishrink (2000) и, конечно же, Bing Translator.
Поскольку мы знали, что разрабатываем NLPwin отчасти для поддержки средства проверки грамматики, грамматика NLPwin разработана так, чтобы обеспечивать широкий охват (т.е. не зависящую от предметной области) и быть устойчивой, в частности, устойчивой к грамматическим ошибкам. Хотя большинство грамматик изучается из данных, аннотированных в PennTreeBank, интересно учитывать, что такие грамматики могут быть не в состоянии анализировать неграмматическую или фрагментированную грамматику, поскольку эти грамматики не имеют обучающих данных для такого ввода. Грамматика NLPwin производит синтаксический анализ для любого ввода, и если охватывающий синтаксический анализ не может быть назначен, он создает «подобранный» синтаксический анализ, объединяющий самые большие составляющие, которые он смог построить.
Грамматика NLPwin производит синтаксический анализ для любого ввода, и если охватывающий синтаксический анализ не может быть назначен, он создает «подобранный» синтаксический анализ, объединяющий самые большие составляющие, которые он смог построить.
Радуга НЛП: мы предвидели, что с еще более сложными возможностями анализа можно будет создавать самые разнообразные приложения. Как вы можете видеть ниже, компонент генерации не был хорошо разработан, и мы постулировали приложения NL для генерации так же, как надеются на горшок с золотом в конце радуги. Наши первые модели машинного перевода передавались на семантическом уровне (статьи до 2002 г.), в то время как сегодня наши машинные переводы передаются в основном на синтаксическом уровне, используя смесь моделей, основанных на синтаксисе и фразе.
Рис. 1. Радуга НЛП (1991), наше первоначальное видение необходимых компонентов НЛП и возможных приложений.
Архитектура следует конвейерному подходу, как показано на рисунке 2, где каждый компонент обеспечивает дополнительные уровни анализа / аннотации входных данных. Мы спроектировали систему как относительно бедную вначале, используя при этом все более богатые и богатые источники данных, поскольку потребность в дополнительной семантической информации возрастала; одна из наших целей этой архитектуры — сохранить неоднозначность до тех пор, пока нам не понадобится разрешить эту неоднозначность или пока ресурсы данных не существуют, чтобы разрешить разрешение.Таким образом, синтаксический анализ проходит в два этапа: синтаксический набросок (который сегодня можно описать как плотный лес) и синтаксический портрет, где мы «распаковываем» лес и конструируем составляющий уровень анализа, который является синтаксическим, но также и семантически действительный. Дерево клиентов продолжает уточняться даже во время обработки логической формы, поскольку может использоваться более глобальная информация.
Мы спроектировали систему как относительно бедную вначале, используя при этом все более богатые и богатые источники данных, поскольку потребность в дополнительной семантической информации возрастала; одна из наших целей этой архитектуры — сохранить неоднозначность до тех пор, пока нам не понадобится разрешить эту неоднозначность или пока ресурсы данных не существуют, чтобы разрешить разрешение.Таким образом, синтаксический анализ проходит в два этапа: синтаксический набросок (который сегодня можно описать как плотный лес) и синтаксический портрет, где мы «распаковываем» лес и конструируем составляющий уровень анализа, который является синтаксическим, но также и семантически действительный. Дерево клиентов продолжает уточняться даже во время обработки логической формы, поскольку может использоваться более глобальная информация.
Рисунок 2: Компоненты NLPwin и схематическое изображение их выходного представления.
Стоит сделать несколько замечаний о синтаксическом анализаторе (термин, который в общих чертах объединяет модули морфологии, эскиза и портрета). Во-первых, парсер состоит из правил, созданных человеком. Это вызовет недоверие у тех, кто знаком только с машинно-обученными парсерами, обученными на PennTreeBank. Следует иметь в виду, что синтаксический анализатор NLPwin был создан до того, как первый синтаксический анализатор был обучен на PennTreeBank, что синтаксический анализатор должен был быть быстрым (для поддержки средства проверки грамматики) и что написание правил грамматики было нормой для грамматик до PennTreeBank.Кроме того, грамматик, которому было поручено писать правила, поддерживался сложным набором инструментов разработчика НЛП (созданным Джорджем Хайдорном), так же, как программист теперь поддерживается в Visual Studio, где правила грамматики могут запускаться в определенные точки кода и из них. , переменные могут быть изменены в интерактивном режиме для исследовательских целей, и, что наиболее важно, среда разработчика поддерживала запуск набора тестовых файлов с интерфейсами для грамматика для обновления целевых файлов с помощью улучшенного синтаксического анализа.
Во-первых, парсер состоит из правил, созданных человеком. Это вызовет недоверие у тех, кто знаком только с машинно-обученными парсерами, обученными на PennTreeBank. Следует иметь в виду, что синтаксический анализатор NLPwin был создан до того, как первый синтаксический анализатор был обучен на PennTreeBank, что синтаксический анализатор должен был быть быстрым (для поддержки средства проверки грамматики) и что написание правил грамматики было нормой для грамматик до PennTreeBank.Кроме того, грамматик, которому было поручено писать правила, поддерживался сложным набором инструментов разработчика НЛП (созданным Джорджем Хайдорном), так же, как программист теперь поддерживается в Visual Studio, где правила грамматики могут запускаться в определенные точки кода и из них. , переменные могут быть изменены в интерактивном режиме для исследовательских целей, и, что наиболее важно, среда разработчика поддерживала запуск набора тестовых файлов с интерфейсами для грамматика для обновления целевых файлов с помощью улучшенного синтаксического анализа.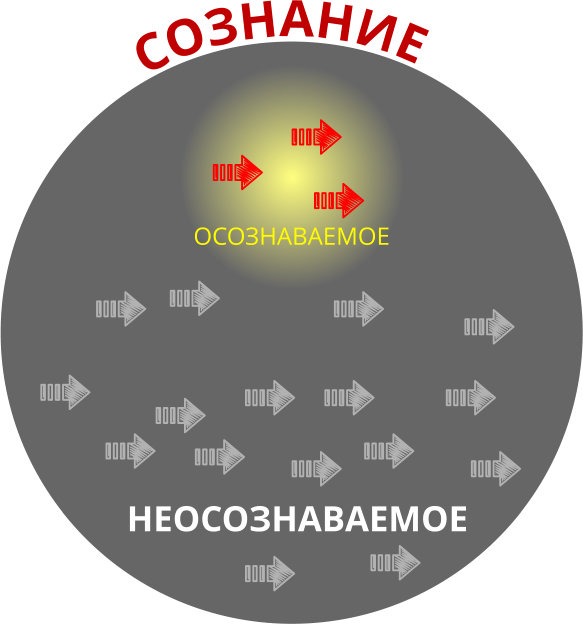 Во-вторых, ведущий грамматист Карен Дженсен нарушила имплицитную традицию, согласно которой составляющая структура подразумевается применением правил синтаксического анализа [1]. Дженсен заметил, что бинарные правила необходимы даже для того, чтобы справляться даже с обычными языковыми явлениями, такими как свободный порядок слов, а также размещение наречных и предложных фраз. Таким образом, в NLPwin мы используем двоичные правила в формализме расширенной грамматики структуры фраз (APSG), вычисляя структуру фразы как часть действий правил, тем самым создавая узлы с неограниченными модификаторами, сохраняя при этом двоичные правила, как показано на рисунке 3.
