Особенности речи при расстройствах аутистического спектра — Аутизм и нарушения развития
Аппе Ф. Введение в психологическую теорию аутизма. М.: Теревинф, 2006.
Башина В.М., Симашкова Н.В. К особенностям коррекции речевых расстройств у больных с синдромом детского аутизма // Исцеление: Альманах. М., 1993. Вып. 1. С. 154—160.
Гаврилушкина О.П., Малова А.А., Панкратова М.В. Проблемы социальной и коммуникативной компетентности дошкольников и младших школьников с трудностями в общении [Электронный ресурс] // Современная зарубежная психология. 2012. Т. 1. № 2. С. 5—16. URL: https://psyjournals.ru/jmfp/2012/n2/52248.shtml (дата обращения: 07.11.2016)
Манелис Н.Г. Ранний детский аутизм: психологические и нейропсихологические механизмы // Школа здоровья.1999. № 2. С. 6—22.
Baranek G. T., Watson L.R., Boyd B.A., Poe M.D., David
F.J., McGuire L.
T., Watson L.R., Boyd B.A., Poe M.D., David
F.J., McGuire L.
Charman T., Drew A., Baird C., Baird G. Measuring early language development in preschool children with autism spectrum disorder using the MacArthur Communicative Development Inventory (Infant Form) // J Child Lang. 2003. Feb. 30 (1):213—36.
De Giacomo A., Portoghese C., Martinelli D., Fanizza I., L’abate L., Margari L. Imitation and communication skills development in children with pervasive developmental disorders // Neuropsychiatr Dis Treat. 2009. 5:355—62.
DePape A.R., Chen A., Hall G.B., Trainor L.J. Use
of prosody and information structure in high functioning adults with Autism in
relation to language ability // Front.
DePape A.M., Hall G.B., Tillmann B., Trainor L.J. Auditory processing in high-functioning adolescents with Autism Spectrum Disorder // PLoS One. 2012; 7 (9):e44084.
Dobbinson S., Perkins M., Boucher J. The interactional significance of formulas in autistic language // Clin Linguist Phon. 2003 Jun-Aug.; 17 (4—5):299—307.
Fombonne E. Epidemiology of pervasive developmental disorders // Pediatr Res. 2009.
Gomes E., Pedroso F.S., Wagner M.B. Auditory hypersensitivity in the autistic spectrum disorder // Pro Fono. 2008 Oct—Dec. 20 (4):279—84.
Johnson C.P., Myers S.M. Identification and Evaluation of Children With Autism Spectrum Disorders // Pediatrics Vol. 120. No. 5 November 1. 2007. pp. 1183—1215.
Lee A. , Hobson R.P., Chiat S. I, you, me, and
autism: an experimental study // J Autism Dev Disord. 1994 Apr. 24
(2):155—76.
, Hobson R.P., Chiat S. I, you, me, and
autism: an experimental study // J Autism Dev Disord. 1994 Apr. 24
(2):155—76.
McCann J., Peppe S. Prosody in autism spectrum disorders: a critical review // Int J Lang Commun Disord. 2003 Oct—Dec.; 38(4):325—50
McGregor K.K., Berns A.J., Owen A.J., Michels S.A., Duff D., Bahnsen A.J., Lloyd M. Associations Between Syntax and the Lexicon Among Children With or Without ASD and Language Impairment // J Autism Dev Disord. 2012 January ; 42(1): 35—47
McLaughlin M. Speech and Language Delay in Children // Am Fam Physician. 2011;83(10):1183—1188
Newschaffer C.J., Croen L.A., Daniels J. et al. The epidemiology of autism spectrum disorders // Annu Rev Public Health 2009 28: 235—58.