Во-вторых, ведущий грамматист Карен Дженсен нарушила имплицитную традицию, согласно которой составляющая структура подразумевается применением правил синтаксического анализа [1]. Дженсен заметил, что бинарные правила необходимы даже для того, чтобы справляться даже с обычными языковыми явлениями, такими как свободный порядок слов, а также размещение наречных и предложных фраз. Таким образом, в NLPwin мы используем двоичные правила в формализме расширенной грамматики структуры фраз (APSG), вычисляя структуру фразы как часть действий правил, тем самым создавая узлы с неограниченными модификаторами, сохраняя при этом двоичные правила, как показано на рисунке 3.
Рисунок 3: Дерево вывода отображает историю применения правил, а вычисленное дерево обеспечивает полезную визуализацию структуры фраз.
Еще одним важным аспектом NLPwin является то, что именно структура записи, а не деревья, является основным результатом работы компонента анализа (показано на рисунке 4). Деревья — это просто удобная форма отображения, использующая только 5 из множества атрибутов, составляющих представление анализа (предварительные модификаторы (PRMODS), HEAD, постмодификаторы (PSMODS), тип сегмента (SEGTYPE) и строковое значение. Вот запись, набор атрибутов и значений для узла DECL1:
Вот запись, набор атрибутов и значений для узла DECL1:
Рис. 4: Структура записи любого компонента является сердцем анализа NLPwin.
Как только основная форма дерева округа определена, можно вычислить, что такое логическая форма. У логической формы двоякая цель: вычислить структуру предиката-аргумента для каждого предложения («кто что сделал, с кем, когда, где и как?») И нормализовать различные синтаксические реализации того, что можно считать одним и тем же «значением».Поступая таким образом, концепции, которые, возможно, далеки в предложении и в составной структуре, могут быть сведены воедино, в значительной степени потому, что логическая форма представлена в виде графа, в котором линейный порядок больше не является первичным. Логическая форма — это ориентированный помеченный граф, где дуги помечены теми отношениями, которые определены как семантические, а поверхностные слова, передающие только синтаксическую информацию, представлены не как узлы в графе, а как аннотации к узлам, сохраняя их синтаксис. информация (не показана на графике ниже).Рассмотрим следующую логическую форму:
Рисунок 5: Пример логической формы.
График логической формы на рисунке 5 представляет прямую связь между «слонами» и «иметь», которая прерывается относительным предложением в поверхностном синтаксисе. Более того, при анализе относительного придаточного предложения логическая форма выполнила две операции: логическая форма нормализует пассивную конструкцию, а также присваивает референт относительного местоимения «который». Другие операции, обычно выполняемые логической формой, включают (но не ограничиваются ими): неограниченные зависимости, функциональный контроль, косвенное перефразирование объекта, назначение модификаторов.
Рисунок 5 также демонстрирует некоторые недостатки логической формы: 1) должен ли «иметь» быть концептуальным узлом в этом графе или его следует интерпретировать как дугу, помеченную как Часть между «слоном» и «бивнем»? В более общем плане: каким должен быть перечень меток отношений и как его определять? И 2) следует ли нам делать вывод из этого предложения только о том, что «на африканских слонов охотились» и что «у африканских слонов большие бивни», или мы можем сделать вывод, что «на слонов охотились» и что они оказались «африканскими слонами».Решение этого вопроса об объеме было отложено до обработки дискурса [2], когда такие вопросы могут быть рассмотрены, и логическая форма не представляет двусмысленности в области видимости.
Во время разработки конвейера NLPwin (см. Рисунок 2) мы считали, что будет отдельный компонент, определяющий смыслы слов после синтаксического анализа входных данных. Этот компонент предназначался для выбора и / или сопоставления лексической информации из нескольких словарей для представления и расширения лексического значения каждого слова содержимого.Такой взгляд на устранение неоднозначности слов (WSD) контрастировал с зарождавшимся тогда интересом к WSD в академическом сообществе, которое формулировало задачу WSD как выбор одного чувства из фиксированного набора значений слов в качестве правильного. Наше основное возражение против этой формулировки состоит в том, что любой фиксированный перечень обязательно не будет достаточным в качестве основы для грамматики широкого охвата (см. Dolan, Vanderwende and Richardson, 2000). По тем же причинам мы решили отказаться от использования Word Senses и в NLPwin.Сегодня эта область добилась больших успехов в изучении более гибкого понятия лексического значения с появлением векторного пространства, которое было бы многообещающим для объединения с выводом этого синтаксического анализатора.
Хотя мы не рассматривали устранение неоднозначности в словах как отдельную задачу, мы разработали наш синтаксический анализатор и последующие компоненты так, чтобы использовать все более обширную лексическую информацию. Грамматика эскиза опирается на рамки подкатегории и другие синтаксико-семантические коды, доступные из двух словарей: Longman Dictionary of Contemporary English (LDOCE) и American Heritage Dictionary, 3 rd edition, права на которые Microsoft приобрела в цифровом виде.LDOCE, в частности, предоставляет богатую лексическую информацию, которая облегчает построение логической формы [3]. Такие коды, какими бы богатыми они ни были, не поддерживают полную семантическую обработку, которая необходима, например, при определении правильного присоединения предложных фраз или номинальной со-ссылки. Возник вопрос: можно ли получить такие семантические знания автоматически, чтобы поддерживать синтаксический анализатор с широким охватом?
В начале и середине 90-х был значительный интерес к словарям для майнинга и другим справочным материалам для семантической информации в широком смысле.По этой причине мы предполагали, что там, где лексической информации было недостаточно для поддержки решений, которые необходимо было принять в компоненте Портрет, мы могли бы получить такую информацию в машиночитаемых справочниках.
В то время было доступно несколько анализаторов с широким охватом, поэтому основной упор делался на разработку строковых шаблонов (регулярных выражений), которые можно было бы использовать для идентификации конкретных типов семантической информации; Херст (1992) описывает использование таких паттернов для приобретения Гипернимия (это — термины).Alshawi (1989) анализирует словарные определения, используя грамматику, специально разработанную для этого словаря («Longmanese»). Мы столкнулись с двумя проблемами при использовании этого подхода: во-первых, по мере того, как возрастает потребность в большем вспоминании, написание и уточнение строковых шаблонов становится все более и более сложным, в пределе, приближаясь к сложности написания полной грамматики и, таким образом, далеко отклоняясь от простой строки. паттернов, с которых вы начали, и, во-вторых, при извлечении семантических отношений за пределами Hypernymy мы обнаружили, что строковых паттернов недостаточно (см. Montemagni and Vanderwende 1992).
Вместо этого мы предложили анализировать текст словаря с использованием уже разработанных лингвистических компонентов, эскиза, портрета и логической формы, обеспечивая доступ к надежному синтаксическому анализу, чтобы ускорить получение знаний семантической информации, необходимой для улучшения портрета. Этот бутстреппинг возможен, потому что некоторые лингвистические выражения недвусмысленны, и поэтому на каждой итерации мы можем извлекать из однозначного текста, чтобы улучшить анализ неоднозначного текста (см. Vanderwende 1995).
По мере того, как каждое определение в словаре и онлайн-энциклопедии обрабатывалось, а семантическая информация сохранялась для доступа к Portrait, картинка возникала из соединения всех фрагментов графа. Если рассматривать их как базу данных, а не как справочную таблицу (как люди используют словари), фрагменты графа соединяются и возникают интересные пути / выводы. Чтобы еще больше обогатить данные, мы предприняли шаг к просмотру каждого фрагмента графа с точки зрения каждого узла содержимого.Представьте, что вы смотрите на граф как на мобильный телефон и берете его за каждый из объектов по очереди — узлы под объектом остаются такими же, но узлы над этим объектом становятся инвертированными (показано на рисунке 6). Например, для определения слон :: животное с бивнями из слоновой кости »MindNet хранит не только фрагмент графика« ЧАСТЬ слона (бивень MATR из слоновой кости) », но также« ЧАСТЬ бивня слона »и« MATR-OF из слоновой кости ». бивень »[4].
Рисунок 6: Логическая форма и ее инверсии.
Мы назвали этот набор пересекающихся графов MindNet.Рисунок 7 отражает картину, которую мы видели для слова «птица» при просмотре всех фрагментов информации, которые были автоматически получены из словарного текста:
Рис. 7. Фрагмент NLPwin MindNet, сосредоточенный на слове «птица»
Как человеку, использующему только словарь, было бы очень сложно составить список всех различных типов птиц, всех частей птицы, всех мест, где птица может быть найдена, или типов действий. что может сделать птица. Но путем преобразования словаря в базу данных и инвертирования всех семантических отношений, как показано на рисунке 6, MindNet содержит обширную семантическую информацию для любого понятия, встречающегося в тексте, особенно.потому что он создается автоматическими методами с использованием грамматики с широким охватом, грамматики, которая анализирует фрагменты, а также анализирует полный грамматический ввод.
Мы вычислили показатель сходства для MindNet, используя тезаурус Роджера в качестве аннотированных обучающих данных. Получив пару слов от Roget, мы вычислили все пути в MindNet между этими синонимами, а затем наблюдали, как часто встречаются паттерны путей (паттерны типов отношений с конкретными концепциями, связывающими эти типы отношений, и без них).Таким образом, мы узнаем, что если X и Y соединены с использованием шаблона пути: ( X — Hypernym — z — HypernymOf Y ) или ( X — HasObject — z — ObjectOf — Y ) , что X и Y считаются похожими с большим весом. Затем мы можем запросить произвольные пары слов на предмет их сходства, обнаружив, что «золото» и «цинк» похожи, а «золото» и «велосипед» — нет.
Априори нет причин, по которым MindNet нельзя создать из текста, отличного от текста словаря или энциклопедии.Действительно, если бы MindNet разрабатывался сегодня, мы бы стремились автоматически получать семантическую информацию из Интернета. Заметной инженерной проблемой является время обработки, хотя доступность массово-параллельных веб-сервисов в значительной степени смягчает эту проблему. Другая важная задача — установить достоверность исходного материала (часть успеха IBM Watson в игре Jeopardy можно отнести к тщательному отбору источников информации). Что должно произойти с (очевидными) противоречиями даже в том случае, если источники одинаково надежны? Веса, вычисленные для определенных частей графа знаний, можно использовать для балансировки частоты встречаемости этой информации, но сам источник также следует учитывать в схеме весов.Более того, MindNet — это не просто база данных троек; мы сохраняем контекст, из которого были извлечены семантические отношения, и поэтому теоретически мы могли бы разрешить очевидные противоречия, принимая во внимание контекст. Мы не столкнулись с этими проблемами, поскольку MindNet был рассчитан только из источников, которые категорически верны (словари и энциклопедии), но эти проблемы следует решать в будущем с получением знаний из Интернета.
Первоначальная цель, как показано на рисунке 2, состояла в том, чтобы сократить пересказы до канонического представления в модуле, который мы предварительно назвали «Концепции», хотя «Определение концепций» было бы более наглядным.Как и в случае с устранением неоднозначности слов, мы отказались от этого модуля, поскольку были недовольны лежащим в основе предположением, что одно представление концепции или сложного события будет преобладать над другими, в то время как на самом деле оба выражения эквивалентны; эквивалентность должна быть плавной и позволять варьировать в зависимости от потребности приложения. Здесь мы снова считаем, что текущее исследование, целью которого является представление фрагментов синтаксического анализа в векторном пространстве, является многообещающим подходом, при этом подчеркивая важность учета синтаксического анализа и структуры логической формы.
Наконец, несколько слов о грамматике генерации (показанной справа от радуги на рисунке 1). В NLPwin мы разработали два типа грамматик генерации: компоненты генерации на основе правил (в том числе те, которые поставлялись с Microsoft Word, например, для перезаписи пассивного в активный) и Amalgam, набор модулей генерации с машинным обучением. Оба типа грамматик генерации использовались в производстве для машинного перевода.
Вкратце…
Мы описали некоторые аспекты проекта NLPwin в Microsoft Research [5].Компоненты лексической и синтаксической обработки предназначены для широкого охвата и устойчивости к грамматическим ошибкам, что позволяет создавать синтаксические анализы для фрагментированных, неграмматических, а также грамматических входов. Эти компоненты представляют собой в основном грамматики, основанные на правилах, использующие богатые лексические и семантические ресурсы, полученные из онлайн-словарей. Выходные данные компонента синтаксического анализа, древовидного анализа, преобразуются в графическое представление, называемое логической формой. Цель логической формы — вычислить структуру предиката-аргумента для каждого предложения и нормализовать различные синтаксические реализации того, что можно считать одним и тем же «значением».При этом расстояние между концептами отражает семантическое расстояние, а не линейное расстояние в поверхностной реализации, сближая связанные концепции, чем они могут появиться на поверхности. MindNet — это автоматическое построение базы данных связанных логических форм. Когда справочные ресурсы являются исходным текстом для MindNet, MindNet можно рассматривать как традиционный метод и объект получения знаний, но когда MindNet создается путем обработки произвольного ввода текста, MindNet представляет собой глобальное представление всех логических форм этого текста, что позволяет просмотр понятий и их семантических связей в этом тексте.Фактически, MindNet считался наиболее привлекательным средством для просмотра и изучения конкретных отношений, извлеченных из текстовой коллекции.
[1] см. Дженсен, Карен. 1987. Бинарные правила и небинарные деревья: Разрушение концепции фразовой структуры. В Математика языка , изд. А. Манастер-Рамер, 65-86. Амстердам: John Benjamins Pub.Co.
[2] Фактически, система NLPwin (пока) не решала эту проблему до сегодняшнего дня.
[3] Коды ящиков LDOCE, например, предоставляют информацию об ограничениях типов и аргументах для глаголов.В LDOCE «убедить» помечено как ObjC, что указывает на то, что «убедить» имеет объектный контроль (т.е. что объект «убедить» понимается как подлежащее дополнения глагола). Таким образом, можно построить логическую форму с «Джон» в качестве субъекта «перейти в библиотеку» из входного предложения: «Я убедил Джона пойти в библиотеку», а для входного предложения «Я обещал Джону иди в библиотеку », логическая форма строится с« я »в качестве предмета« перейти в библиотеку ».
[4] Алгоритм, конечно, также идентифицирует отношение «слон ГИПЕРНИМ животное», но при обработке словаря информация, извлеченная из различий определения (спецификации гиперонима), верна для определяемого слова, а не верно для гипернима, и поэтому мы извлекаем не то, что «у животных есть бивни», а скорее то, что «у слонов есть бивни».