Ozonoff S., Heung K., Byrd R. , Hansen R.,
Hertz-Picciotto I. The Onset of Autism: Patterns of Symptom Emergence in
the First Years of Life // Autism Res. 2008 December ; 1(6): 320—328
, Hansen R.,
Hertz-Picciotto I. The Onset of Autism: Patterns of Symptom Emergence in
the First Years of Life // Autism Res. 2008 December ; 1(6): 320—328
Paul R., Augustyn A., Klin A., Volkmar F.R. Perception and Production of Prosody by Speakers with Autism Spectrum Disorders // Journal of Autism and Developmental Disorders, Vol. 35, No. 2, April 2005
Ricard M., Girouard C.P., Gouin-Decarie T. Personal pronouns and perspective taking in toddlers // Journal of Child Language, 1999, 26, 681—697
Saad A.G., Goldfeld M. Echolalia in the language development of autistic individuals: a bibliographical review // Pro Fono. 2009 Jul—Sep;21(3):255—60
Schoen E., Paul R., Chawarska K. Phonology and Vocal Behavior in Toddlers with Autism Spectrum Disorders // Autism Res. 2011 June ; 4(3): 177—188
Volden J. , Lord C. Neologisms and idiosyncratic
language in autistic speakers // J Autism Dev Disord. 1991
Jun;21(2):109—30
, Lord C. Neologisms and idiosyncratic
language in autistic speakers // J Autism Dev Disord. 1991
Jun;21(2):109—30
Weismer S.E., Gernsbacher M.A., Stronach S., Karasinski C., Eernisse E.R., Venker C.E., Sindberg H. Lexical and Grammatical Skills in Toddlers on the Autism Spectrum Compared to Late Talking Toddlers // J Autism Dev Disord. 2011 August ; 41(8): 1065—1075
ОСОБЕННОСТИ РЕЧИ СТУДЕНТОВ (ПО МАТЕРИАЛАМ РЕЧЕВОГО АВТОПОРТРЕТА)
- Ольга Сергеевна Сальникова
- ФГБОУ ВО «Череповецкий государственный университет»
DOI: https://doi.org/10.35634/2412-9534-2021-31-3-508-513
Ключевые слова: речевая личность, речь студента, речевой автопортрет студента, soft skills, коммуникативные навыки
Аннотация
Вопрос формирования soft skills (в частности, коммуникативных навыков) у студентов высшего учебного заведения на сегодняшний день является актуальным.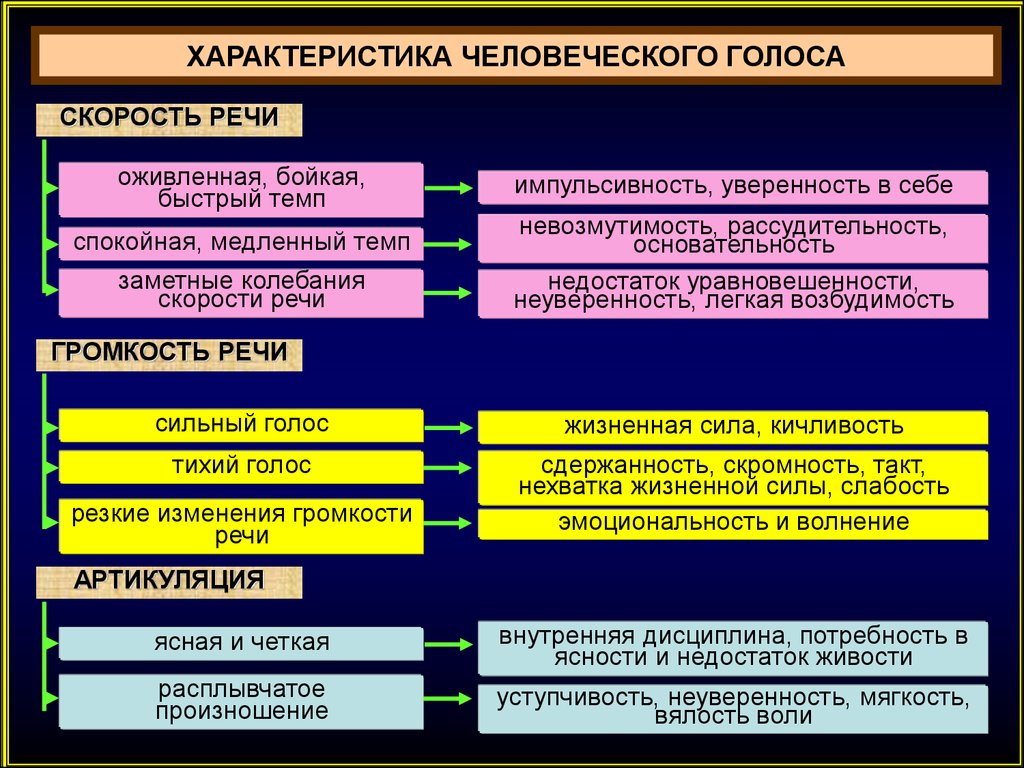 В статье рассматриваются особенности устной и письменной речи студентов как речевых личностей; представлено соотношение понятий «Речевой портрет» и «Речевой автопортрет»; показана связь понятий «Коммуникативные навыки» и «Речевой автопортрет». Целью статьи является описание типичных особенностей речи студентов IT-направлений подготовки, выделяемых самими студентами (норма и девиации). В качестве материала для исследования использованы речевые автопортреты студентов. Полученные результаты позволяют выделить блоки речевых особенностей, на которых акцентируют внимание студенты: речевой комфорт; противопоставление описка (опечатка)/орфографическая ошибка; лексические особенности речи. Выполнение данного задания также позволяет формировать у студентов навыки наблюдения за своей речью и анализа своего речевого поведения.