[5] На момент написания этой статьи (2014 г.) NLPwin считался зрелой системой с ограниченным развитием компонентов генерации и логической формы.
Расширить все | Свернуть все
Среда разработки
Морфология
Синтаксис
- Дженсен, Карен, Джордж Э.Хайдорн и Стивен Д. Ричардсон (ред.). 1993. Обработка естественного языка: подход PLNLP. Kluwer : Бостон.
- ПРИМЕЧАНИЕ. Хотя приведенное выше не является справочным материалом для работы, проделанной в Microsoft, подход PLNLP дает хороший обзор мотивации и структуры синтаксической системы, а также ряда других ключевых компонентов полной системы NLP.
- Стивен Д. Ричардсон. 1994. Загрузка статистической обработки в синтаксический анализатор естественного языка на основе правил.В материалах семинара The Balancing Act: сочетание символического и статистического подходов к языку, спонсируемого ACL.
- Майкл Гамон и Том Ройтер. 1997. Анализ разделимых префиксных глаголов немецкого языка в системе обработки естественного языка Microsoft. Технический отчет Microsoft Research, MSR-TR-97-15, сентябрь 1997 г.
- Майкл Гамон, Кармен Лозано, Джесси Пинкхэм и Том Ройтер. 1997. Практический опыт совместного использования грамматики в многоязычном НЛП, Технический отчет Microsoft Research, No.MSR-TR-97-16
- Майкл Гамон, Кармен Лозано, Джесси Пинкхэм и Том Ройтер. 1997. От исследований к коммерческим приложениям: как заставить НЛП работать на практике. В материалах семинара ACL «От исследования к коммерческим приложениям: как заставить НЛП работать на практике»
- Майкл Гамон, Кармен Лозано, Джесси Пинкхэм и Том Ройтер. 1997. Практический опыт использования грамматики в многоязычном НЛП, №1. MSR-TR-97-16
- Майкл Гамон, Кармен Лозано, Джесси Пинкхэм и Том Ройтер.1997. От исследований к коммерческим приложениям: как заставить НЛП работать на практике. В материалах семинара ACL «От исследования к коммерческим приложениям: как заставить НЛП работать на практике»
- Такако Айкава, Крис Квирк и Ли Шварц. 2003. Изучение предлогной привязанности из выровненных по предложению двуязычных корпусов, Американская ассоциация машинного перевода.
- Ли Шварц; Такако Айкава. 2004. Многоязычный корпусный подход к разрешению английского языка. В трудах LREC.
Логическая форма
- Люси Вандервенде. 1994. Алгоритм автоматической интерпретации последовательностей существительных. В материалах 15-й Международной конференции по компьютерной лингвистике, том 2.
- Люси Вандервенде. 1996. Анализ последовательностей существительных с использованием семантической информации, извлеченной из он-лайн словарей, докторская диссертация, Джорджтаунский университет, технический отчет Microsoft Research, нет. MSR-TR-95-57, октябрь 1996 г.
- Ричард Кэмпбелл и Хисами Судзуки.2002. Нейтральный к языку синтаксис: обзор . Технический отчет Microsoft Research, MSR-TR-2002-76
- Ричард Кэмпбелл. 2002. Вычисление области видимости модификатора в NP языково-нейтральным методом. В материалах 19 -й Международной конференции по компьютерной лингвистике , COLING-2002.
- Ричард Кэмпбелл и Хисами Судзуки. 2002. Языко-нейтральное представление синтаксической структуры. В материалах Первого международного семинара по масштабируемому пониманию естественного языка (SCANALU 2002), Гейдельберг, Германия
- Ричард Кэмпбелл, Такако Айкава, Зиксин Цзян, Кармен Лозано, Майте Мелеро и Анди Ву.2002. Независимое от языка представление временной информации. В LREC 2002 Workshop Proceedings: Annotation Standards for Temporal Information in Natural Language. 13-21.
- Ричард Кэмпбелл и Эрик Ринггер. 2004. Преобразование аннотаций банка деревьев в нейтральный к языку синтаксис, в трудах LREC.
- Ричард Кэмпбелл. 2004. Использование лингвистических принципов для восстановления пустых категорий. В материалах ACL.
Устранение неоднозначности
- Уильям Б.Долан. 1994. Неоднозначность смысла слов: объединение связанных смыслов в кластеры. Труды 15-й Международной конференции по компьютерной лингвистике, COLING’94, 5-9 августа 1994 г., Киото, Япония, 712-716.
- Уильям Долан, Люси Вандервенде и Стивен Д. Ричардсон. 2000. Многозначность в системе обработки естественного языка с широким охватом. В Многозначность: теоретические и вычислительные подходы . Ред. Яэль Рэвин и Клаудия Ликок. Oxford University Press, июль 2000 г.
Дискурс
MindNet — Автоматическое построение базы знаний
- Симонетта Монтеманьи и Люси Вандервенде.1992. Структурные шаблоны против строковых шаблонов для извлечения семантической информации из словарей, в трудах четырнадцатой Международной конференции по компьютерной лингвистике, COLING-1992
- Уильям Долан, Стивен Д. Ричардсон и Люси Вандервенде. 1993. Автоматическое извлечение структурированных баз знаний из он-лайн каталогов, нет. MSR-TR-93-07, май 1993 г.
- Уильям Долан, Стивен Д. Ричардсон и Люси Вандервенде. 1993. Объединение основанных на словарях и основанных на примерах методов для анализа естественного языка, нет.MSR-TR-93-08, июнь 1993 г.
- Люси Вандервенде. 1995. Неопределенность в получении лексической информации. В симпозиуме AAAI по представлению и приобретению лексических знаний : TR SS-95-01, AAAI, 1995
- Стивен Д. Ричардсон, Уильям Б. Долан и Люси Вандервенде. 1998. MindNet: получение и структурирование семантической информации из текста. В материалах дела COLING-ACL 1998
- Люси Вандервенде, Гэри Качмарчик, Хисами Судзуки и Арул Менезес. 2005. MindNet: автоматически создаваемый лексический ресурс.In Proceedings of the HLT / EMNLP Interactive Demonstrations, October 2005
Поколение
- Саймон Корстон-Оливер, Майкл Гамон, Эрик Ринггер и Роберт Мур. 2002. Обзор Amalgam: модуль поколения с машинным обучением. В материалах ACL
- Майкл Гамон, Эрик Ринггер и Саймон Корстон-Оливер. 2002. Амальгама: модуль поколения с машинным обучением. Технический отчет Microsoft Research No. MSR-TR-2002-57, июнь 2002 г.
- Чжу Чжан, Майкл Гамон, Саймон Корстон-Оливер, Эрик Ринггер.2002. Вставка знаков препинания внутри предложения в генерации естественного языка. Технический отчет Microsoft Research No. MSR-TR-2002-58
Немецкий
Французский
- Мартина Сметс, Майкл Гамон, Саймон Корстон-Оливер и Эрик Ринггер. 2003. Адаптация системы реализации предложений с машинным обучением к французскому языку, в материалах европейской главы ACL .