В статье рассматриваются особенности устной и письменной речи студентов как речевых личностей; представлено соотношение понятий «Речевой портрет» и «Речевой автопортрет»; показана связь понятий «Коммуникативные навыки» и «Речевой автопортрет». Целью статьи является описание типичных особенностей речи студентов IT-направлений подготовки, выделяемых самими студентами (норма и девиации). В качестве материала для исследования использованы речевые автопортреты студентов. Полученные результаты позволяют выделить блоки речевых особенностей, на которых акцентируют внимание студенты: речевой комфорт; противопоставление описка (опечатка)/орфографическая ошибка; лексические особенности речи. Выполнение данного задания также позволяет формировать у студентов навыки наблюдения за своей речью и анализа своего речевого поведения.
Литература
1. Атлас новых профессий будущего [Электронный ресурс]. URL: http://atlas100.ru/future/#pens
2. Бреусова Е.И., Руднева О.В. Мнемотехники в развитии орфографической грамотности студентов неязыковых направлений подготовки (на материале описания орфографического портрета первокурсника).
3. Вагапова Н.А., Доломанюк Л.В., Вагапов Г.В. Soft skills как необходимый компонент содержания инженерного образования // Вестник Казанского государственного энергетического университета. 2016. № 4. С. 134-142.
4. Горбунова Н.Л., Улитина С.Г. Речевая личность переводчика в ее отношении к речевым компетенциям в научном дискурсе. Индустрия перевода. 2013. № 1. С. 431-436.
5. Ковчина Н.В., Игнатова В.В., Барановская Л.А., Сапрыгина С.А. Социальное взаимодействие в профессиональной сфере: к вопросу о soft skills. Alma Mater (Вестник Высшей школы). 2017. № 7. С. 44-46.
6. Кондрашова Е.Е. Лексика геймеров. Русская речь. 2013. № 6. С. 55-58.
7. Коренева А.В. Речевой портрет студента-нефилолога. Монография. Мурманск: Мурманский государственный технический университет, 2013. 120 с.
 19 с.
19 с.9. Маркелова Т.В., Петрушина М.В. Языковая личность журналиста и ее речевой портрет. Известия высших учебных заведений. Проблемы полиграфии и издательского дела. 2015. № 4. С. 15-21.
10. Оберемченко Е.Ю. Речевое поведение и личность дипломата в аспекте скрытой прагмалингвистики. Гуманитарные и социальные науки. 2011. № 1. С. 125-132.
11. Селиверстова Л.Н., Ковалев В.Э. Штрихи к речевому портрету современной студентки (на материале текстов эссе). Вестник Таганрогского института управления и экономики. 2019. № 1. С. 128-131.
12. Чернецова Л.В. Инвестиции в «soft skills» — ключ к успеху. Бизнес и стратегии. 2016. № 4. С. 73-78.
13. Шевченко М.С. Роль речевой культуры в развитии языковой личности студента. Мир педагогики и психологии. 2019. № 4. С. 56-63.
14. Azhayev S.A., Ishigov I.A., Tastemirova B.T. The culture of speech in the medical educational system. Bulletin of the National Academy of Sciences of the Republic of Kazakhstan. 2018. № 1. P. 81-85.
15.
 Duskaeva L.R., Konyaeva Yu.M. Types of information portraits in a journalistic discourse. Rupkatha Journal on Interdisciplinary Studies in Humanities. 2017. № 4. P. 131-143.
Duskaeva L.R., Konyaeva Yu.M. Types of information portraits in a journalistic discourse. Rupkatha Journal on Interdisciplinary Studies in Humanities. 2017. № 4. P. 131-143.16. Zyubina I.A., Dzyubenko A.I., Borisenko V.A., Popova O.V., Prokopyev A.I. Implicit linguopragmatic strategies of speech behavior of English-speaking prosecutors. XLinguae. European Scientific Language Journal. 2019. № 4. P. 92-102.
Поступила в редакцию
2020-09-24
Раздел
Лингвистика
Страницы
508-513
Распознавание речи — Извлечение признаков MFCC и PLP | Джонатан Хуи
Машинное обучение ML извлекает функции из необработанных данных и создает плотное представление контента. Это заставляет нас изучать основную информацию без шума, чтобы делать выводы (если это сделано правильно).
Вернемся к распознаванию речи. Наша цель — найти наилучшую последовательность слов, соответствующую звуку, на основе акустической и языковой модели.
Для создания акустической модели наше наблюдение X представлен последовательностью векторов акустических признаков ( x₁, x₂, x₃, … ). В предыдущей статье мы узнали, как люди артикулируют и воспринимают речь. В этой статье мы обсудим, как аудио-функции извлекаются из того, что мы узнали.
Давайте сначала определим некоторые требования для извлечения признаков в ASR (автоматическое распознавание речи). Учитывая аудиосегмент, мы используем скользящее окно шириной 25 мс для извлечения аудиофункций.
Этой ширины в 25 мс достаточно, чтобы мы могли захватить достаточно информации, и все же особенности внутри этого кадра должны оставаться относительно неподвижными. Если мы говорим 3 слова в секунду с 4 телефонами, и каждый телефон будет разделен на 3 этапа, то будет 36 состояний в секунду или 28 мс на состояние. Таким образом, окно 25 мс является правильным.
Источник Контекст очень важен в речи. Произношения изменены в соответствии с артикуляцией до и после телефона. Каждое скользящее окно находится на расстоянии около 10 мс друг от друга, поэтому мы можем зафиксировать динамику между кадрами, чтобы зафиксировать правильный контекст.
Каждое скользящее окно находится на расстоянии около 10 мс друг от друга, поэтому мы можем зафиксировать динамику между кадрами, чтобы зафиксировать правильный контекст.
Высота звука у людей разная. Однако это не имеет большого значения для распознавания того, что он/она сказал. F0 относится к высоте. Он не имеет значения для распознавания речи и должен быть удален. Что более важно, так это форманты F1, F2, F3, … Для тех, у кого есть проблемы с соблюдением этих терминов, мы предлагаем вам сначала прочитать предыдущую статью.
Мы также надеемся, что извлеченные признаки будут устойчивы к тому, кто говорит, и к шуму в окружающей среде. Кроме того, как и любые проблемы ML, мы хотим, чтобы извлеченные функции не зависели от других. Легче разрабатывать модели и обучать эти модели с независимыми функциями.
Одним из популярных методов извлечения аудиофункций является кепстральных коэффициентов Mel-частоты (MFCC), которые имеют 39 функций. Количество функций достаточно мало, чтобы заставить нас изучить информацию об аудио. 12 параметров связаны с амплитудой частот. Он предоставляет нам достаточное количество частотных каналов для анализа звука.
12 параметров связаны с амплитудой частот. Он предоставляет нам достаточное количество частотных каналов для анализа звука.
Ниже приведен процесс извлечения функций MFCC.
Ключевыми задачами являются:
- Снятие возбуждения голосовых связок (F0) — информация о высоте тона.
- Сделать извлеченные элементы независимыми.
- Регулировка того, как люди воспринимают громкость и частоту звука.
- Захват динамики телефонов (контекст).
Давайте рассмотрим каждый шаг по одному.
Аналого-цифровое преобразование
Аналого-цифровое преобразование производит выборку аудиоклипов и оцифровку содержимого, т. е. преобразование аналогового сигнала в дискретное пространство. Часто используется частота дискретизации 8 или 16 кГц.
ИсточникПредыскажение
Предыскажение увеличивает количество энергии в высоких частотах. Для звонких сегментов, таких как гласные, на более низких частотах больше энергии, чем на более высоких частотах. Это называется спектральным наклоном, который связан с голосовой щелью (как голосовые связки воспроизводят звук). Повышение высокочастотной энергии делает информацию в более высоких формантах более доступной для акустической модели. Это повышает точность обнаружения телефона. У людей проблемы со слухом начинаются, когда мы не можем слышать эти высокочастотные звуки. Кроме того, шум имеет высокую частоту. В инженерной сфере мы используем предыскажения, чтобы сделать систему менее восприимчивой к шуму, который появляется в процессе позже. Для некоторых приложений нам просто нужно отменить усиление в конце.