- Мартина Сметс, Майкл Гамон, Саймон Корстон-Оливер и Эрик Ринггер. 2003. French Amalgam: система реализации предложений с машинным обучением, Association pour le Traitement Automatique des Langues, TALN 2003
Испанский
китайский
Японский
Проверка грамматики
- Джордж Э.Хайдорн. 2000. Интеллектуальная помощь при письме. В A Справочник Обработки естественного языка : Методы и приложения для обработки языка как текста. Марсель Деккер, Нью-Йорк. С. 181-207.
Машинный перевод
- Майкл Гамон, Хисами Судзуки и Саймон Корстон-Оливер. 2001. Использование машинного обучения для внутренней оценки переданных языковых представлений, Европейская ассоциация машинного перевода, январь 2001 г.
- Саймон Корстон-Оливер, Майкл Гамон и Крис Брокетт.2001. Подход машинного обучения к автоматической оценке машинного перевода, Ассоциация компьютерной лингвистики,
- Арул Менезес и Стивен Д. Ричардсон. 2001. Алгоритм выравнивания «лучший первый» для автоматического извлечения отображений переноса из двуязычных корпусов, Association for Computational Linguistics
- Уильям Долан, Стивен Д. Ричардсон, Арул Менезес и Моника Корстон-Оливер. 2001. Преодоление узких мест в настройке с использованием машинного перевода на основе примеров, Association for Computational Linguistics
- Стивен Д.Ричардсон, Уильям Б. Долан, Арул Менезес и Джесси Пинкхэм. 2001. Достижение коммерческого качества перевода с помощью методов, основанных на примерах. В материалах конференции MT Summit VIII, Сантьяго-де-Компостела, Испания. 293-298.
- Ричард Кэмпбелл, Кармен Лозано, Джесси Пинкхэм и Мартина Сметс. 2002. Машинный перевод как испытательная площадка для многоязычного анализа. In Proceedings of COLING 2002
- Джесси Пинкхэм и Мартина Сметс. 2002. Модульный МП с изученным двуязычным словарем: быстрое развертывание новой языковой пары.In Proceedings of COLING 2002
- Джесси Пинкхэм и Мартина Сметс. 2002. Машинный перевод без двуязычного словаря. В материалах 9-й конференции по теоретико-методологическим вопросам машинного перевода.
- Крис Брокетт, Такако Айкава, Энтони Ауэ, Арул Менезес, Крис Куирк и Хисами Судзуки. 2002. Англо-японский машинный перевод на основе примеров с использованием абстрактных семантических представлений, Труды семинара Coling 2002 по машинному переводу в Азии, COLING-2002
- Мартина Сметс, Джозеф Пентероудакис и Арул Менезес.2002. Перевод словесных идиом. В трудах международного семинара по вычислительным подходам к словосочетаниям, Colloc-02, Вена, Австрия
- Арул Менезес. 2002. Улучшенный контекстный перевод с использованием машинного обучения. На 5-й конференции Ассоциации машинного перевода в Северной и Южной Америке, AMTA 2002 г. Тибурон, Калифорния, США, 8–12 октября 2002 г. Proceedings, Springer, Verlag
- Мартина Сметс, Майкл Гамон, Джесси Пинкхэм, Том Ройтер и Мартина Петтанаро. 2003. Высококачественный машинный перевод с использованием компонента реализации предложений с машинным обучением.In Proceedings of the Association for Machine Translation in the Americas
- Саймон Корстон-Оливер и Майкл Гамон. 2003. Объединение деревьев решений и обучения на основе преобразований для исправления переданных языковых представлений. In Proceedings of the Association for Machine Translation in the Americas
- Энтони Ауэ, Арул Менезес, Роберт Мур, Крис Квирк и Эрик Ринггер. 2004. Статистический машинный перевод с использованием помеченных графов семантических зависимостей. В материалах 10-й Международной конференции по теоретическим и методологическим вопросам машинного перевода (TMI ‐ 2004).Балтимор, штат Мэриленд.
- Саймон Корстон-Оливер и Майкл Гамон. 2004. Нормализация немецкой и английской флективной морфологии для улучшения статистического выравнивания слов. In Proceedings of the Association for Machine Translation in the Americas
- Крис Куирк, Арул Менезес и Колин Черри. 2004. Перевод дерева зависимостей: синтаксически сформированный фразовый SMT, нет. MSR-TR-2004-113, ноябрь 2004 г.
- Эрик Ринггер, Майкл Гамон, Роберт С. Мур, Дэвид Рохас, Мартина Сметс и Саймон Корстон-Оливер.2004. Лингвистически обоснованные статистические модели составной структуры для упорядочивания в реализации предложения. В материалах 20 -й Международной конференции по компьютерной лингвистике .
- Дунхуэй Фэн, Яцзюань Лю, Мин Чжоу. 2004. Новый подход к согласованию англо-китайских именованных сущностей. В материалах ЕМНЛП-2004
- Яцзюань Лю и Мин Чжоу. 2004. Приобретение совместных переводов с использованием одноязычных корпусов. In Proceedings of the 42 nd Annual Meeting on Association for Computational Linguistics.
- Арул Менезес и Крис Куирк. 2005. Система перевода Treelet от Microsoft Research: оценка IWSLT. В материалах международного семинара по устному переводу, октябрь 2005 г.
- Крис Куирк, Арул Менезес и Колин Черри. 2005. Зависимый перевод Treelet: синтаксически сформированный фразовый SMT. В материалах ACL
- Арул Менезес и Крис Куирк. 2005. Перевод дерева зависимостей: конвергенция статистического и основанного на примерах машинного перевода.В материалах 10-го семинара по машинному переводу на высшем уровне по машинному переводу на основе примеров
- Майкл Гамон, Энтони Ауэ и Мартина Сметс. 2005. Оценка машинного перевода на уровне предложений без справочных переводов: помимо языкового моделирования. В трудах Европейской ассоциации машинного перевода.
- Крис Куирк и Саймон Корстон-Оливер. 2006. Влияние качества синтаксического анализа на синтаксически обоснованный статистический машинный перевод. В материалах ЕМНЛП 2006
- Сяодун Хэ, Арул Менезес, Крис Куирк, Энтони Ауэ, Саймон Корстон-Оливер, Цзяньфэн Гао и Патрик Нгуен.2006. Система перевода Treelet исследований Microsoft: оценка NIST MT 06, Национальный институт стандартов и технологий, март 2006 г.
- Крис Куирк и Арул Менезес. 2006. Зависимость Treelet Translation: Конвергенция статистического и основанного на примерах машинного перевода ?. В машинном переводе, т. 20, стр. 43–65, март 2006 г.
- Арул Менезес, Кристина Тутанова и Крис Куирк. 2006. Система перевода дерева исследований Microsoft: оценка NAACL 2006 Europarl. В WMT 2006
- Арул Менезес и Крис Куирк.2007. Использование шаблонов порядка зависимостей для повышения универсальности перевода. В материалах второго семинара по статистическому машинному переводу в ACL 2007
- Арул Менезес и Крис Куирк. 2008. Синтаксические модели для структурной вставки и удаления слов при переводе. В материалах ЕМНЛП 2008
Обобщение
- Кристина Тутанова, Крис Брокетт, Майкл Гамон, Джагадиш Джагарламунди, Хисами Судзуки и Люси Вандервенде. 2007. Система обобщения Pythy: исследования Microsoft на DUC 2007.В материалах дела DUC-20077
- Люси Вандервенде, Хисами Судзуки, Крис Брокетт и Ани Ненкова. 2007. За пределами SumBasic: сфокусированное на задачах обобщение с упрощением предложений и лексическим расширением. В «Обработка информации и управление», том 43, выпуск 6, страницы 1606-1618
- Эдуард Хови, Чин-Ю Лин и Лян Чжоу. 2005. Оценка DUC 2005 с использованием базовых элементов. В материалах семинара DUC-2005.