Это называется спектральным наклоном, который связан с голосовой щелью (как голосовые связки воспроизводят звук). Повышение высокочастотной энергии делает информацию в более высоких формантах более доступной для акустической модели. Это повышает точность обнаружения телефона. У людей проблемы со слухом начинаются, когда мы не можем слышать эти высокочастотные звуки. Кроме того, шум имеет высокую частоту. В инженерной сфере мы используем предыскажения, чтобы сделать систему менее восприимчивой к шуму, который появляется в процессе позже. Для некоторых приложений нам просто нужно отменить усиление в конце.
Предыскажение использует фильтр для усиления высоких частот. Ниже приведен сигнал до и после того, как усиливается высокочастотный сигнал.
Джурафски и Мартин, рис. 9.9Работа с окнами
Работа с окнами включает в себя нарезку звуковой волны на скользящие кадры.
Но мы не можем просто отрубить его по краю кадра. Внезапно упавшая амплитуда создаст много шума, который проявится на высоких частотах. Чтобы нарезать звук, амплитуда должна постепенно падать ближе к краю кадра.
Чтобы нарезать звук, амплитуда должна постепенно падать ближе к краю кадра.
Допустим, w — это окно, применяемое к исходному аудиоклипу во временной области.
Несколько альтернатив для w — окно Хэмминга и окно Хэннинга. На следующей диаграмме показано, как синусоидальный сигнал будет отсекаться с помощью этих окон. Как показано, для окна Хэмминга и Ханнинга амплитуда падает ближе к краю. (У окна Хэмминга есть небольшой резкий спад на краю, а у окна Хэннинга — нет.)
Соответствующие уравнения для w :
В правом верхнем углу внизу звуковая волна во временной области. В основном он состоит только из двух частот. Как показано, обрезанный кадр с Хэммингом и Хэннингом лучше сохраняет исходную информацию о частоте с меньшим количеством шума по сравнению с прямоугольным окном.
Источник Вверху справа: сигнал, состоящий из двух частотДискретное преобразование Фурье (ДПФ)
Затем мы применяем ДПФ для извлечения информации в частотной области.
Блок фильтров Mel
Как упоминалось в предыдущей статье, измерения оборудования не совпадают с нашим слуховым восприятием. Для человека воспринимаемая громкость меняется в зависимости от частоты. Кроме того, воспринимаемое разрешение по частоте уменьшается по мере увеличения частоты. то есть люди менее чувствительны к более высоким частотам. Диаграмма слева показывает, как шкала Мела сопоставляет измеренную частоту с той, которую мы воспринимаем в контексте частотного разрешения.
ИсточникВсе эти отображения нелинейны. При извлечении признаков мы применяем треугольные полосовые фильтры, чтобы скрыть информацию о частоте, чтобы имитировать то, что воспринимал человек.
Источник Сначала мы возводим в квадрат результат ДПФ. Это отражает мощность речи на каждой частоте (x[k]²), и мы называем это спектром мощности DFT. Мы применяем эти треугольные банки фильтров в масштабе Мела, чтобы преобразовать его в спектр мощности в масштабе Мела. Выходной сигнал для каждого слота спектра мощности по шкале Мела представляет энергию из ряда частотных диапазонов, которые он охватывает. Это сопоставление называется Mel Binning . Точные уравнения для слота m будут следующими:
Выходной сигнал для каждого слота спектра мощности по шкале Мела представляет энергию из ряда частотных диапазонов, которые он охватывает. Это сопоставление называется Mel Binning . Точные уравнения для слота m будут следующими:
Полоса пропускания Trainangular шире на высоких частотах, чтобы отразить меньшую чувствительность человеческого слуха на высоких частотах. В частности, он линейно расположен ниже 1000 Гц, а затем поворачивается логарифмически.
Все эти усилия направлены на то, чтобы имитировать то, как базилярная мембрана нашего уха воспринимает вибрацию звуков. Базилярная мембрана имеет около 15 000 волос внутри улитки при рождении. На приведенной ниже диаграмме показана частотная характеристика этих волосков. Таким образом, отклик в виде кривой ниже просто аппроксимируется треугольниками в наборе фильтров Mel.
Мы подражаем тому, как наши уши воспринимают звук через эти волоски. Короче говоря, это моделируется треугольными фильтрами с использованием банка фильтров Mel.
Журнал
Группа фильтров Mel выводит спектр мощности. Люди менее чувствительны к небольшим изменениям энергии при высокой энергии, чем к небольшим изменениям при низком уровне энергии. На самом деле оно логарифмическое. Итак, нашим следующим шагом будет вывод журнала из набора фильтров Mel. Это также уменьшает акустические варианты, не значимые для распознавания речи. Далее нам нужно выполнить еще два требования. Во-первых, нам нужно удалить информацию F0 (шаг) и сделать извлеченные функции независимыми от других.
Кепстр — IDFT
Ниже представлена модель воспроизведения речи.
ИсточникНаши артикуляции контролируют форму голосового тракта. Модель источника-фильтра сочетает в себе вибрации, производимые голосовыми связками, с фильтром, созданным нашими артикуляциями. Форма волны голосового источника будет подавляться или усиливаться на разных частотах в зависимости от формы голосового тракта.
Белые грибы trum — это перевернутые первые 4 буквы в слове «спектр». Наш следующий шаг — вычислить Cepstral, который разделяет голосовую щель и фильтр. Диаграмма (а) представляет собой спектр с осью у, являющейся величиной. На диаграмме (b) показан логарифм магнитуды. Присмотритесь, волна колеблется примерно 8 раз между 1000 и 2000. На самом деле она колеблется примерно 8 раз на каждые 1000 единиц. То есть около 125 Гц — источник вибрации голосовых связок.
Наш следующий шаг — вычислить Cepstral, который разделяет голосовую щель и фильтр. Диаграмма (а) представляет собой спектр с осью у, являющейся величиной. На диаграмме (b) показан логарифм магнитуды. Присмотритесь, волна колеблется примерно 8 раз между 1000 и 2000. На самом деле она колеблется примерно 8 раз на каждые 1000 единиц. То есть около 125 Гц — источник вибрации голосовых связок.
Как видно, логарифмический спектр (первая диаграмма ниже) состоит из информации, относящейся к телефону (вторая диаграмма) и высоте тона (третья диаграмма). Пики на второй диаграмме идентифицируют форманты, которые различают телефоны. Но как мы можем их разделить?
ИсточникНапомним, что периоды во временной или частотной области инвертируются после преобразования.
Напомним, что информация основного тона имеет короткие периоды в частотной области. Мы можем применить обратное преобразование Фурье, чтобы отделить информацию о высоте тона от формант. Как показано ниже, информация о высоте тона будет отображаться в середине и справа. Пик в середине на самом деле соответствует F0, а информация о телефоне будет располагаться в крайнем левом углу.
Пик в середине на самом деле соответствует F0, а информация о телефоне будет располагаться в крайнем левом углу.
Вот еще одна визуализация. Сплошная линия на левой диаграмме — это сигнал в частотной области. Он состоит из информации о телефоне, нарисованной пунктирной линией, и информации о высоте тона. После IDFT (обратного дискретного преобразования Фурье) информация основного тона с периодом 1/T преобразуется в пик около T с правой стороны.
ИсточникИтак, для распознавания речи нам нужны только крайние левые коэффициенты, а остальные отбросить. На самом деле MFCC просто принимает первые 12 кепстральных значений. Есть еще одно важное свойство, связанное с этими 12 коэффициентами. Спектр мощности журнала является реальным и симметричным. Его обратное ДПФ эквивалентно дискретному косинусному преобразованию (ДКП).
DCT — ортогональное преобразование. Математически преобразование дает некоррелированные признаки. Следовательно, функции MFCC сильно не связаны между собой. В ML это упрощает моделирование и обучение нашей модели. Если мы моделируем эти параметры с помощью многомерного распределения Гаусса, все недиагональные значения в ковариационной матрице будут равны нулю. Математически выход этого этапа равен
В ML это упрощает моделирование и обучение нашей модели. Если мы моделируем эти параметры с помощью многомерного распределения Гаусса, все недиагональные значения в ковариационной матрице будут равны нулю. Математически выход этого этапа равен
. Ниже представлена визуализация 12 коэффициентов Кепстра.
ИсточникДинамические функции (дельта)
MFCC имеет 39 функций. Дорабатываем 12 и какие остальные. 13-й параметр — это энергия в каждом кадре. Это помогает нам идентифицировать телефоны.