- Юрий Лесковец, Наташа Милич-Фрайлинг, Марко Гробельник.2005. Влияние лингвистического анализа на охват семантического графа и изучение отрывков из документов. В материалах Национальной конференции по искусственному интеллекту (AAAI), 2005.
- Саймон Х. Корстон-Оливер, Эрик Ринггер, Майкл Гамон и Ричард Кэмпбелл. 2004. Целенаправленное обобщение электронной почты. В материалах семинара ACL 2004 «Разветвляется обобщение текста», Барселона, Испания.
- Люси Вандервенде, Микеле Банко и Арул Менезес. 2004. Генерация событийно-ориентированных сводок.В Рабочих заметках конференции Document Understanding 2004
- Юрий Лесковец, Наташа Милич-Фрайлинг, Марко Гробельник. Извлечение сводных предложений на основе семантического графика документа. Технический отчет Microsoft Research MSR-TR-2005-07, 2005.
- Юрий Лесковец, Марко Гробельник и Наташа Милич-Фрайлинг. 2004. Изучение подструктур семантических графов документов для обобщения документов. В материалах семинара по анализу ссылок и обнаружению групп (LinkKDD), 2004 г.
- Саймон Корстон-Оливер.2001. Сжатие текста для отображения на очень маленьких экранах. В материалах семинара по автоматическому обобщению, NAACL 2001.
Оценка
Entailment
Построение базы знаний / Извлечение информации / Анализ текста
- Кумаран, Ранбер Макин, Виджай Паттисапу, Шайк Шариф, Гэри Качмарчик и Люси Вандервенде. 2006. Автоматическое извлечение синонимической информации. В Семинар «Онтологии в текстовых технологиях», Оснабрюк, Германия , декабрь 2006 г.
- Крис Квирк, Паллави Чоудхури, Майкл Гамон и Люси Вандервенде.Запись MSR-NLP в BioNLP Shared Task 2011. В материалах семинара BioNLP Shared Task 2011.
Исправление орфографии
Поиск информации
Интеллектуальные агенты
- Саймон Корстон-Оливер, Эрик Ринггер, Майкл Гамон и Ричард Кэмпбелл. 2004 г. Интеграция электронной почты и списков задач. В Первой конференции по электронной почте и защите от спама (CEAS), 2004 г., Труды
- Тим Пэк и Эрик Хорвиц. 1999. Неопределенность, полезность и недопонимание: теоретико-решающий взгляд на обоснование в диалоговых системах.В техническом отчете AAAI FS-99-03.
- Хуа Ли, Доу Шэнь, Бэнью Чжан, Чжэн Чен и Цян Ян. 2006. Добавление семантики в кластеризацию электронной почты. В материалах Шестой Международной конференции по интеллектуальному анализу данных (ICDM’06).
- Гохан Тур, Ануп Деорас и Дилек Хаккани-Тур. 2014. Обнаружение высказываний вне домена, адресованных виртуальному персональному помощнику. In Proceedings of Interspeech , ISCA — Международная ассоциация речевой коммуникации, сентябрь 2014 г.
Заявка на получение образования
- Ли Шварц, Такако Айкава и Мишель Пахуд.2004. Инструменты динамического изучения языка. Материалы симпозиума InSTIL / ICALL 2004 г., июнь 2004 г.
- Такако Айкава, Ли Шварц и Мишель Пахуд. 2005 .NLP Story Maker. В материалах конференции «Второй язык и технологии»: «Языковые технологии человека как вызов компьютерным наукам и лингвистике» 21–23 апреля 2005 г., Познань, Польша
Настроение
Идентификация авторства
- Английский язык и разработка ядра: Карен Дженсен, Джордж Хайдорн, Стивен Д.Ричардсон, Диана Петерсон, Люси Вандервенде, Джозеф Пентерудакис, Билл Долан, Дебора Кофлин, Ли Шварц, Саймон Корстон Оливер, Эрик Ринггер, Рич Кэмпбелл, Арул Менезес, Крис Квирк
- Французский : Мартина Петтенаро, Джесси Пинкхэм, Мартина Сметс
- Испанский : Мариса Хименес, Кармен Лозано, Маите Мелеро
- Немецкий : Майкл Гамон, Том Ройтер
- Японский : Такако Айкава, Крис Брокетт, Хисами Сузуки
- Китайский : Терренс Пэн, Анди Ву, Цзян Цзысинь
- Корейский : Джи Ын Ким, Конг Джу Ли
Николас Лурье | Semantic Scholar
ATOMIC: Атлас машинного здравого смысла для рассуждений «если-то»
Экспериментальные результаты демонстрируют, что многозадачные модели, включающие иерархическую структуру типов отношений «если-то», приводят к более точному выводу по сравнению с моделями, обученными изолированно, как измерено обоими автоматическая и человеческая оценка.ExpandИзвлечение научных фигур с помощью дистанционно контролируемых нейронных сетей
Эта статья предлагает высококачественные обучающие метки для задачи извлечения фигур в большом количестве научных документов без вмешательства человека и использует этот набор данных для обучения глубокой нейронной сети для конечной цели. -To end определение фигур, что дает модель, которую легче распространить на новые области по сравнению с предыдущей работой. РазвернитеUNICORN в RAINBOW: универсальная модель здравого смысла в новом многозадачном тесте
Новый тест для многозадачности RAINBOW предлагается для содействия исследованиям моделей здравого смысла, которые хорошо обобщаются для множества задач и наборов данных, и предлагается новая оценка, эквивалентная стоимости curve, которая дает новое представление о том, как выбор исходных наборов данных, предварительно обученных языковых моделей и методов передачи обучения влияет на производительность и эффективность данных.ExpandLearning from Task Descriptions
Эта работа представляет основу для разработки систем НЛП, которые решают новые задачи после прочтения их описаний, синтезируя предыдущую работу в этой области, и инстанцируют ее с новым набором данных на английском языке, ZEST, структурированным для ориентированной на задачи оценки по невидимым задачам. ExpandScruples: Корпус этических суждений сообщества по 32 000 анекдотов из реальной жизни
Эта работа знакомит с Scruples, первым крупномасштабным набором данных с 625 000 этических суждений на основе 32 000 анекдотов из реальной жизни, и представляет новый метод оценки лучших Возможная производительность на таких задачах с присущим им разнообразным распределением меток, а также исследуются функции правдоподобия, которые отделяют внутреннюю неопределенность от неопределенности модели.ExpandНаписание кода для исследования НЛП
Это руководство направлено на обмен передовыми методами написания кода для исследования НЛП с использованием опыта преподавателей в разработке недавно выпущенного инструментария AllenNLP, библиотеки на основе PyTorch для глубокого обучения NLPResearch. РазвернутьДействительно ли GPT-3 — будущее НЛП?