В произношении важны контекст и динамическая информация. Артикуляции, такие как стоп-закрытие и освобождение, можно распознать по формантным переходам. Характеристика изменений функций с течением времени предоставляет контекстную информацию для телефона. Еще 13 значений вычисляют дельта-значения d ( t ) ниже. Он измеряет изменения характеристик от предыдущего кадра к следующему кадру. Это производная первого порядка признаков.
Последние 13 параметров представляют собой динамические изменения d ( t ) от последнего кадра к следующему кадру. Он действует как производная второго порядка от c ( t ).
Он действует как производная второго порядка от c ( t ).
Таким образом, 39 параметров функций MFCC представляют собой 12 кепстровых коэффициентов плюс энергетический член. Затем у нас есть еще 2 набора, соответствующие значениям дельты и двойной дельты.
Нормализация кепстрального среднего и дисперсии
Далее мы можем выполнить нормализацию признаков. Мы нормализуем признаки по их среднему значению и делим на дисперсию. Среднее значение и дисперсия вычисляются со значением признака j по всем кадрам в одном высказывании. Это позволяет нам корректировать значения, чтобы противодействовать вариантам в каждой записи.
Однако, если аудиоклип короткий, это может быть ненадежно. Вместо этого мы можем вычислить средние значения и значения дисперсии на основе говорящих или даже по всему набору обучающих данных. Этот тип нормализации признаков эффективно отменит предварительное выделение, сделанное ранее. Вот как мы извлекаем функции MFCC. И последнее замечание: MFCC не очень устойчив к шуму.
И последнее замечание: MFCC не очень устойчив к шуму.
PLP очень похож на MFCC. Основанный на слуховом восприятии, он использует предыскажение равной громкости и сжатие кубического корня вместо логарифмического сжатия.
ИсточникОн также использует линейную регрессию для окончательной обработки кепстральных коэффициентов. PLP имеет немного лучшую точность и немного лучшую помехоустойчивость. Но также считается, что MFCC — безопасный выбор. На протяжении всей этой серии статей, когда мы говорим, что извлекаем функции MFCC, вместо этого мы можем также извлекать функции PLP.
ML строит модель проблемной области. Для сложных задач это чрезвычайно сложно, и подход обычно очень эвристический. Иногда люди думают, что мы взламываем систему. Методы выделения признаков в этой статье сильно зависят от эмпирических результатов и наблюдений. С введением DL мы можем обучать сложные модели с меньшими усилиями. Однако некоторые из концепций остаются актуальными и важными для распознавания речи DL.
Чтобы углубиться в распознавание речи, нам нужно подробно изучить два алгоритма машинного обучения.
До эры глубокого обучения (DL) для распознавания речи HMM и GMM были двумя обязательными технологиями для распознавания речи…
medium.com
Анализ речевого сигнала
Автоматическое распознавание речи
Самый быстрый словарь в мире | Vocabulary.com
ПЕРЕЙТИ К СОДЕРЖАНИЮ
особенность речи (лингвистика) отличительная характеристика языковой единицы, служащая для отличия ее от других единиц того же рода
фигура речи язык, используемый в небуквальном смысле
право на свободу слова, гарантированное 1-й поправкой к Конституции США
фатическая речь Разговорная речь, используемая не только для передачи информации, но и для общения
дефект речи расстройство устной речи
коэффициент безопасности отношение разрушающего напряжения конструкции к предполагаемому максимальному напряжению при обычном использовании
повторяющийся вид вид глагола, выражающий повторение действия
водопроводный кран кран для забора воды из трубы или бочки
художественный фильм основной фильм в программе кинотеатра
Отец Церкви (христианства) любой из примерно 70 богословов в период со 2-го по 7-й век, чьи сочинения установили и подтвердили официальную церковную доктрину; в Римско-католической церкви некоторые были позже объявлены святыми и стали Учителями Церкви; наиболее известными отцами латинской церкви являются Амвросий, Августин, Григорий Великий и Иероним; среди тех, кто писал на греческом, были Афанасий, Василий, Григорий Назианзин и Иоанн Златоуст
сумах карликовый обыкновенный неядовитый кустарник из восточной части Северной Америки со сложными листьями и зелеными метельчатыми цветками, за которыми следуют красные ягоды
культовая речь политическое ораторское искусство
карликовый молочай европейский прямостоячий или угнетенный однолетний сорный молочай заносной на северо-востоке США
 13″>
13″>часть речи класс слов, отличающийся своей функцией в предложении
 07″>
07″>безликие без отличительных характеристик или признаков