OpenAI, крупная исследовательская лаборатория искусственного интеллекта, базирующаяся в Сан-Франциско, недавно опубликовала документ, в котором представлена важная модернизация их хорошо зарекомендовавшей себя языковой модели GPT-3 (GPT означает «Генеративный предварительно обученный преобразователь»).Хотя GPT-3, безусловно, очень впечатляет, как он соотносится с другими языковыми моделями и каковы последствия для компаний, пытающихся практически применить НЛП к своим данным?
GPT-3 — это языковая модель , которая имеет особое значение в области обработки естественного языка (NLP). Языковая модель — это статистический инструмент для прогнозирования языка, не понимая его, путем определения вероятности того, с какой вероятностью слова следуют за другими словами — например, как часто за словом «дикий» следует «розы».Затем такой же анализ можно провести с предложениями «где растут дикие розы» или даже с целыми абзацами. Затем ему может быть предложено , например: « напиши мне текст о том, где растут дикие розы в стиле Metallica», и GPT-3 будет использовать статистические зависимости, которые он сохранил после обучения, чтобы придумать песню, которая, надеюсь, соответствует описание. Языковые модели работают, пытаясь найти закономерности в человеческом языке. Они часто используются для предсказания слов, произнесенных в аудиозаписи, следующего слова в предложении, того, какое электронное письмо является спамом, или того, как автозаполнить предложение, которое вы написали, так, как вы даже не задумывались.
GPT-3 является последним экземпляром изобилия из предварительно обученных языковых моделей , таких как Google BERT, Facebook RoBERTa и Microsoft Turing-NLG, что означает, что модели (в форме нейронных сетей) уже обучены на огромных общих наборах данных. , обычно без присмотра.
Но почему GPT-3 привлек столько внимания? В основном потому, что он такой большой. Его огромный размер дает модели возможность работать значительно лучше, чем существующие модели, но об этом позже.
Во-первых, немного статистики: самая большая версия модели GPT-3 содержит 175 миллиардов параметров, полученных в результате обучения сотням миллиардов слов или токенов . Эти токены собираются из общедоступных наборов данных, таких как Common Crawl (410 миллиардов токенов), WebTex2 (19 миллиардов токенов), Books1 и Books2 (67 миллиардов токенов) и Wikipedia («всего» 3 миллиарда токенов). Иногда легко забыть, что не так давно модель, обученная только в Википедии, считалась действительно большой.
Языковые модели — малоизученные, OpenAI
В распоряжении GPT-3 есть собственный суперкомпьютер для учебных целей, размещенный в облаке Microsoft Azure и состоящий из 285 тыс. Ядер ЦП и 10 тыс. Высокопроизводительных графических процессоров. Другими словами, если бы у вас был доступ только к одному V100 (самый продвинутый, коммерчески доступный графический процессор NVIDIA на сегодняшний день), вам потребовалось бы примерно 355 лет, а обучение GPT-3 могло бы стоить до 12 миллионов долларов… один раз.
Примеры тестов для NLP
GPT-3 отличается от других систем NLP не только своим размером, но и важным отличием.Модели, аналогичные GPT-3, обычно обучаются на большом корпусе текста, а затем настраиваются для выполнения конкретной задачи (например, машинный перевод) и только этой задачи. Использование предварительно обученных моделей и их тонкая настройка для решения конкретных задач стало популярной и успешной тенденцией в области НЛП. Этот метод помогает разработчикам сократить время разработки моделей и получить преимущества быстрее и с меньшими затратами.
GPT-3, напротив, идет еще дальше и не требует точной настройки; кажется, он способен выполнять целый ряд задач достаточно хорошо , от написания художественной литературы, стихов или музыки, программирования работающего кода, шуток, составления технических руководств до написания убедительных новостных статей.Twitter изобилует примерами всего, что может делать GPT-3, поэтому я не собираюсь повторять их здесь.
Отличный и действительно забавный (основанный на небольшом опросе в офисе Endila) пример написания GPT-3 можно найти здесь. Интересно видеть, что когда мы случайно читаем текст, сгенерированный GPT-3, он выглядит великолепно, но если присмотреться немного внимательнее, он довольно быстро становится довольно бессмысленным.
И это приводит к еще нескольким критическим оценкам:
«GPT-3 часто ведет себя как умный студент, который еще не прочитал, пытаясь обмануть свой путь на экзамене.Некоторые общеизвестные факты, полуправда и прямая ложь, соединенные воедино, на первый взгляд кажущееся гладким повествованием ».
Джулиан Тогелиус , доцент исследования А.И. в NYU
Не многие люди еще имели возможность поближе познакомиться с GPT-3, и в будущем будет написано гораздо больше о системах, подобных GPT-3, но я включил действительно отличный, практичный -земное описание архитектуры GPT-3 и подробное видео на YouTube с анализом статьи GPT-3 в ссылках.Видео длится более часа, но оно того стоит, если вы все же хотите приложить все усилия, чтобы понять, о чем идет речь, после прочтения этой статьи.
В оставшейся части этой статьи я хотел бы предложить некоторые из моих собственных наблюдений.
. . . GPT-3 не является новой технологиейGPT-3, как и его предшественник GPT-2, использует умную комбинацию двух существующих технологий. Первая техника называется «Трансформатор». Transformers были введены Google в контексте машинного перевода для обработки последовательных данных, таких как естественный язык.Но в отличие от некоторых более старых, устоявшихся моделей, таких как GRU или LSTM, они легко допускают массовое распараллеливание. Распараллеливание в этом контексте означает распределение рабочей нагрузки по большому количеству процессоров ЦП или ГП, что сокращает время выполнения определенной задачи (почти) линейно с количеством доступных процессоров.
Второй метод называется самообучение и позволяет моделям ИИ изучать язык, исследуя миллиарды страниц общедоступных документов, таких как статьи Википедии, самоизданные книги, инструкции по эксплуатации, онлайн-курсы, фрагменты программ и т. Д. Рецепты болгарского пудинга Ориз и др.Опять же, это не уникальное свойство GPT-3. Другие языковые модели, такие как BERT (Google), XLNet (Google, CMU), RoBERTa (Facebook) и предыдущие версии GPT, используют по существу ту же архитектуру.
Комбинация этих двух методов позволяет масштабировать GPT-3. Можно использовать практически неограниченную компьютерную инфраструктуру, если за нее можно платить, и нет необходимости в контролируемом (человеческом) обучении, что было бы довольно непрактично для таких размеров обучающих данных.
GPT-3 расширен многими способами, но имеет свои ограниченияПервое ограничение — это то, что он затруднен ограниченным контекстным окном . Он не может «видеть» за пределами этого окна, которое составляет примерно 500–1000 слов. Это приводит к тому, что у него довольно короткий «объем внимания», что означает, что он не может писать большие отрывки связного текста. Вскоре он безвозвратно забывает начало своего написания или контекст, в котором он был написан. Это не имеет значения для задач, в которых формат повторяется или ограничен по размеру (например, добавление в ваш канал Twitter), но это определенно ограничит его производительность в другие направления (написание следующей «Войны и мира»).Частично причиной этого ограничения является то, как GPT-3 использует метод, называемый кодированием пар байтов (BPE), из соображений эффективности.
Второе ограничение, которое, похоже, разделяют все модели авторегрессионного языка, обученные с использованием вероятности потери вероятности , заключается в том, что при генерации завершений произвольной формы они имеют тенденцию в конечном итоге впадать в повторяющиеся петли тарабарщины. Модель может постепенно уйти от темы, отклониться от той цели, которая была предназначена для написания, и стать неспособной придумать разумные продолжения.Такое поведение наблюдалось много раз, но, насколько мне известно, не было полностью объяснено. Его непредсказуемость может быть забавной при игре с моделью, но может стать опасной, когда на карту поставлено большее, например, если она использовалась для генерации рабочих заданий или документации HSE.
Эти два недостатка напоминают нам о том, что улучшение производительности глубокого обучения ИИ сегодня связано с увеличением грубой мощности, а не с человеческим умом или пониманием. Приятно видеть замечательные результаты GPT-3 в различных задачах, просто дав ему несколько примеров того, что нужно делать, но иногда легко забыть, что он никаким человеческим образом не понимает, что делает. .
Обучение в Интернете не всегда решает проблему лучшеЗвучит очевидно. Если мы обучим модель НЛП каждому тексту, когда-либо созданному человечеством, то результаты, которых мы достигаем, будут тем лучше, чем больше станет модель. Однако на практике некоторые или большая часть данных, которые нам нужны для конкретного проекта, не являются общедоступными или не в формате, подходящем для передачи на компьютеры (в частности, модели глубокого обучения). Подходящие данные для обучения могут быть закрытыми, конфиденциальными или просто недоступными.Обработка данных различного рода обычно занимает 80% времени, затрачиваемого в типичном проекте ИИ, и, на мой взгляд, этот процент существенно не снизится в ближайшем будущем для многих реальных проектов.
GPT-3 достаточно хорошо справляется со многими задачами, но для большинства реальных проектов нам нужен наилучший результат, которого мы можем достичь. Это по-прежнему означает борьбу с данными, тщательное обдумывание того, какие алгоритмы и модели использовать, и, к сожалению, значительные методы проб и ошибок.
.. .Что все это значит?
Стоимость ресурсов, необходимых для использования GPT-3, делает его недоступным даже для компании приличного размера и, конечно же, для одного исследователя в области науки о данных. Open.ai начнет взимать плату за использование GPT-3 и инфраструктуры, на которой он работает. Это вполне понятно, учитывая необходимое оборудование и стоимость работы тысяч графических процессоров и процессоров.
AIaaS (AI как услуга) выглядит как следующий логический шаг, предоставляющий те же преимущества и недостатки, что и хорошо зарекомендовавшие себя модели SaaS, включая доступ к расширенной инфраструктуре, простую масштабируемость и высокую надежность.Однако, как известно, модели глубокого обучения непрозрачны, и покупка AIaaS — это все равно что поместить черный ящик в другой черный ящик, что дает меньше возможностей для понимания и снижения рисков развертывания. Таким образом, по-прежнему важно иметь возможность поставить человека в ловушку каждый раз, когда модель ИИ принимает важное решение.
Это имеет еще больше смысла при использовании API OpenAI, который имеет форму свободного ввода текста. Хотя он кажется очень интуитивным, и вам не нужно быть программистом, чтобы использовать его, он также добавляет еще один уровень нечеткости, потенциально вводя непонимание того, что от него ожидается.
Фундаментальное предположение компьютерной индустрии состоит в том, что обработка чисел все время удешевляется. Закон Мура, метроном компьютерной индустрии, предсказывает, что количество компонентов, которые могут быть помещены на микрочип заданного размера — и, таким образом, в общих чертах, количество вычислительной мощности, доступной при данной стоимости — удваивается каждые два года, что значительно снижение стоимости вычислений с течением времени. Но это не всегда так. Раздутая сложность означает, что затраты на передовые технологии НЛП резко возрастают, как мы ясно видим на примере GPT-3.Рост размера языковых моделей явно опережает рост памяти графического процессора, самого дефицитного и дорогостоящего ресурса, который ему нужен, поэтому маловероятно, что в следующем году мы увидим модель GPT-4, которая будет на пару порядков меньше. по величине больше, чем GPT-3.
Необходимо серьезно задуматься над коммерческой реальностью стоимости и технической реальностью того, как построить систему, которая все еще легко масштабируется, когда она больше не смущающе параллельна .
Еще хотелось бы коснуться того, как измеряется прогресс в развитии машинного обучения.Состояние дел (SOTA) обычно оценивается путем выполнения ряда тестов (измерение одного или небольшого набора показателей производительности на заранее описанном наборе данных). Некоторые примеры и производительность GPT-3 см. В таблице ниже.
Примеры тестов для NLP
Хотя это объективный способ сравнения моделей, он может плохо измерить производительность модели, если метрика недостаточно покрывает задачу, для которой модель будет использоваться на практике. Это также стимулирует создание моделей, которые действительно хорошо работают на определенном тесте, но не на практических примерах использования.
В связи с этим становится почти неизбежным, что модели, принимающие массивные наборы обучающих данных, такие как GPT-3, обучаются на некоторых тестах, используемых для оценки. Это похоже на то, как ученику дают ответы перед экзаменом. В свою защиту авторы статей GPT-3 признают это, но пока не ясно, как этой проблемы можно избежать.
И последнее, но не менее важное и даже более важное: статистическое сопоставление слов не заменяет последовательного понимания мира.GPT-3 генерирует грамматически правильный текст, который, тем не менее, не связан с реальностью, утверждая, например, что «требуется две радуги, чтобы прыгнуть с Гавайев на 17». У него нет встроенной внутренней модели мира — или какого-либо другого мира — и поэтому он не может выполнять те рассуждения, которые требуются для такой модели, то, что люди признали бы здравым смыслом.
Это означает, что принятие критических решений только в зависимости от модели НЛП (или любой другой модели глубокого обучения) может привести к неожиданным и непредсказуемым результатам.В компьютерном программировании и инженерии в целом процесс планирования и изящного решения пограничных ситуаций обычно является важной задачей для (программного) инженера. Это не менее важно при использовании моделей машинного обучения для решения важных реальных задач. Проблема в том, что в нелинейной системе, где модели машинного обучения особенно сильны, непросто судить, как вообще выглядит граничный случай.
Итак, мой совет по-прежнему заключался бы в том, чтобы поместить экспертов в предметной области, специалистов по обработке данных и инженеров по программному обеспечению в одну (виртуальную) комнату и убедиться, что у вас есть ограждения, чтобы ваш ИИ оставался частью более широкой системы, которую вы понимаете и можете контроль.Или, как гласит мудрая русская пословица: Доверяй, но проверяй.
Эта статья была (еще) написана человеком.
. . .Ссылки
Philosophers On GPT-3, Dailynous, https://dailynous.com/2020/07/30/philosophers-gpt-3/
Языковые модели для нескольких учащихся, https://arxiv.org/pdf/2005.14165.pdf
Новый генератор языков OpenAI GPT-3 потрясающе хорош — и совершенно бессмысленен, MIT Technology Review, https: // www.technologyreview.com/2020/07/20/1005454/openai-machine-learning-language-generator-gpt-3-nlp/
RoBERTa: надежно оптимизированный подход к предварительному обучению BERT, Facebook, https://arxiv.org /abs/1907.11692
Внимание — все, что вам нужно, https://arxiv.org/abs/1706.03762
GPT-3 Creative fiction, https://www.gwern.net/GPT-3#why -deep-learning-will-never-true-x
Критический анализ показателей, используемых для измерения прогресса в области искусственного интеллекта, К.